写代码前必须掌握的 10 个 AI 核心概念
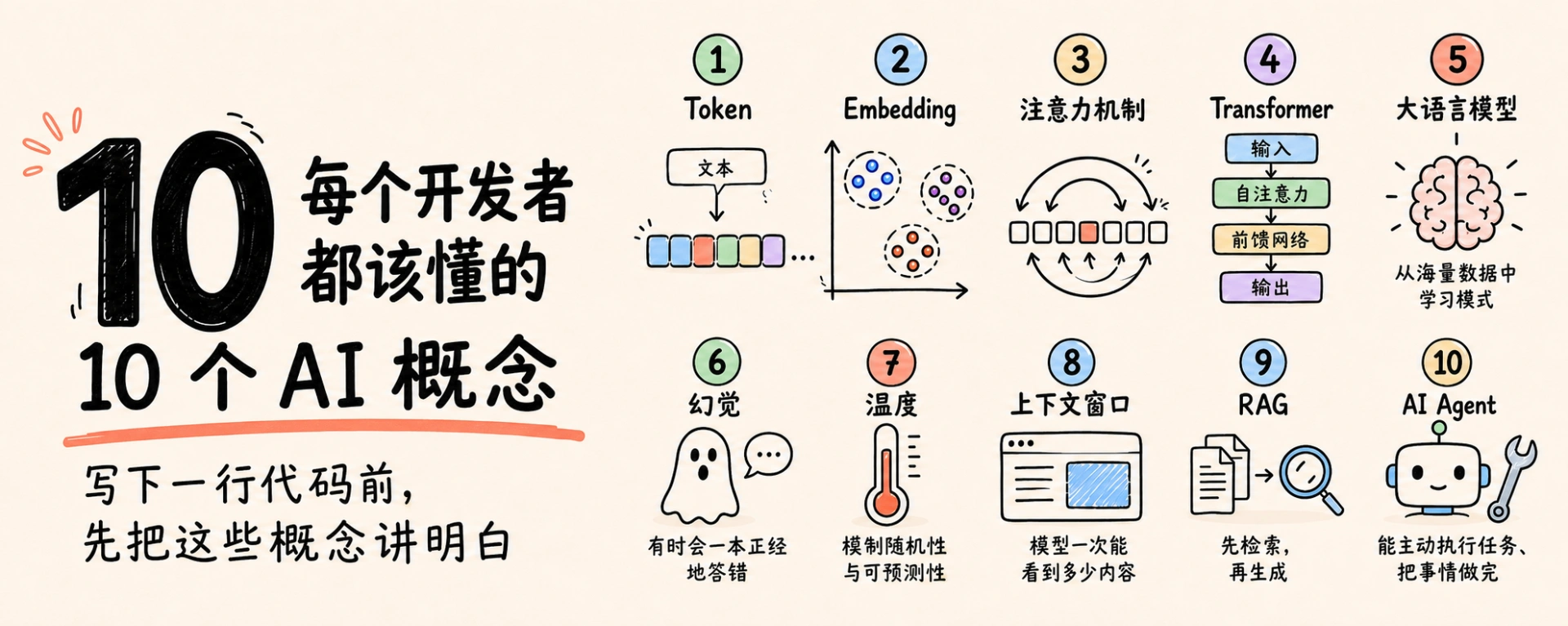
- Token作为AI计费、限流和衡量单位,理解它可解释prompt截断和API账单
- Embedding将文本转为语义向量,驱动语义搜索、推荐和RAG系统
- Attention机制让模型动态关联上下文,决定词语含义
- RAG通过检索增强生成,让模型基于真实数据回答,减少幻觉
- AI Agent通过循环使用工具完成目标,可靠性是核心挑战
原文链接:10 AI Concepts Every Builder Must Understand Before Writing a Single Line of Code
大多数 AI 教程从代码开始。
它们跳过了真正重要的部分——概念。
于是你做了一个半吊子的聊天机器人。你不知道它为什么会产生幻觉(Hallucination),你不知道上下文窗口(Context Window)到底意味着什么,你不知道为什么 RAG 系统总是返回错误的文档。
你在盲目调试。
以下是每个开发者在写第一行代码前必须理解的 10 个 AI 概念。
不需要博士学位,没有专业术语。
只有让一切豁然开朗的心智模型。
收藏这篇,它能帮你省下几周的弯路。
1. Token — AI 真正读取的单位
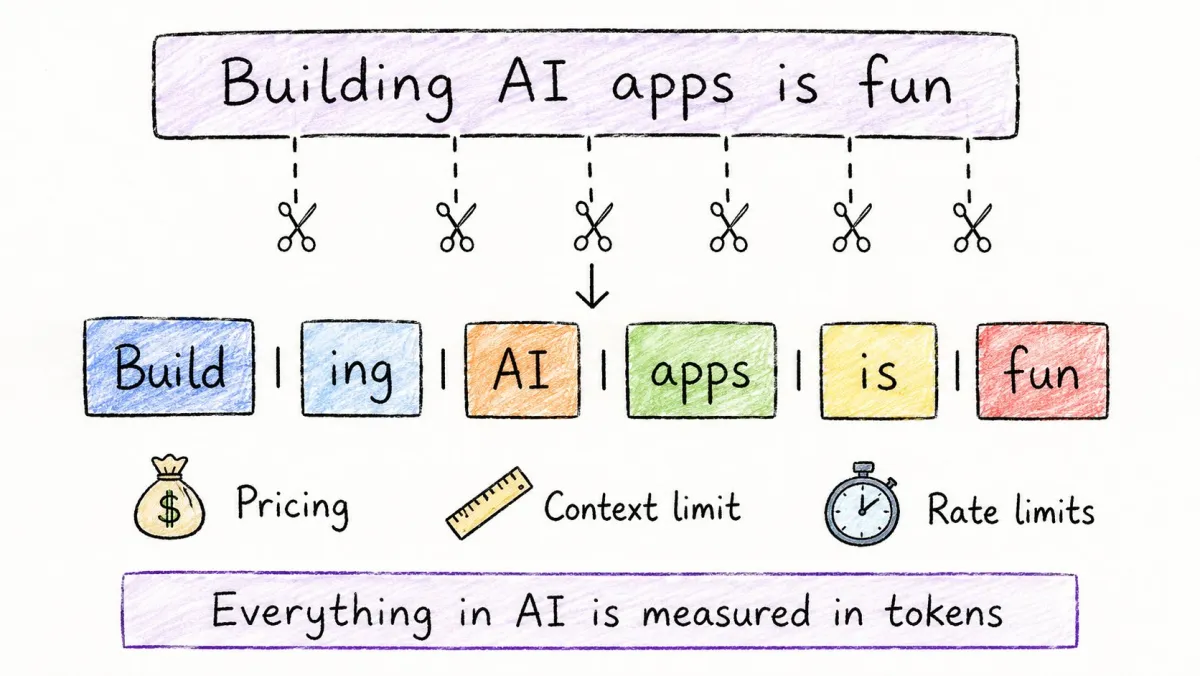
你写了一句话,模型看到的不是一句话。
它看到的是 Token。
Token 是一小段文本。
→ 有时是一个完整的词:“build” → 1 个 Token
