把一本书做成 AI Skill,保姆级教程全部开源直接抄
- 使用长上下文模型(如Claude Opus 4.8)完整阅读全书,避免逻辑链断裂,是提炼高质量skill的关键
- 六步流程:提取纯文本、喂给AI、按5类提炼、生成skill、自检试调用、多模型PK,全程约45分钟
- 自检步骤不可跳过,能发现触发词过窄等问题,确保skill在实际场景中可被自然召回
- 变现方式:闲鱼低价走量(19.9-29.9元),小红书高价私域(99-199元),卖skill文件+教程而非盗版全文
- 知识复利从“读过多少书”转向“多少书变成可调用的产能”,开源skill可直接复用
先说个实在的:你书架上读过的每一本书,都可能是一个能挂闲鱼、小红书卖钱的 AI skill。我用 Claude Opus 4.8 手把手演示怎么把一本书做成了能随时调用的 skill,闲鱼挂 19.9,小红书客单价搞能挂到 99~199。整套方法 + Prompt + 开源 skill 全给你,小白零基础照着抄,最后还有怎么变现的思考。
目录
- 一、你最大的浪费
- 二、这件事真正的难点
- 三、准备工作(5 分钟,只做一次)
- 四、六步把书变成 skill(Prompt 直接抄)
- 五、《非暴力沟通》做成 skills 的复盘
