GLM-5.1-HighSpeed:400 tokens/s 刷新全球大模型 API 速度上限
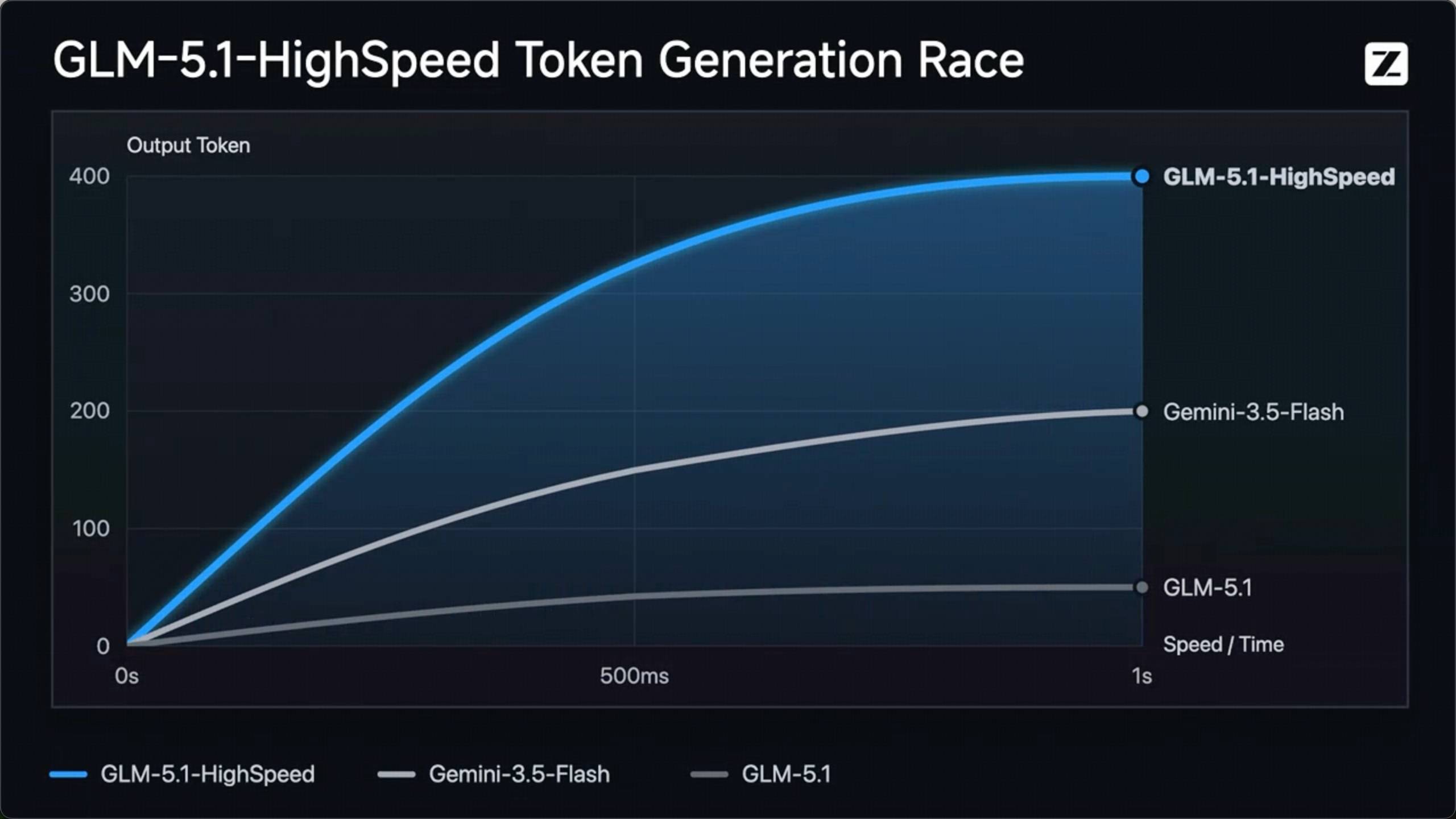
- 输出速度达到400 tokens/s,刷新全球大模型API速度上限
- 通过推理引擎、调度系统与基础设施三层系统级优化实现高速
- 支持200K上下文窗口和128K最大输出Tokens
- 适用于AI编程、实时交互、商业决策、实时语音等低延迟场景
- 提供思考模式、流式输出、Function Call、MCP等多种能力
原文链接:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.1-highspeed
概览
GLM-5.1-HighSpeed 是智谱旗舰模型 GLM-5.1 的高速版本。通过在推理引擎、调度系统与底层基础设施三个层面的系统级优化,模型输出速度达到 400 tokens/s,刷新当前全球大模型厂商 API 的速度上限。同时,这也是国产大模型首次将旗舰级能力与极低延迟同时带入生产环境,打破了响应速度与模型质量不可兼得的局限。
GLM-5.1-HighSpeed 模型目前仅面向智谱 BigModel 开放平台部分企业客户定向开放。
模型规格
| 项目 | 规格 |
|---|---|
| 定位 | 高速旗舰模型 |
| 输入模态 | 文本 |
| 输出模态 | 文本 |
| 上下文窗口 | 200K |
| 最大输出 Tokens | 128K |
能力支持
| 能力 | 说明 |
|---|---|
| 思考模式 | 提供多种思考模式,覆盖不同任务需求 |
| 流式输出 | 支持实时流式响应,提升用户交互体验 |
| Function Call | 强大的工具调用能力,支持多种外部工具集成 |
| 上下文缓存 | 智能缓存机制,优化长对话性能 |
| 结构化输出 | 支持 JSON 等结构化格式输出,便于系统集成 |
| MCP | 可灵活调用外部 MCP 工具与数据源,扩展应用场景 |
推荐场景
1. AI 编程
面向 Coding Agent、多轮代码生成与大型工程重构场景,显著降低长链路任务等待时间,实现代码、接口与调用链的实时生成与协同修改。
2. 实时交互
支持游戏生成、实时 UI 构建与动态内容反馈等低延迟交互场景,让模型能够随用户输入即时响应并持续改变系统状态与界面。
3. 商业决策
适用于实时数据分析、运营问答与多 Agent 并行推演等场景,可快速完成信息汇总、策略生成与多维度方案比对,提升决策效率。
4. 实时语音
在语音助手、实时客服与 AI 陪练等场景中,可在语音识别与合成链路中快速完成理解与回复生成,带来更加自然流畅的实时交互体验。
调用示例
cURL 基础调用
curl -X POST "https://open.bigmodel.cn/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-5.1-highspeed",
"messages": [
{
"role": "user",
"content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"
},
{
"role": "assistant",
"content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"
},
{
"role": "user",
"content": "智谱AI 开放平台"
}
],
"thinking": {
"type": "enabled"
},
"max_tokens": 65536,
"temperature": 1.0
}'Python SDK 调用
from zai import ZhipuAiClient