→ 有时是词的一部分:“building” → “build” + “ing” → 2 个 Token
→ 有时是标点符号:“.” → 1 个 Token
“Building AI apps is fun” → 6 个 Token
为什么这对开发者很重要:
AI 中的一切都以 Token 来计费、限流和衡量。
→ API 费用 = 每 1,000 个 Token 的价格 → 上下文窗口 = 单次请求的最大 Token 数 → 速率限制 = 每分钟 Token 数
理解了 Token,你就不再困惑于:为什么 prompt 被截断、为什么 API 账单比预期高、为什么模型“忘记”了你之前说的话。
经验法则:1,000 个 Token ≈ 750 个英文单词(中文约 500 字)。
2. Embedding — AI 如何理解语义
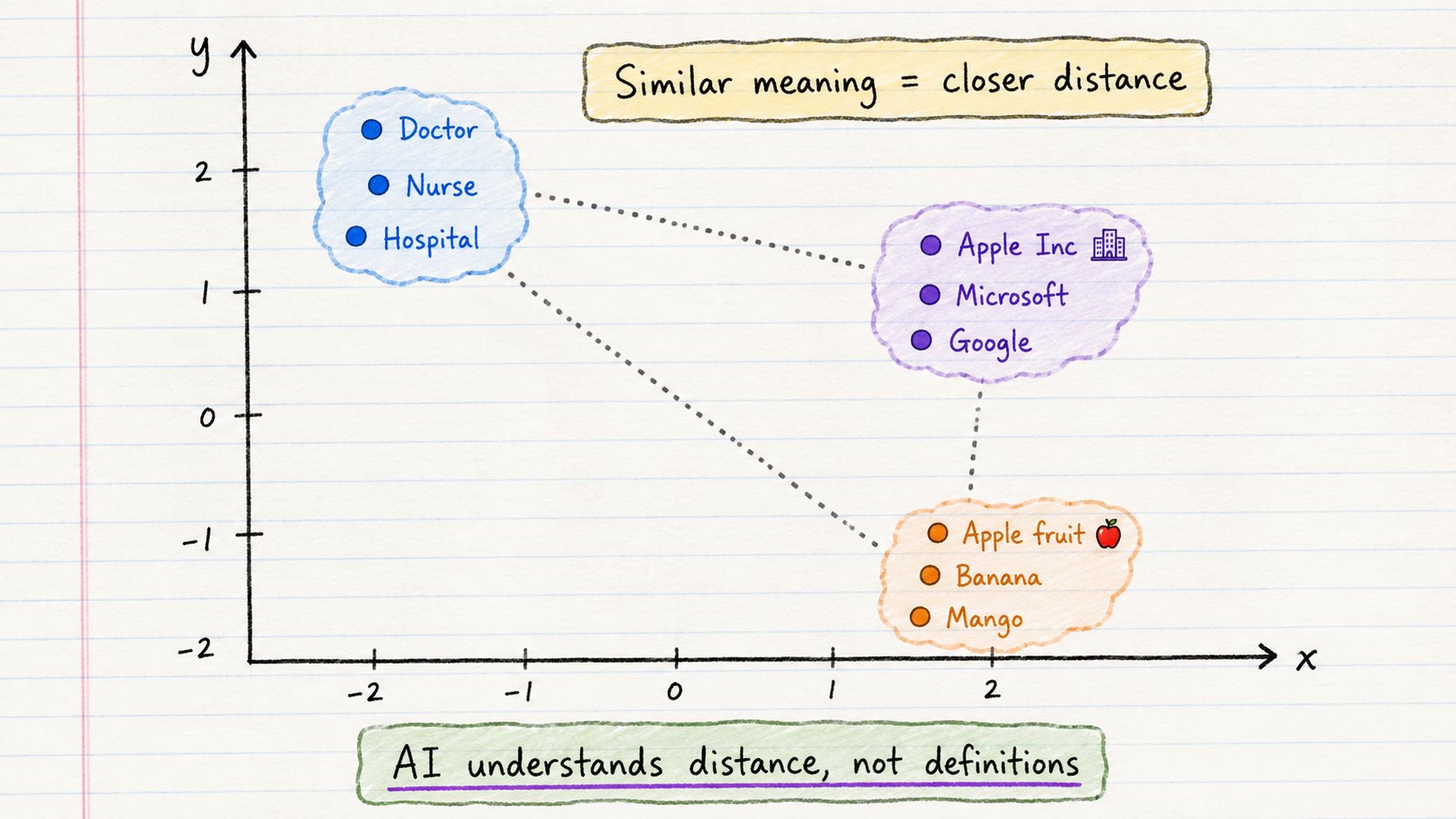
文本变成 Token 后,下一步是变成数字。
这些数字叫做 Embedding(嵌入向量)。
每个词、句子或文档都会被转换为一个向量——一长串数字,代表它的语义。
关键洞察:语义相似 = 数字相似 = 在空间中距离接近。
→ “医生” 和 “护士” 靠得很近 → “苹果(水果)” 和 “苹果(公司)” 相距很远 → “国王” - “男人” + “女人” ≈ “女王”
AI 不是用你的方式理解语义的,它理解的是距离。
为什么这对开发者很重要:
Embedding 驱动了一切“理解意图”的功能:
→ 语义搜索(按含义搜索,而非仅匹配关键词) → 推荐系统(相似内容推荐) → RAG 系统(找到相关文档) → PDF 对话(将问题匹配到正确的页面)
如果你的搜索结果不对,Embedding 模型通常是首先要检查的地方。
3. Attention — AI 如何理解上下文
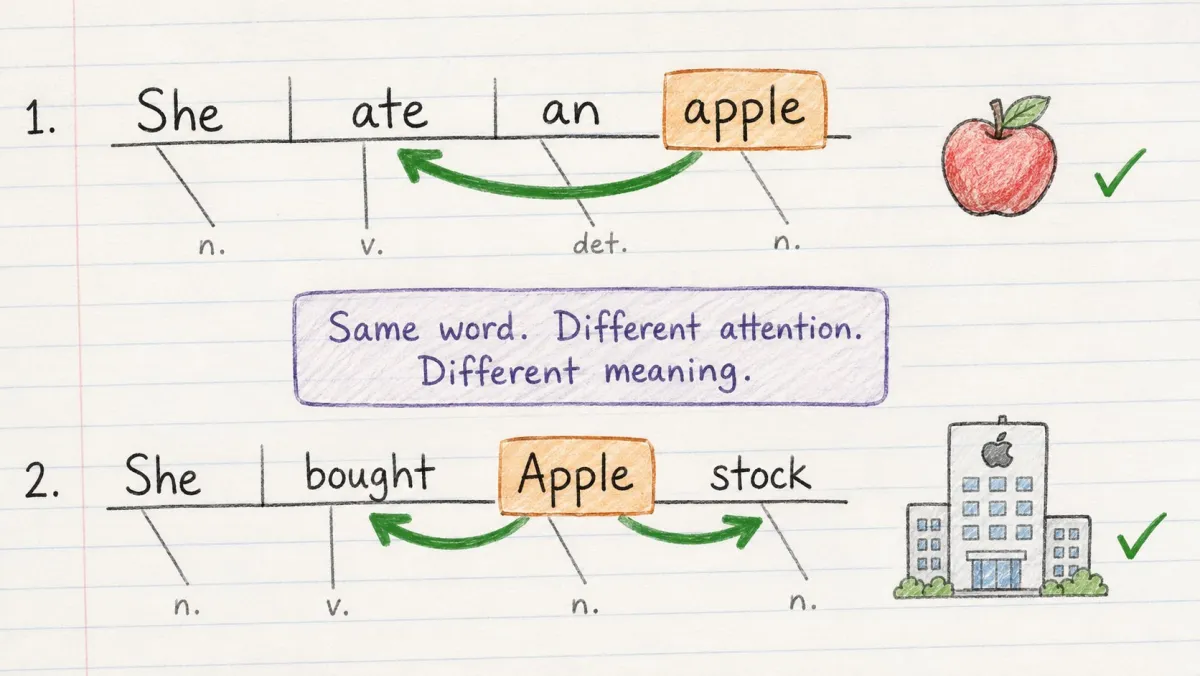
同一个词,完全不同的含义。
→ “她吃了一个苹果” → 水果 → “她买了苹果股票” → 公司
模型怎么知道是哪一个?靠 Attention(注意力机制)。
Attention 让每个词都能“看到”句子中的所有其他词,并决定哪些最重要。
它不是从左到右依次阅读,而是一次性看到整个句子,动态建立关联。
在“她买了苹果股票”中:→ “苹果” 对 “买了” 和 “股票” 付了高注意力 → 模型判断:公司
在“她吃了一个苹果”中:→ “苹果” 对 “吃了” 付了高注意力 → 模型判断:水果
在 Attention 出现之前,模型逐词阅读,速度慢,容易遗漏远距离关联。
有了 Attention,模型可以一次看到全部内容。
这个单一想法,就是现代 AI 之所以有效的原因。
为什么这对开发者很重要:
理解 Attention 可以解释:为什么上下文清晰时模型处理长 prompt 更好、为什么歧义 prompt 会产生不一致的输出、为什么给 prompt 添加上下文能显著改善结果。
4. Transformer — 驱动一切的引擎
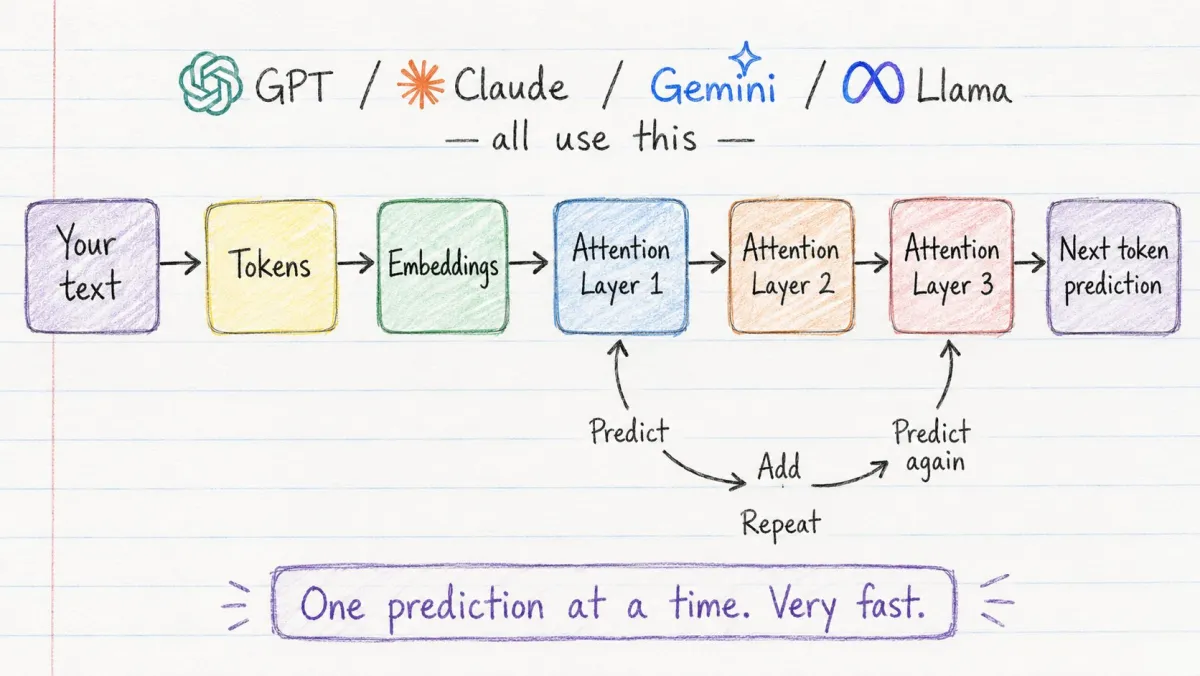