- 六、怎么把这个 skill 变成钱
- 七、最后想说的
一、你最大的浪费
做 AI 博主这这段时间,我读的书、看的方法论不算少,但是慢慢发现一件扎心的事——
读过,不等于用得上。
我想大家肯定也有过这个场景:一本书当时读得热血沸腾,划满了线,笔记记进了 Notion,结果三个月后真要写篇东西、做个决策,脑子里一片空白,那本书像没读过一样。
说白了,大多数人的读书,都只是在囤积,没有真正做到知识的调用。
那能不能让 AI 把书里的方法论,变成一个我随时能喊出来用的工具?
趁着周末折腾出了一个开源 skill——把任意一本书,提炼成一个能被 AI 调用的 skill。不是读后感,也不是摘要,是一个真正实用的工具箱:书里的框架、原则、技法、反模式,全部变成 AI 能照着执行的指令。
二、这件事真正的难点
这件事真正的难点不在书内容的提炼,关键是怎么让 AI 读全。
一本书几万字,得让 AI 把整本的逻辑链一次吃进去,而不是切成碎片各读各的。
因为一旦书的逻辑链被切碎,跨章节的因果也就断了,提炼出来的框架基本都是残的。
所以 AI 大模型一定要用最顶的,我用的是 Claude Opus 4.8。
它三个能力刚好卡这个任务的命:
- 长上下文:100 万 token 的上下文窗口,整本书一次读完,不切块、不丢逻辑
- 结构化输出:直接吐出规整的 skill 文件,不用手动排版
- 多步 agentic:生成完自己做一遍自检和试调用,发现哪里空洞再回去补
三、准备工作(5 分钟,只做一次)
第 0 步|把 Opus 4.8 接进 Cursor
配置看起来有点技术感,但其实就这几步,做过一次永远不用再碰:
① 在后台生成你的 API Key,拿到一串密钥,复制好,别外泄。
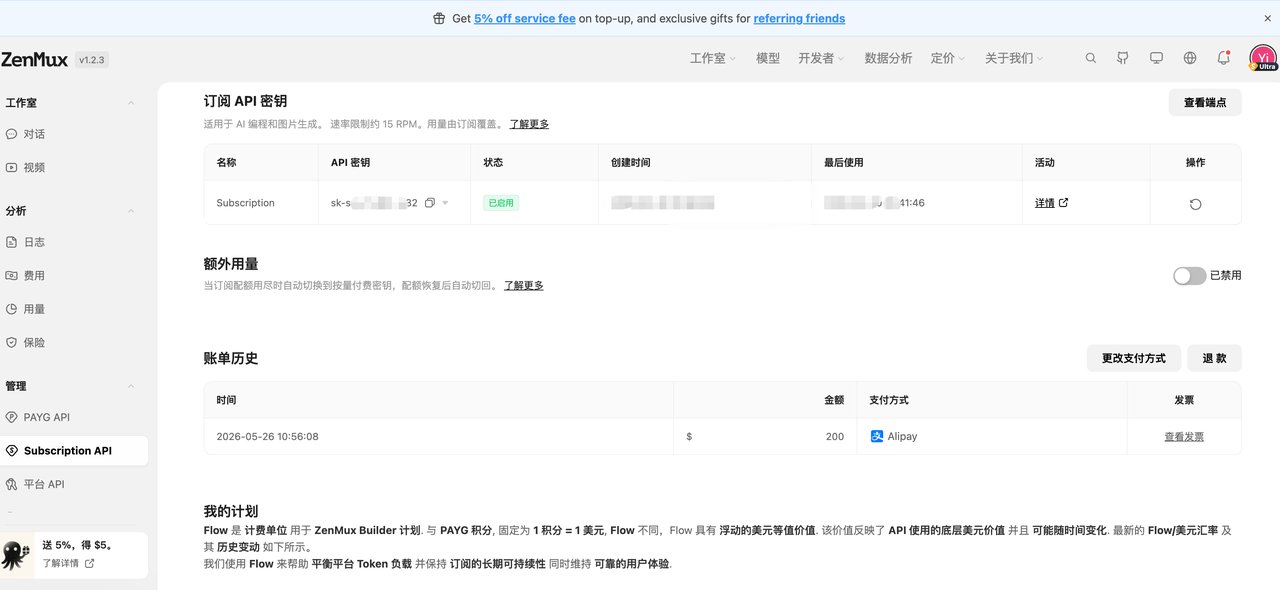
② 选一个计费方式
- 订阅制(Builder 计划)→ 用量可预测,固定月费,适合经常用的人
- 按量付费(Pay As You Go)→ 偶尔用、用量不稳定时选这个,充值还有 +10% 积分
③ 打开 Cursor,进 Settings → Models,做三件事:
第一,打开「Override OpenAI Base URL」的开关,填入你的 API 地址。
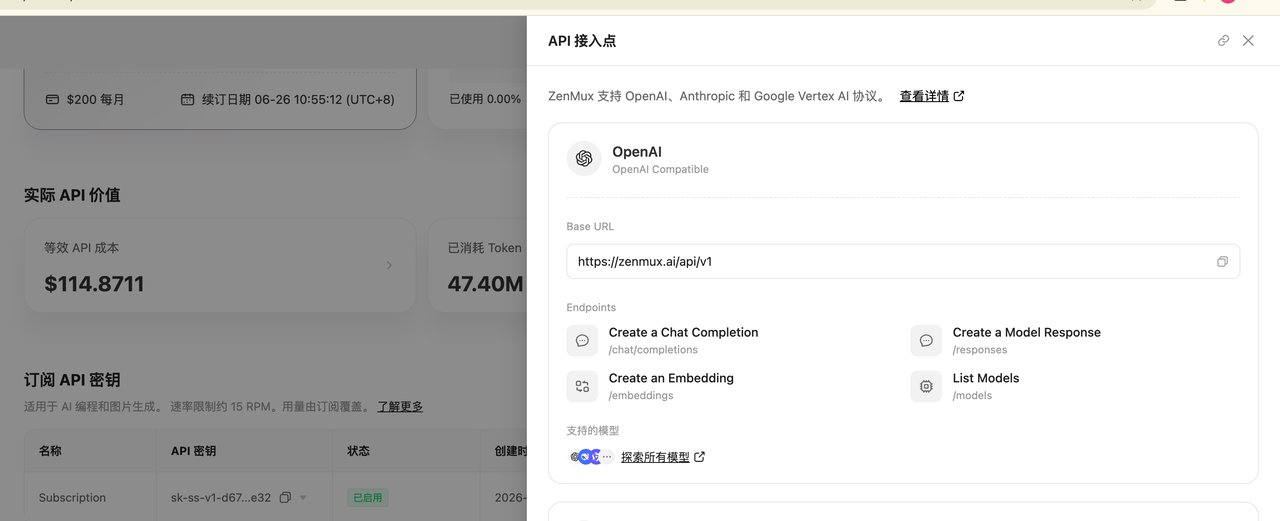
第二,在对应 API Key 栏填入你的密钥。
第三,「Anthropic API Key」那栏留空。这个很关键——填了的话,所有 claude- 开头的模型都会被 Cursor 劫持,打到官方而不是你配置的代理,直接报错。
