现场直击 Google I/O 2026:Gemini 3.5 Flash、Spark、Omni 三剑齐发

兄弟们,也是出息了,被 Google 邀请参加 Google I/O 26 开发者大会
第一次现场参加 Google I/O 大会 ,感受很不一样…
视频号 小互:Google I/O 2026.. 进场了,有点意思… 老外就是很松弛的感觉…[旺柴]
说实话,整场发布会信息量非常大,模型、搜索、视频生成、办公、购物、开发工具、AI Agent,一个接一个往外抛。
如果只看产品清单,很容易觉得这是一次“Google 全家桶更新”…
但坐在现场听完整场之后,我最大的感受是:
Google 正在把 Gemini 从一个会回答问题的 AI,升级成一套能理解、能创作、能执行、还能持续跟进任务的 AI 系统。

本次大会其实主要核心更新是三个:
Gemini 3.5 Flash,行动大脑 Gemini Spark,个人 Agent 入口 Gemini Omni,多模态创作出口
Gemini 3.5 Flash:新一代基础模型,Flash 级速度跑出旗舰级智能,今天起成为 Gemini App 和 Google 搜索 AI Mode 的全球默认模型。
Gemini Spark:跑在 Google 云端的 24/7 个人 AI Agent,你关掉电脑它还在替你处理邮件、读账单、整理会议记录。
Gemini Omni:从任意输入生成视频的多模态模型,把“剪视频”变成“跟 AI 聊天”,会替代原来的 Veo。
Google I/O 2026 完整中英文双语视频:
1.Gemini 3.5 Flash:Flash 反超 Pro 转向为“执行”
先说 Gemini 3.5 Flash。
很多人一看到 Flash,会第一时间想到“快”。这次确实还是快,但 Google 想讲的重点已经更进一步:它要成为 Agent 的执行大脑。
要看懂这次 Flash 的份量,先理解一个背景:
过去这两年,所有 AI 公司基本都是同一个套路:每家都同时出两个版本的模型。
一个是旗舰版:OpenAI 的 GPT-5、Anthropic 的 Claude Opus、Google 的 Gemini Pro。能力强、价格贵、回复慢,适合处理复杂任务。
一个是轻量版:GPT-5 mini、Claude Haiku、Gemini Flash。能力弱一些,但便宜、快,适合日常对话和大批量处理。
用户和企业的选择策略也很简单:能用轻量版就用轻量版,省钱省时间;非要用旗舰版的难题,咬咬牙也得用。
这次 Google 把这个分层打破了。
新发的 Gemini 3.5 Flash(轻量版),在好几项关键跑分上反超了今年 2 月才发的 Gemini 3.1 Pro(上一代旗舰版)。

简单说:旗舰版的能力,被装进了轻量版的速度和价格里。
它面向智能体和编程任务,强调复杂、长周期、能真正产生实用价值的任务处理能力。
今天开始,它可以在 Gemini App、Google Search 的 AI Mode、Google Antigravity、Google AI Studio、Android Studio、Gemini Enterprise 等场景里使用。
也就是说,它不是只给你写一段回答。