GPT、Claude、Gemini、Llama、Mistral——全部都是 Transformer。
Transformer 是你将要使用的每一个现代 AI 模型背后的架构。
它的工作流程很简单:
文本 → Token → Embedding → Attention 层 → 预测
模型不是一次性生成完整句子的。它每次预测一个 Token。
→ 预测下一个 Token → 将其加入序列 → 再次预测下一个 Token → 循环往复
这个循环——每秒运行数十亿次——就是产生你看到的文本的过程。
为什么这对开发者很重要:
理解 Transformer 流水线可以解释:
→ 为什么更长的输出需要更长时间(更多预测循环) → 为什么模型是“非确定性”的(每一步都有概率分布) → 为什么前面的 Token 会影响后面的 → 为什么在思考中间截断上下文会降低输出质量
你不需要构建 Transformer,你需要理解你调用的那个“黑盒”里面发生了什么。
5. LLM — 它们到底是什么
LLM 是在海量文本上训练的 Transformer,只做一件事:预测下一个 Token。
仅此而已。
训练数据:书籍、网站、代码、Wikipedia、Reddit、文档。数万亿个 Token。
训练任务听起来简单到无法解释这些模型的能力:
→ 看到文本 → 预测接下来是什么 → 检查是否正确 → 微调权重 → 重复数万亿次
结果是:一个深度学习人类语言模式的模型,能够写代码、推理问题、翻译语言、解释复杂概念。
这些都不是显式编程的。它们从规模的 next-token 预测中涌现而来。
开发者需要理解的最重要的一点:
LLM 不是数据库。它们不会查找答案。它们基于模式预测答案。
这个区别解释了一切——包括为什么它们会产生幻觉。
6. Hallucination — 为什么 AI 会自信地说谎
这在生产环境中一定会发生。
用户问你的 AI 应用一个问题,AI 给出了自信的、结构完整的、完全错误的答案。
这就是幻觉(Hallucination)。
原因如下:
模型不是在尝试告诉你真相。它在尝试预测概率最大的下一个 Token。
如果一个错误的陈述看起来像是基于训练模式“应该出现的内容”——它就会生成出来。没有验证,没有查找,纯粹的模式补全。
它会:
→ 引用不存在的论文 → 描述从未创建过的 API 函数 → 以十足的自信陈述虚假统计数据 → 编造听起来合理但错误的代码
危险在于:它从来不会听起来犹豫不决。
作为开发者,你应该怎么做:
→ 使用 RAG(获取真实数据,不依赖记忆) → 在向用户展示输出前添加验证层 → 使用工具调用(让模型去验证,而非猜测) → 生产环境中永远不要直接使用原始 LLM 输出作为事实
理解幻觉,是将发布安全 AI 产品的开发者和发布令人尴尬的 AI 产品的开发者区分开来的关键。
7. Temperature — 创造力旋钮
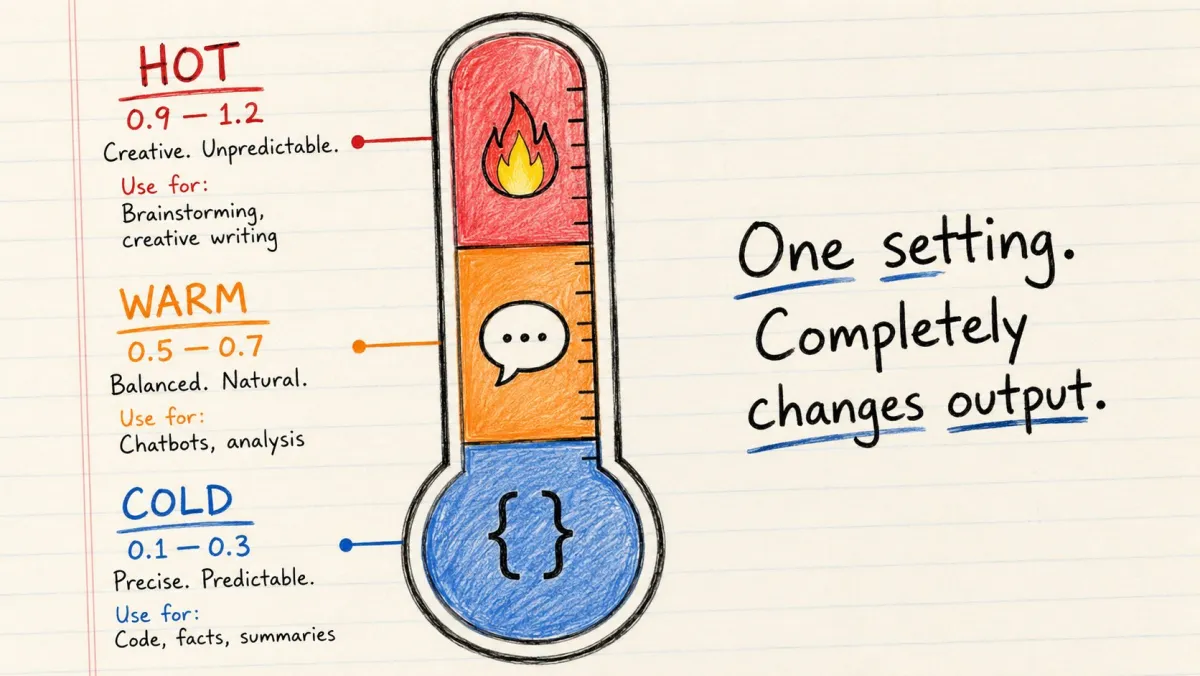
AI 每次生成一个 Token 时,都会为每个可能的下一个词计算概率。
Temperature 控制接下来发生什么。
→ 低 Temperature:几乎总是选择概率最大的 Token。安全、可预测。 → 高 Temperature:更随机地从概率分布中选择。有创造力、多样化。