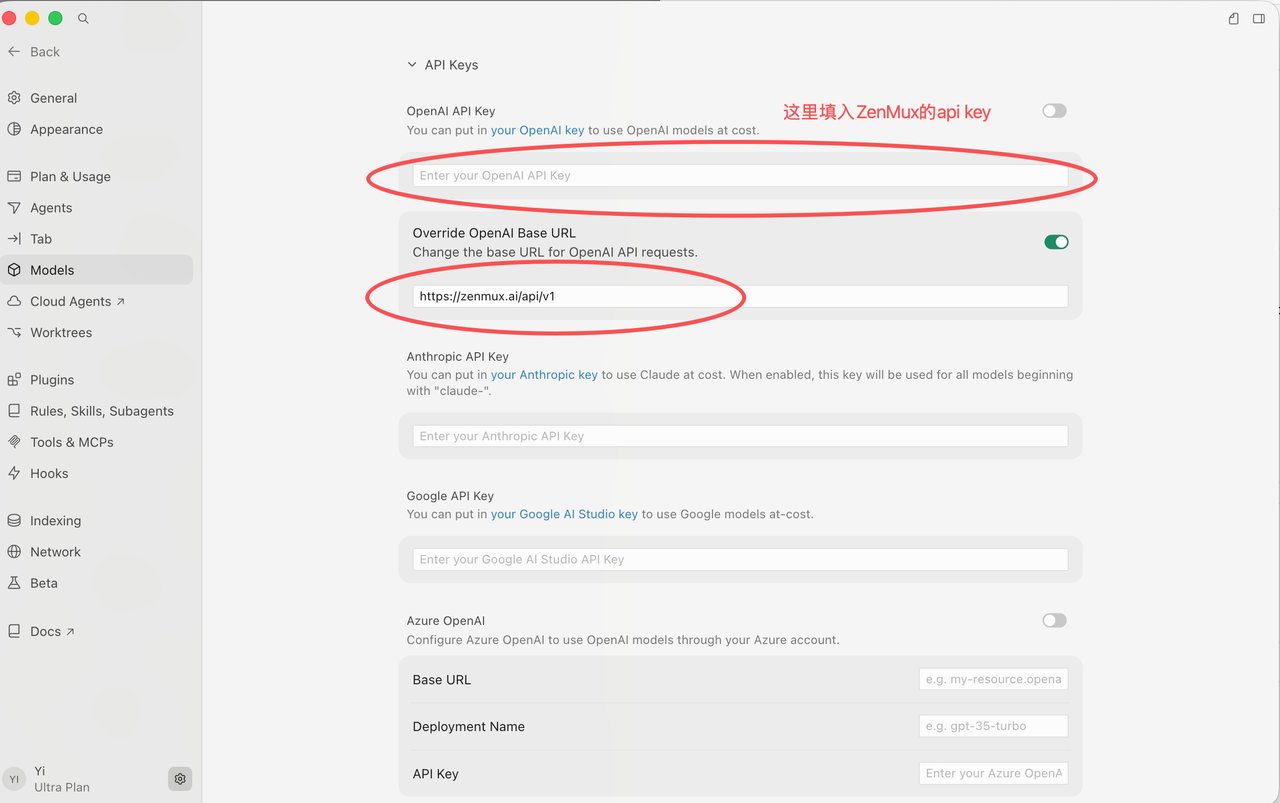
④ 点「+ Add model」,填这个模型名:anthropic/claude-opus-4.8
注意一定要带 anthropic/ 前缀,不能填 claude-opus-4-8——后者以 claude- 开头,会走错通道。
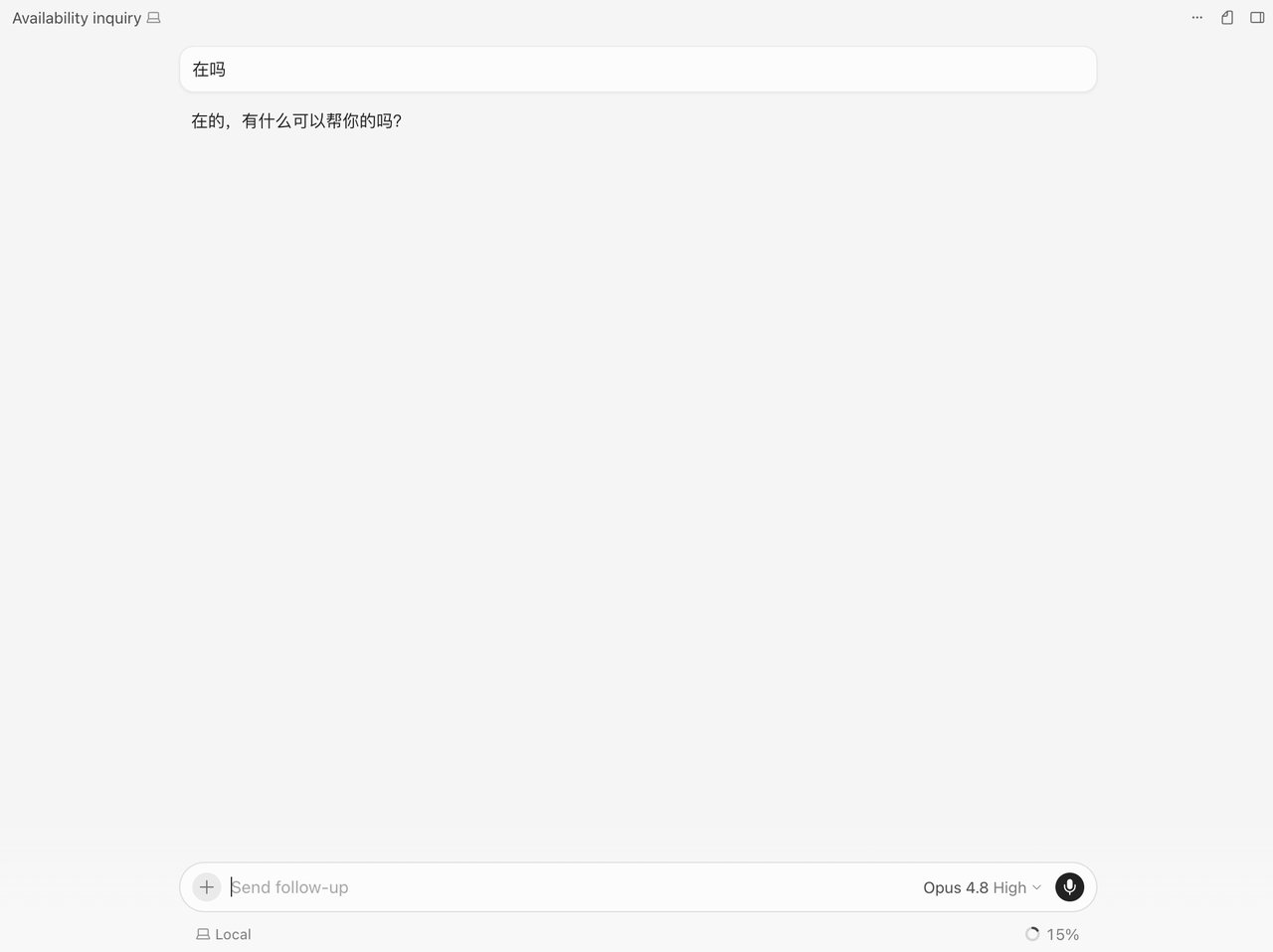
⑤ 新开对话,选中这个模型,发句「在吗」,能回 = 通了。
四、六步把书变成 skill
第一步|把书变成一段纯文字
目标:拿到这本书干净的纯文本(.txt 或 .md),图表排版丢了没关系,文字逻辑在就行。
按你手上的格式,三选一:
情况 A · 已经是 Word / 网页文章 Word 里点文件 → 另存为 → 格式选「纯文本(.txt)」即可;网页文章就全选复制,粘进记事本存成 .txt。
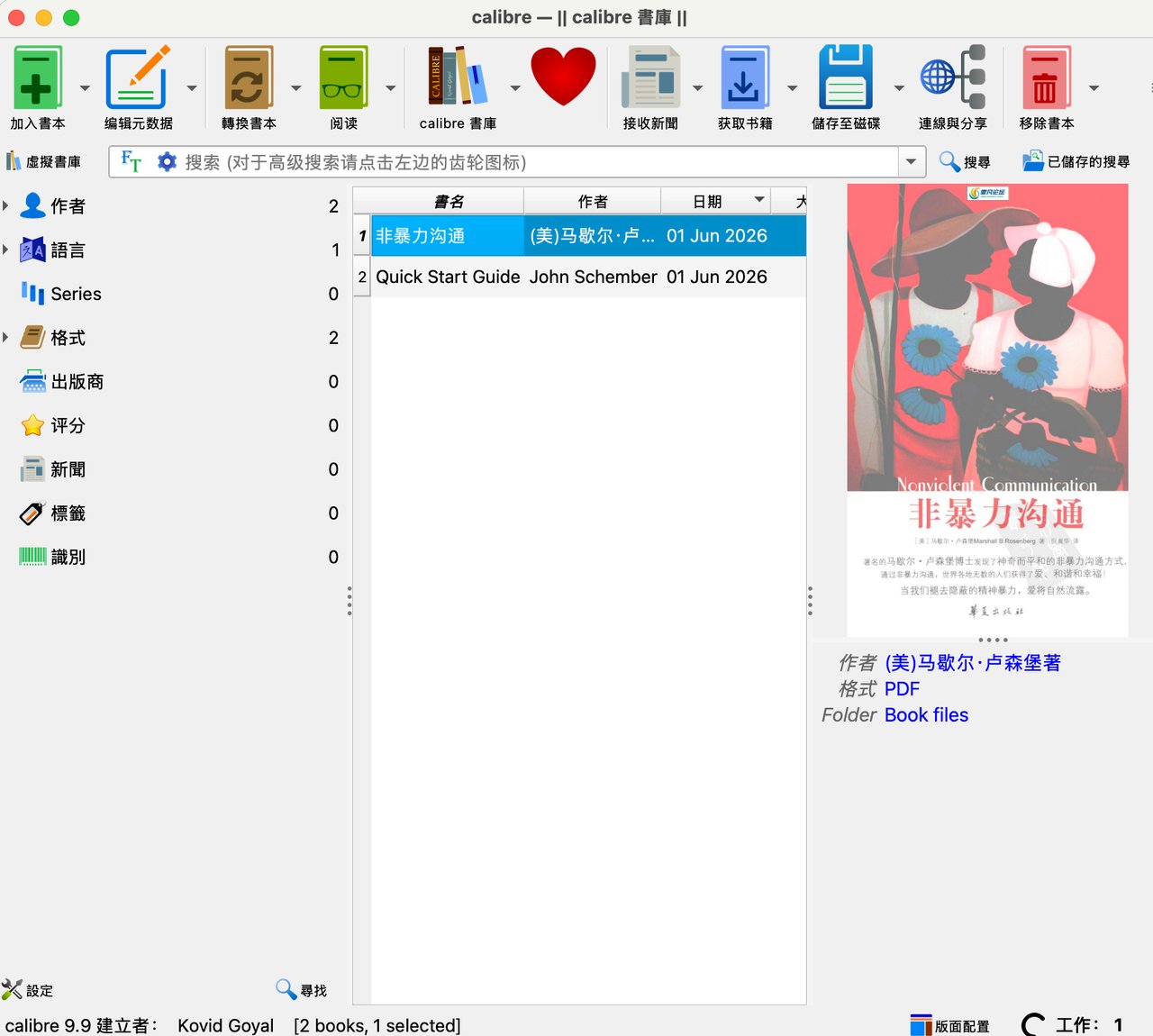
情况 B · 是 PDF 或 EPUB(推荐小白走这条) 用 Calibre(完全免费,calibre-ebook.com):
- 下载安装