它可以帮你规划步骤、调用工具、生成代码、做 UI、处理文件,还能在更长时间里持续推进一个复杂任务。
Gemini 3.5 Flash 被 Google 称为其目前能力最强的智能体与编程模型,在 Terminal Bench 2.1 上达到 76.2%,GDPval AA 为 1656 Elo,MCP Atlas 为 83.6%,CharXiv Reasoning 达到 84.2%。
速度方面,Flash 每秒生成约 289 个 token(一个 token 大致相当于半个汉字或一个英文单词),是其他前沿模型的 4 倍。
价格大约是其他前沿模型的一半。
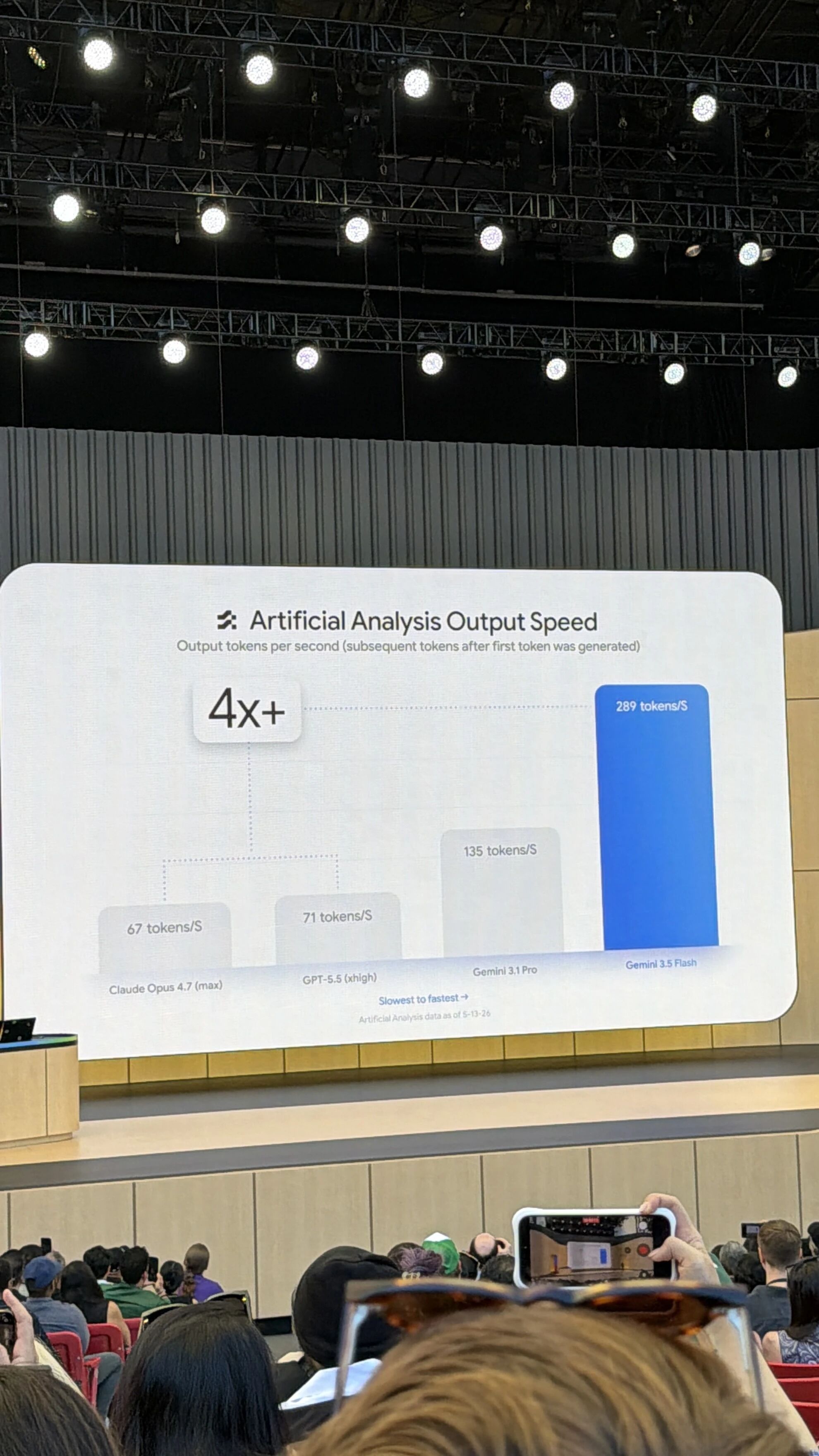
这件事对不同人的意义:
如果你是普通用户,从今天起,Gemini 网页版和 Google 搜索的 AI 模式背后默认跑的就是 3.5 Flash。你不用切换、不用选模型,体验自动升级。
如果你是开发者或者公司技术决策者,过去要花旗舰版的钱才能跑的工作流,现在用 Flash 就够了。账单砍一半,响应速度还快 4 倍。这种成本变化,长期来看比“模型变聪明了”本身影响更大。
Google 举了很多例子:开发新应用、维护代码库、协助准备财务文件、自动分类非结构化资产、生成交互式网页 UI、甚至用多个智能体一起做游戏和迁移遗留代码库。特别是在 Google Antigravity 里,3.5 Flash 可以部署协作子智能体,让多个 Agent 分工完成多步骤工作流。
这里其实是今天最重要的变化之一:
AI 正在从“单个模型回答问题”,变成“多个智能体一起完成任务”。
一个 Agent 负责规划,一个 Agent 负责执行,一个 Agent 负责检查结果。对开发者来说,这就很像把一个想法交给一个小型 AI 团队。
所以 Gemini 3.5 Flash 的意义,不在于又多了一个快模型。它更像是 Google 给整个 Gemini 生态换上的新发动机。
一批合作伙伴案例,证明 3.5 Flash 不是 demo,是真的在干活:
Shopify(全球最大独立电商平台):用 Flash 同时跑多个 AI 分析数据,预测哪些商家会爆发增长。
Macquarie 银行(澳洲老牌银行):用 Flash 读 100 多页的开户文件,帮客户加快开户。
Salesforce(企业服务巨头):把 Flash 接进自家 AI 助手 Agentforce,让 AI 帮企业自动完成多步任务。
Ramp(公司支出管理):用 Flash 做发票识别,比传统 OCR(光学字符识别)聪明很多。
Xero(小企业会计软件):让 AI 帮小企业主自动整理税表和供应商资料。
Databricks(数据分析平台):用 AI 跨海量数据集做实时诊断。
最有画面感的演示:在 Google 自家的开发平台 Antigravity 上,两个 AI agent 分工协作,一个负责“造游戏”,另一个负责“试玩并提改进建议”。两个 AI 互相反馈 6 小时,先把 AlphaZero 这篇硬核学术论文消化掉,再写出了一个真正能玩的小游戏。
这种活以前给一个工程师做,得花一两周
至于真正的下一代旗舰 Gemini 3.5 Pro?Google 只说了一句“已经在内部用了,下个月发”。