实用设置指南:
| 用途 | Temperature |
|---|---|
| 写代码 | 0.1–0.2 |
| 事实问答 | 0.2–0.3 |
| 摘要总结 | 0.3–0.5 |
| 聊天回复 | 0.5–0.7 |
| 创意写作 | 0.8–1.0 |
| 头脑风暴 | 1.0+ |
大多数初学者的错误:所有场景都使用默认 Temperature(通常 0.7–1.0),然后纳闷为什么编程助手写出了有创意但有 bug 的代码。
Temperature 只需一行代码。请有意识地设置它。
8. Context Window — AI 的工作记忆
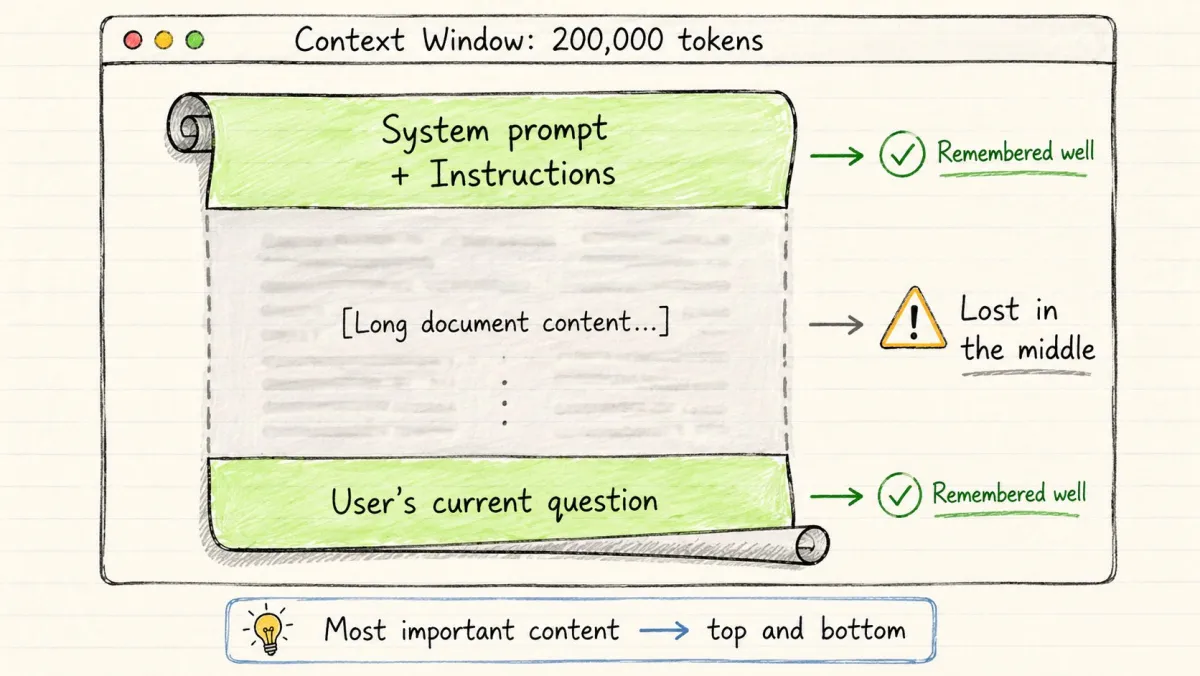
每个 AI 模型一次只能“看到”固定数量的文本。
这个限制就是上下文窗口(Context Window)。
它包含单次请求中的所有内容:
→ 系统提示词 → 对话历史 → 你传入的文档 → 模型自己的回复 → 你当前的消息
所有这些加在一起必须塞进窗口内。
当前限制:
→ GPT-4o:128,000 Token → Claude 3.5 Sonnet:200,000 Token → Gemini 1.5 Pro:1,000,000 Token
更大听起来更好,但有一个问题。
模型不会均匀地阅读上下文。它们对开头和结尾给予更多注意力。中间部分?经常被忽略。
这被称为“Lost in the Middle”问题。
对开发者来说这意味着:
→ 把最重要的指令放在系统提示词的最前面 → 把最重要的上下文放在用户问题之前 → 不要假设模型“看到了”你包含的内容 → 长文档应该分块和摘要,而非整段塞入
上下文管理是 AI 工程中最重要的技能之一。
9. RAG — AI 如何使用你的数据
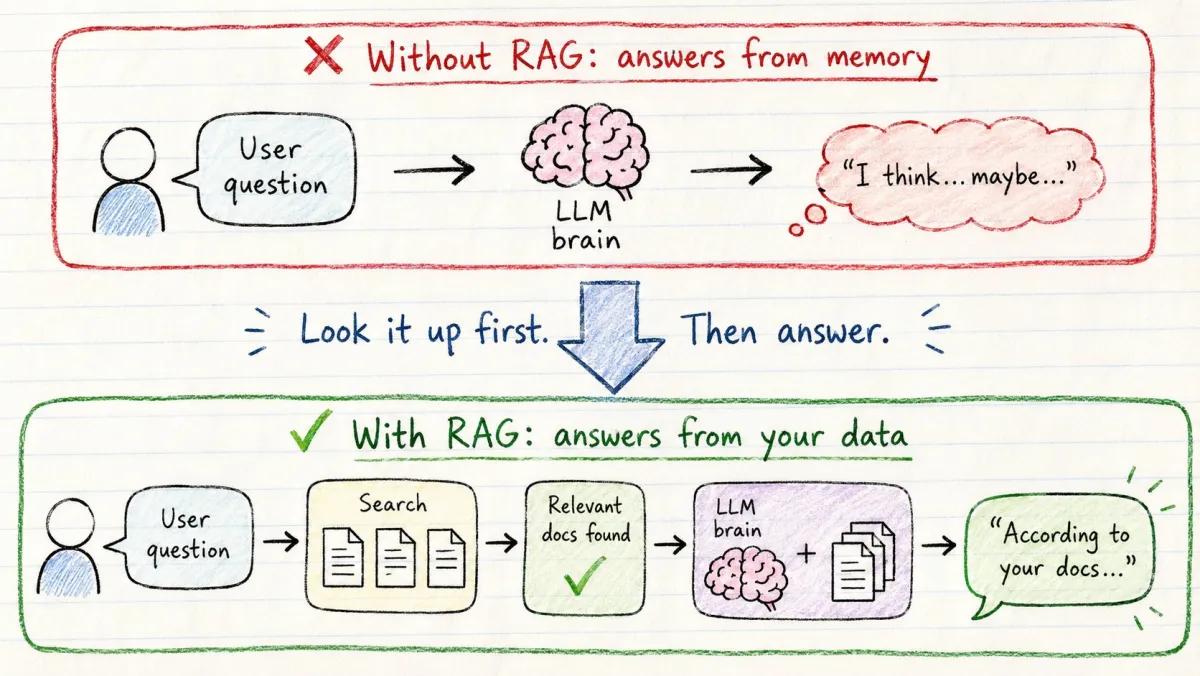
LLM 的训练数据有截止日期。
它们不知道:你公司的内部文档、上周的新闻、你的产品文档、你的用户数据。
RAG 解决了这个问题。
RAG = 检索增强生成(Retrieval-Augmented Generation)
模型不再依赖记忆回答,而是先搜索知识库,然后用搜索到的内容来回答。
每个开发者都需要了解的流程:
- 用户提问
- 问题 → Embedding → 搜索向量数据库
- 检索最相关的文档
- 文档 + 问题一起发给模型
- 模型基于真实、具体的数据回答
为什么 RAG 在大多数场景下优于微调:
→ 数据变了?只需更新文档,无需重新训练 → 需要来源引用?文档就在那里 → 大幅减少幻觉 → 适用于不应进入训练的私有数据
你使用的每一个严肃 AI 产品背后都有 RAG。客服机器人、文档助手、法律工具、内部知识库。
如果你今年只学一个架构模式,学 RAG。
10. AI Agent — 真正能做事的 AI
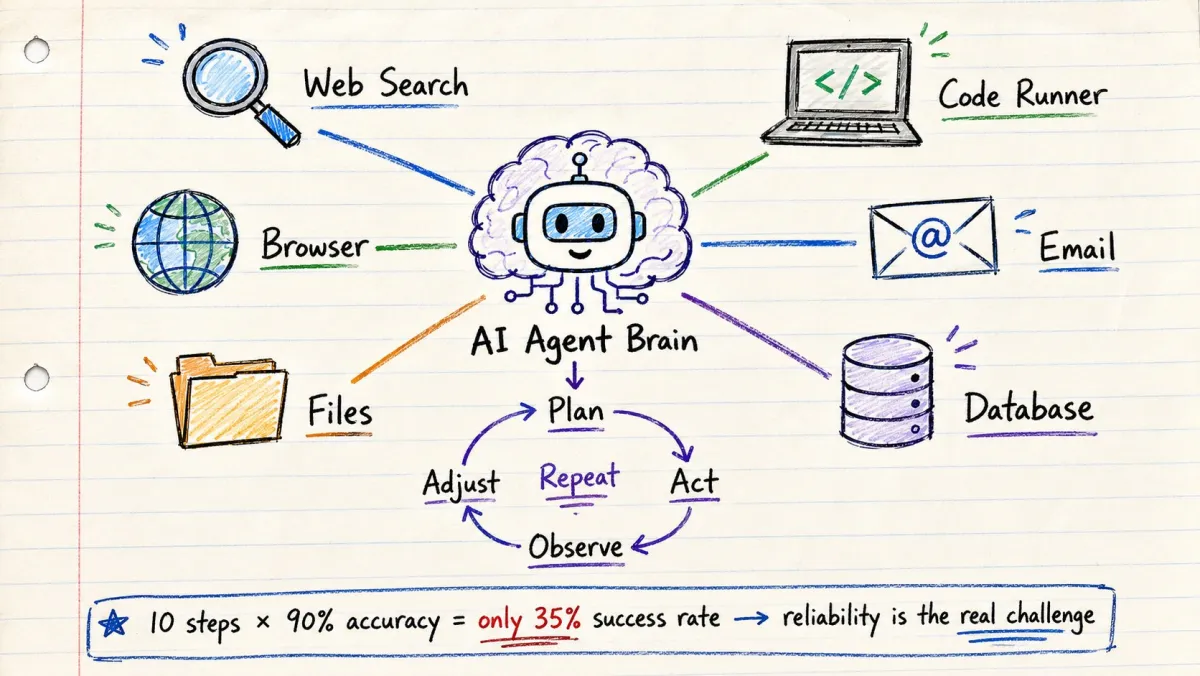
标准 LLM:→ 你提问。它回答。结束。
AI Agent:→ 你给一个目标。它规划。它使用工具。它检查结果。它调整。它完成。
区别在于一个循环。
Agent 循环:
- 理解目标
- 决定下一步做什么