- 把电子书文件拖进去
- 选中这本书,点上方「转换书籍」
- 右上角「输出格式」选 TXT,右下角点确定
- 转换完点「点击查看」,找到 .txt 文件
这里有个坑我替你踩过了——很多看起来免费的在线转换工具,下载时会要你订阅付费,还自动续费。我被套路过一次,最后用的还是 Calibre,完全免费,稳得多。
情况 C · 实在啥都不想装 搜「epub 转 txt 在线」,上传、选输出格式、下载即可。但注意别用要付费的那种,也别把有版权或隐私内容的书传到不可信的网站。
⚠️ 关键:要的是整本干净文字,别先让任何工具帮你摘要再喂——摘要会把框架精度丢光。
第二步|把整本丢给 Opus 4.8,先别让它摘要
怎么喂:客户端支持上传文件就直接拖 .txt;不支持上传就分几段把全文粘贴进去。
然后发提示词(直接抄,方括号换成你的):
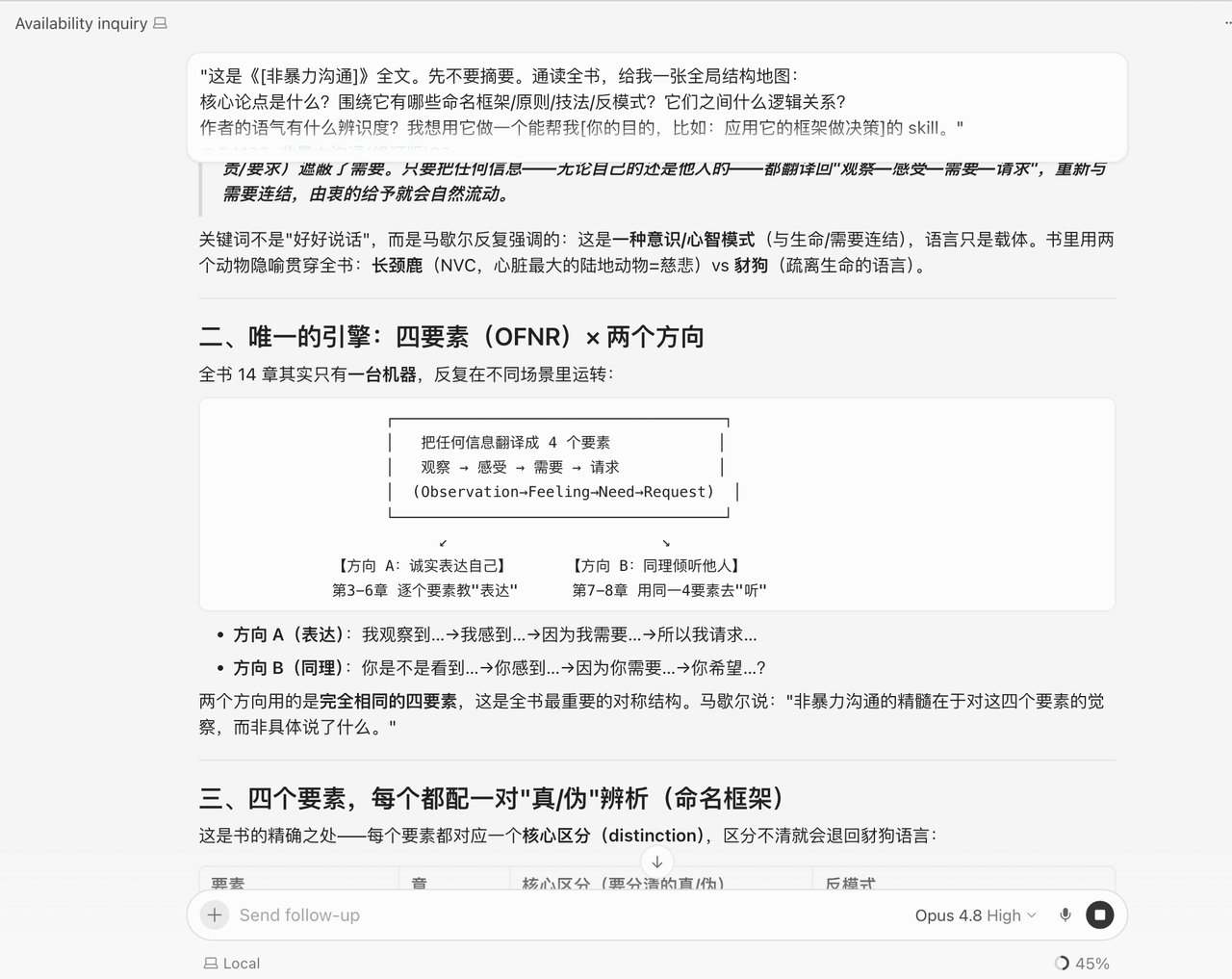
第三步|按 5 类提炼,做一张台账
接着发:

第四步|生成 skill(这步决定它好不好用)
先判断:这本书框架少(1-3 个)就做成一个文件;框架多(10+ 个)就做成「入口文件 + 分文件懒加载」。
然后发:
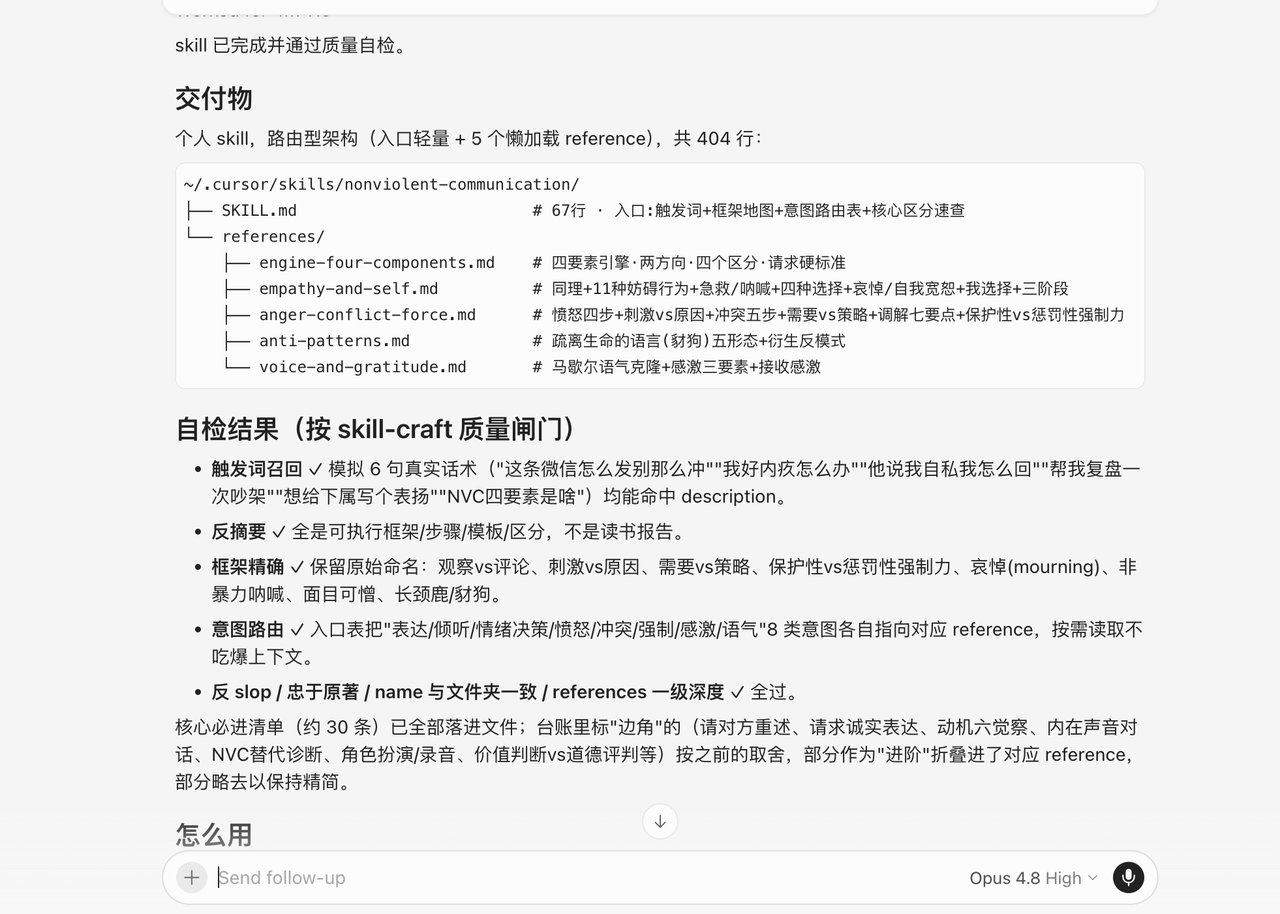