2. Gemini Spark:Google 把个人 Agent 推到台前
如果说 Gemini 3.5 Flash 是大脑,那 Gemini Spark 就是这个大脑进入普通人生活的入口。
Google 把 Spark 定义为 24 小时运行的个人 AI Agent。它基于 Gemini 3.5 Flash 构建,可以在用户指导下代表用户采取行动,帮助处理数字生活里的任务。

这东西听起来有点抽象…
换个说法就是:运行在云端的个人龙虾(openclaw)
Spark 运行在 Gemini 3.5 上,使用 Antigravity harness,并且和 Gmail、Docs、Slides 等 Workspace 工具深度集成。因为它是云端 Agent,所以哪怕你合上电脑、锁上手机,它也可以在后台继续工作。
你交代一件事,它自己拆步骤、调工具、跨好几个应用一直干,干完才回来跟你说“搞定了”。
中间你不用陪着…
举个具体例子。你跟 Spark 说一句:
“每个月帮我看一遍信用卡账单,找出有没有奇怪的扣款。”
Spark 会自己:
1.设个每月提醒,到日子自动去你 Gmail 里翻信用卡邮件。2.一项项分析每笔支出。3.找出“你可能忘了取消的订阅”、“金额突然变高的扣款”、“陌生商户”。4.整理一份月度报告发到你邮箱。
整个过程你完全不需要在场。你甚至可以忘了你交代过这件事,下个月报告自动出现。
Spark 最关键的设计:跑在云端,不依赖你的设备
这是 Spark 跟市面上其他 AI Agent 工具(OpenClaw、Hermes 这些)最大的区别。
那些工具是“本地代理”,装在你电脑上,要你保持电脑开着、配好环境、装好命令行工具,普通人光是装环境就劝退了。
Spark 不用。它跑在 Google 的服务器上。你交代完任务就可以合上 MacBook 出门吃饭、睡觉、甚至换电脑。第二天打开邮箱,活已经干完了。
Spark 现在能干什么 Spark 出厂就接好了 Google 自家的 Workspace 全家桶:Gmail、Google Docs、Google Slides,能直接读写。
第三方应用接了三个:Canva(设计工具)、OpenTable(订餐厅)、Instacart(在线买菜)。Google 用的是 MCP 协议(一个让 AI 跨应用工作的开放标准),未来接入更多第三方应该会比较快。
价格和时间表 Spark 本周开始小范围内测(仅限受邀用户),下周向美国的 Google AI Ultra 订阅用户开放 beta(公测)。
为了配合 Spark 推广,Google 顺手做了一件事:Google AI Ultra 订阅价从 250 美元 / 月降到 200 美元 / 月。
今年夏天 Spark 还会加几个能力:
直接通过短信、邮件跟 Spark 沟通(不用打开 Gemini App)
让 Spark 创建“子 Agent”(一个 Agent 拆出几个 Agent 同时干活)
让 Spark 操作你本地电脑的浏览器(替你在网页上点按钮、填表单)
Mac 桌面版(能读你本地文件,不仅是云端)
这件事真正重要在哪
普通聊天机器人更像“临时问答窗口”。
Spark 更像“长期任务管家”。
它说明 Google 已经不满足于让 Gemini 做“回答问题的工具”。