- 使用工具去执行
- 检查结果
- 决定下一步
- 重复直到完成
Agent 可以使用哪些工具?
→ 网页搜索 → 代码执行 → 文件读写 → API 调用 → 数据库查询 → 邮件和日历 → 浏览器控制
实际案例——调试 Agent:
读取错误 → 搜索代码库找到相关文件 → 定位问题 → 编写修复 → 运行测试 → 发现 2 个测试仍然失败 → 读取失败的测试 → 调整修复 → 再次运行 → 全部通过 → 完成
模型是大脑,工具是双手。
Agent 对开发者的挑战:
每一步都有失败率。三步各 90% 准确率 = 72.9% 的任务完成率。十步 = 34.8%。
这就是为什么可靠性工程才是 Agent 的真正挑战——而不是构建 Agent 本身。
学习顺序
如果你从零开始,这是最佳学习顺序:
→ 1. Token(理解度量单位) → 2. Embedding(理解语义如何变成数字) → 3. Attention(理解上下文如何工作) → 4. Transformer(理解架构) → 5. LLM(将一切串联起来) → 6. Hallucination(理解核心失败模式) → 7. Temperature(学会控制输出风格) → 8. Context Window(学会管理记忆) → 9. RAG(学会使用自己的数据) → 10. Agent(学会构建能行动的系统)
这不是 10 个随机知识点,而是一个完整的 AI 工程心智模型。
一旦你理解了全部 10 个概念,AI 就不再是魔法。它变成了工程。
而这,就是你真正开始构建可用之物的时刻。

评论互动