第五步|自检 + 试调用(最容易被跳过,但不能省)
第一次跑的时候我也跳了这步,结果发现这个 skill 完全召不回来,才明白有多关键。
让它自己验两件事,发现问题就回上一步补:
① 召回测试
② 调用测试
现在真用这个 skill 完成一个任务:[一个这本书能解决的真实问题] 看你给的是能照做的步骤,还是空话。
第六步(可选,但很爽)|让几个模型 PK 一下
同一份台账,丢给 Opus 4.8 和另外一两个模型各生成一版,对比谁提炼得更准、触发词更全。
五、拿《非暴力沟通》跑测 skills 的复盘
选这本是因为它框架特别清晰——马歇尔·卢森堡的《非暴力沟通》,一本讲怎么好好说话的经典。
框架越清晰的书,越适合做这个测试。
全程时间:第一次从零开始,包括配置 + 跑完六步,前后大概 45 分钟,熟悉之后换一本书重跑,估计 20 分钟内能搞定。
实际成本:Opus 4.8 的价格是输入 $5/百万 token,输出 $25/百万 token。整本书加上来回几轮对话,总共消耗约 30 万 token,折合下来整个流程花了不到二十块钱人民币。
生成的 skill 什么样:Opus 4.8 把这本书提炼成了一套能直接调用的工具,而且保留了书里的原始命名——「非暴力沟通四要素(观察·感受·需要·请求,OFNR)」、「长颈鹿语言 vs 豺狗语言」这个动物隐喻、「疏离生命的语言」这几类沟通陷阱,全都没被改写成通用说法。
更关键的是,它把“要好好说话”这种正确的废话,变成了“先说你观察到的事实、别评判,再说你的感受,再讲你的需要,最后提一个具体的请求”这种我能照着做的四步。
第五步的自检没省,也确实抓到了问题:它第一版的触发词写窄了,我说「非暴力沟通」才召得回,但现实里我根本不会这么说话——我会说「怎么提意见不像在指责」「和家里人又吵起来了怎么办」。我把这些更日常的说法补进去,它才真的能在我需要的时候自己冒出来。这一步多花了十分钟,但没做等于白做。
最让我感受到这东西真有用的一刻:生成完这两天,我和家人有句话憋着不知道怎么开口,就是那种一说出来容易变味、听着像指责的事。我顺手喊了下这个 skill,它直接用 OFNR 四步把我想说的话拆开重排了一遍——先讲我观察到什么,再讲我的真实感受,把那些「你总是」「你又」的词全换掉了。
那一刻我突然反应过来:这本我几年前读过、早就还给作者的书,第一次真的回到了我手边帮我干活,而不是躺在书架上积灰。
六、怎么把这个 skill 变成钱
做完 skill 只是第一步,怎么变现我也说透:
- 卖给谁:想要某本书方法论、但懒得自己折腾的人;想学做 skill 的新手
- 挂哪 + 定价:闲鱼走量,单个 19.9
29.9,标题写「XX 书 AI skill + 安装教程」;小红书做图文引流(“我把 XX 书变成了 AI 助手”),私域成交,客单价 99199 - 卖什么形态:skill 文件 + 保姆级安装教程,进阶可加「指定书代做」服务
- 一条红线:卖你提炼的 skill 和教程/服务,别卖书的盗版全文——咱是卖你的作品,不是倒卖书
七、最后想说的
就这一道工序,已经改变了我对读书这件事的看法。
以前我衡量自己读了多少本书。现在我衡量的是——我有多少本书,已经变成了 AI 随时能调用的能力。
知识最大的浪费,从来不是没读过,是读过了,却一直躺在收藏夹里当库存。
而真正的护城河,也正在从「你读过多少书」,变成「你能把多少书,变成自己随时调得动的产能」。
读完一本书就让它睡进 Notion,和读完就把它焊成一个能干活的 skill,是两种完全不同的复利。
整套 skill 我开源了,拿走直接用:
https://github.com/ayi-ai/ayi-nonviolent-communication
跑通了欢迎评论区告诉我你把哪本书变成了 skill,我们一起迭代下一版。

评论互动