它想让 Gemini 进入你的日程、邮箱、文档、购物和搜索,成为一个能持续替你推进事情的个人系统。

Google 跑在云端这个决定,不只是技术选择,是入口选择。
Gemini App 现在每个月有 9 亿人在用。Spark 一上线,这 9 亿人理论上明天就都能变成“AI Agent 用户”,不用装软件、不用懂技术、不用懂什么是 MCP。OpenAI 和 Anthropic 现在最缺的不是模型能力,是这种“用户已经在那里”的入口。
3.Gemini Omni:视频创作开始进入“对话式编辑”时代 Omni 是这次发布会最有视觉冲击的产品。
先解释 Omni 是什么
一句话:Omni 是 Nano Banana 的“视频版”
它可以把图像、音频、视频、文本组合成输入,然后生成基于 Gemini 世界知识的高质量视频。
Nano Banana 是 Google 去年发的 AI 图像编辑工具,简单到几百万人都在用,你不用打开 Photoshop,不用学图层蒙版,跟 AI 说一句“把老照片修干净”、“按这张草图生成一张正式插画”、“去掉合影里的路人”,它直接改给你。
Omni 把这一套搬到了视频上
看个案例就知道了,可以通过自然语言轻松的编辑视频…
今天开放的 Omni 是哪一款
今天上线的是 Gemini Omni Flash(Omni 家族的第一款,类比手机型号里的“轻量版”)。它现在只能生成视频,单条最长 10 秒。
Google 在博客里强调:10 秒不是模型能力的上限,是为了让更多人先用上而做的产品选择。后续还会扩展到生成图像、生成音频。
所以 Omni 严格意义上不是“视频模型”,是一个统一的多模态创作引擎,视频只是第一步。

Omni 跟 Google 之前的视频工具 Veo 比,主要差在几点
第一,输入可以混着喂:你可以同时丢给它一张图、一段视频、一段音频、几句文字。它不是把这些拼起来,是真的“读懂”几者之间的关系再合成一段统一的视频。
我现场测试的,输入一张图像,图像上标注了我想要的内容↓

然后直接上传照片,自动生成视频
或者通过任意输入组合创作视频
第二,对话式编辑,前后一致:你说“把这个雕塑材质改成气泡的”,它改。再说“让公寓灯光跟着音乐节奏亮起来”,它继续改。每一次修改都建立在上次的基础上,主角、场景、风格保持一致,不会乱掉。
第三,物理感更准:一颗弹珠在轨道上滚动的速度和加速度、人手碰到镜子时镜面像液体一样泛起涟漪、水流和反光,这些以前需要专业的 VFX(视觉特效)工程师才能做的镜头,Omni 直接生成。
第四,能讲故事:因为 Omni 接通了 Gemini 的世界知识库,它可以做“蛋白质折叠”的黏土动画教程视频,或者“26 个字母对应 26 个奇怪物品”的节奏感小品。这种“既要准确又要有创意”的内容,过去要找会动画的人手工做。
第五,AI Avatar(你的数字分身):录一段你自己的视频,再大声念几个数字(作为身份验证),Omni 给你生成一个数字版的自己。生成出来的分身只有你本人能用,别人不能拿你的脸做视频。然后你可以让“自己”出现在登月视频里,或者去掉自己合影里的路人。Google 自己管这个能力叫“个人专属 meme”。
Google 故意没开放的能力 Omni 暂时不允许用户编辑视频里的“音频和讲话”。