client = ZhipuAiClient(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-5.1-highspeed",
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"},
{"role": "assistant", "content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱开放平台"}
],
thinking={
"type": "enabled",
},
max_tokens=65536,
temperature=1.0
)
print(response.choices[0].message)Python SDK 流式调用
from zai import ZhipuAiClient
client = ZhipuAiClient(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-5.1-highspeed",
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"},
{"role": "assistant", "content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱开放平台"}
],
thinking={
"type": "enabled",
},
stream=True,
max_tokens=65536,
temperature=1.0
)
for chunk in response:
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end='', flush=True)
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end='', flush=True)Java SDK 调用
ZhipuAiClient client = ZhipuAiClient.builder().ofZHIPU()
.apiKey("your-api-key")
.build();
ChatCompletionCreateParams request = ChatCompletionCreateParams.builder()
.model("glm-5.1-highspeed")
.messages(Arrays.asList(
ChatMessage.builder()
.role(ChatMessageRole.USER.value())
.content("作为一名营销专家,请为我的产品创作一个吸引人的口号")
.build(),
ChatMessage.builder()
.role(ChatMessageRole.ASSISTANT.value())
.content("当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息")
.build(),
ChatMessage.builder()
.role(ChatMessageRole.USER.value())
.content("智谱开放平台")
.build()
))
.thinking(ChatThinking.builder().type("enabled").build())
.maxTokens(65536)
.temperature(1.0f)
.build();
ChatCompletionResponse response = client.chat().createChatCompletion(request);
评论互动