Google 在博客里直说,这个能力还在测,要等他们“想清楚怎么负责任地交给用户”再放出来。
怎么用,分三档
付费订阅用户:Google AI Plus / Pro / Ultra 全球订阅用户,今天起就能在 Gemini App 和 Google Flow(创作工具)里用。
视频创作者:YouTube Shorts 和 YouTube Create App 这周起免费开放,每个 YouTube 创作者直接调用,不用额外付费。
开发者和企业:几周内通过 API 推出。
Omni 会替代之前的 Veo 3.1…
Google Search、Workspace、购物和开发者工具,也都在围绕 Agent 重构
除了这三个主角,Google I/O 26 还有很多产品更新,但它们都可以放进同一条主线里理解:Gemini 正在进入 Google 的每一个入口。
搜索这边:Gemini 3.5 Flash 已经成为 Gemini App 和 Google Search 中 AI Mode 的默认模型。资料里还提到,3.5 Flash 的智能体编程能力会让 Search 出现更动态的生成式 UI,也会引入 24 小时信息智能体。
这代表搜索正在从“找网页”,走向“直接帮你生成结果和工具”。
开发者这边:Google 推出了 Managed Agents in the Gemini API。开发者可以通过一次 API 调用启动一个 Agent,让它推理、使用工具,并在隔离的 Linux 环境里执行代码。这套能力由 Antigravity agent harness 驱动,基于 Gemini 3.5 Flash,并接入 Interactions API 和 Google AI Studio。
这对 AI 应用开发者很重要。以前你是调用一个模型,现在你可以调用一个能跑工具、能执行代码、能保留环境状态的 Agent。
Workspace 这边:Google 把 Spark、Gmail Live、Docs Live、Keep、Google Pics 等能力放进办公场景。Spark 是 24 小时个人 AI Agent,可以在用户指令下帮忙处理数字生活,同时在高风险操作前先征求用户同意。
购物这边:Google 推出 Universal Cart,想把 Search、Gemini、YouTube、Gmail 等场景里的购物行为统一到一个购物车里。Google 还提到 AP2,也就是 Agent Payments Protocol,用来建立用户、商家和支付处理方之间透明、可验证的链接,并会从 Gemini Spark 开始接入。
这些更新看起来分散,底层逻辑一致:
Google 想让 Gemini 不只停留在聊天窗口里,而是进入搜索、办公、开发、购物和内容创作的真实工作流。
剩下的更新:Agent 能力分发到了 Google 每个产品 Google 这次的其余更新基本都在同一条主线上:把 AI Agent 能力放进每个日常用的 Google 产品里。
这次发布会最反常的一件事,是 3.5 Pro 没来
这场发布会从头看到尾,有个细节几乎没人讨论:Google 没有发 Gemini 3.5 Pro。
只在 keynote 里轻描淡写带了一句”已经在内部用了
下个月发…

这件事反常在哪里?
过去两年所有 AI 公司的发布节奏都是同一个套路:先发旗舰版立标杆,再发轻量版铺市场。GPT-5 先来、GPT-5 mini 后到。Claude Opus 先发、Haiku 跟上。Gemini 自己以前也是 Pro 先 Flash 后。
旗舰版是“我能做到多强”的展示牌,轻量版是“你能买得起”的走量款。这是延续了两年的剧本。
这次 Google 反过来了
轻量版先发,旗舰版押后
更反常的是 Google 直接把轻量版推到了“Gemini App 和 Google 搜索默认模型”的位置。这等于在说:新版 Pro 真的发出来之后,绝大多数用户也碰不到它,因为日常对话和搜索查询都已经被 Flash 接管了。
这个反常背后我的一个判断是:对于绝大多数真实任务来说,模型能力可能已经够用了。
继续往“更聪明”那个方向堆能力,边际收益在变小。
把“够用的能力”压到普通人用得起的价格和速度,反而是更值钱的事。
如果这个判断是对的,那这次发布会的真正信号不是“Gemini 又出三个新东西”,是 AI 行业进入了一个新阶段:
过去两年比的是模型能多聪明,从今天开始,比的是同样的聪明能多便宜、多快、多无感地出现在普通人的日常里。
Spark 跑在云端、Omni 进 YouTube、Flash 接管搜索,三个产品都在做同一件事:把“用 AI 需要专门去用 AI”这层门槛拆掉。
你回头看,这一年里所有让你印象深的 AI 产品,都不是因为“它最强”,而是因为“它出现在了你已经在做的事情里”。
Cursor 出现在你写代码的地方,Nano Banana 出现在你修图的地方,ChatGPT 的搜索出现在你查东西的地方。
3.5 Pro 押后这个动作,可能比这次发的三个产品本身更说明问题。
彩蛋:Google Android XR 智能眼镜 Google 在 I/O 2026 上预告了 Android XR 智能眼镜的更多细节:让 Gemini 这种 AI 助手离开手机,住进你戴的眼镜里,让你“不用掏手机”就能完成日常的事。
戴上眼镜,Gemini 能帮你干什么
说一句”Hey Google”,或者敲一下镜腿,就能唤醒 Gemini。下面是 Google 官方给的几个具体场景,每一个都跟“不掏手机”有关:
看到什么问什么:走过一家餐厅问 Gemini 它的口碑、抬头问那朵云是什么云类、看不懂的停车牌让 Gemini 翻译一下。
导航不用看屏幕:眼镜知道你站在哪、面朝哪个方向,给你一步步的口头方向。还可以让 Gemini 在路线上加一站,或者按你的口味推荐附近的餐厅。
接电话发短信不用掏手机:通过镜腿喇叭通话,让 Gemini 帮你总结刚才没接的消息。还能让它根据周围环境放配套的音乐。
拍照顺便修图:说一句“Hey Google,拍张照然后给所有人戴上滑稽帽子”,眼镜拍完照直接用 Nano Banana 改图。这个组合很关键,Google 把去年那个引爆图像编辑的 Nano Banana 直接接进了眼镜的拍照流程。
实时翻译:对方讲外语,Gemini 同步翻译给你听,连语气和音调都尽量贴合对方原声。看菜单或路牌时也能直接翻译给你听。
替你跑多步任务:让 Gemini 在后台帮你在 DoorDash 下咖啡订单,你手机继续放兜里,眼镜只在最后一步确认时提示你。
直接调用手机 App:语音叫 Uber、用 Mondly 学语言。
眼镜同时兼容 Android 和 iOS 手机,今秋上市…
明天我会现场去体验下…
加入 XiaoHu.ai 日报社群 每天获取最新的 AI 信息
End.
感 谢 阅 读
点赞,转发,关注关注关注↓↓

评论互动