AI 领域的 Harness Engineering:为什么模型不是全部
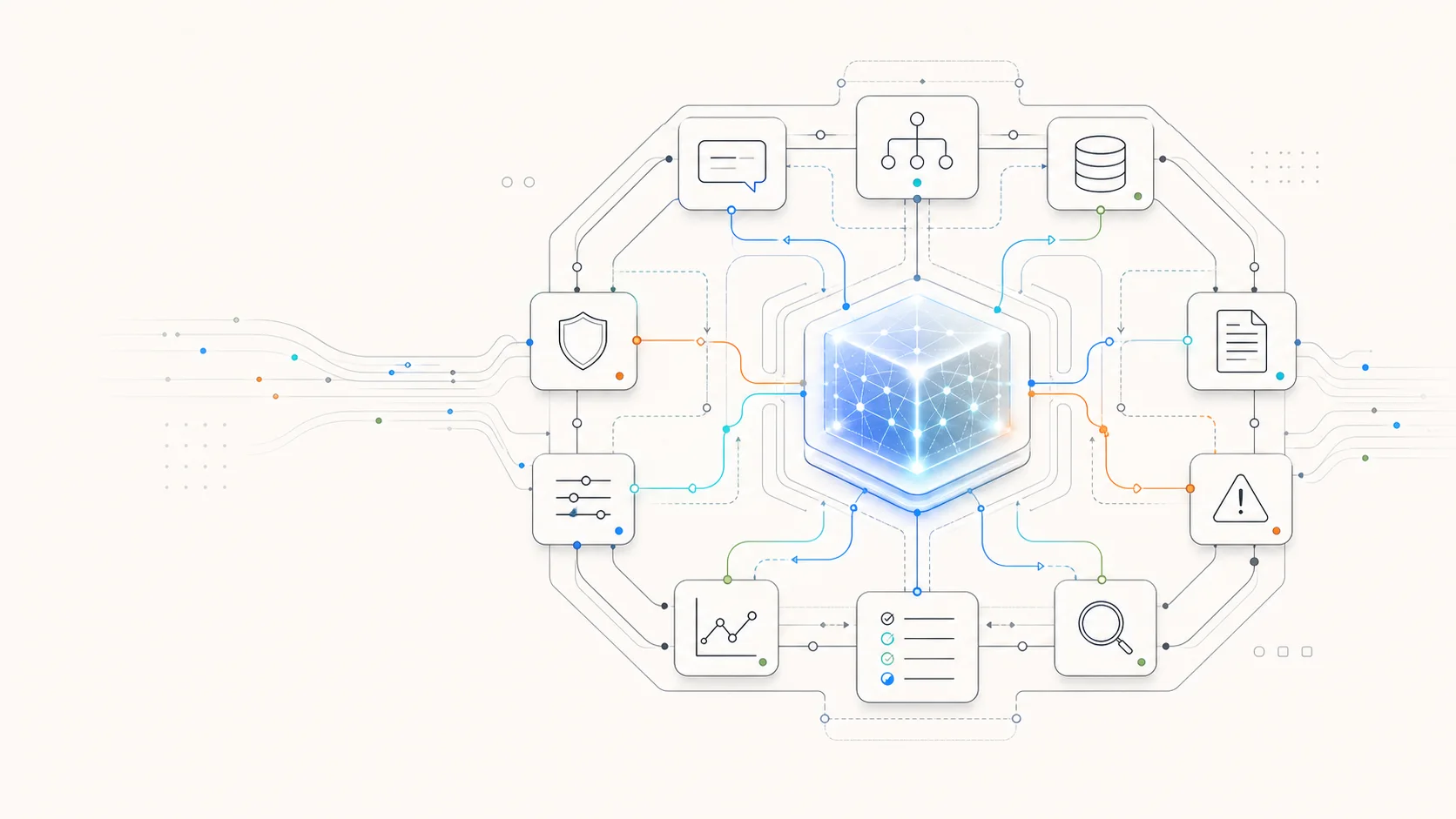
- 定义Harness Engineering为围绕AI模型构建控制层,使模型在生产环境中发挥作用
- 强调Harness决定产品质量,好Harness可弥补模型不足,差Harness拖累好模型
- 核心组件包括提示词管理、工具编排、记忆管理、错误处理、输入输出处理和安全护栏
- 在AI Agent中,Harness管理思考-执行循环,模型决策,Harness执行工具和流程
- 评估Harness是测试框架,运行数据集测量模型表现,类似软件测试自动化
原文链接:https://outcomeschool.com/blog/harness-engineering-in-ai
今天聊个有意思的话题——AI 领域的 Harness Engineering。
说实话,之前我对这个概念也挺模糊的。觉得 AI 模型牛就行了,其他都是锦上添花。但后来我发现,同样的模型,为啥别人用起来就是比我好用?研究了一圈才发现,差距不在模型,在于 Harness。
今天就把这个学习心得整理一下,希望对你们有帮助。
先搞清楚概念:Harness 到底是什么?
拆解一下这个词:Harness Engineering = Harness + Engineering。
Harness 简单理解就是控制层,帮助你有效地使用和管理系统。Engineering 则是用系统化的方式去构建它。
所以 Harness Engineering 本质上就是:围绕 AI 模型构建控制层的一切工作,让模型真正能在生产环境中发挥作用。
打个比方你就懂了。假设你有一台超强发动机,光发动机本身是没法带你兜风的。你还需要车身、方向盘、刹车、油门系统、仪表盘……这些东西组合在一起,发动机才真正有用。
发动机是 AI 模型(如 LLM),车身和所有围绕它的部件就是 Harness。
为什么 Harness 这么重要?
AI 模型本身能做的很有限:接收输入,返回输出。
但真实场景中,你需要的东西远不止这些:
- 调用工具(搜索引擎、数据库、API)
- 记住对话历史
- 错误处理
- 按特定格式输出
- 质量评估
- 生产环境部署和监控
没有 Harness,模型就是个“裸机”,有了 Harness,你才真正有了控制权。
换个角度想:你用过哪些 AI 产品?Coding助手、聊天机器人、AI 搜索引擎……它们背后都有一套 Harness。Harness 的质量直接决定了产品质量。 好模型配差 Harness,体验稀烂;差模型配好 Harness,体验也能很不错。
这就是 Harness Engineering 的价值所在。
Harness 的核心组件
一个完整的 AI Harness,通常包含这几个关键组件:
Prompt Management(提示词管理)
管理送入模型的所有内容:系统提示词、用户消息、模板、上下文。确保模型每次都收到正确的指令。
Tool Orchestration(工具编排)
AI 应用经常需要调用外部工具。比如 Coding 助手需要读取文件、执行命令、搜索网页。Harness 负责管理可用工具列表、调用方式、以及结果如何传回模型。
Memory Management(记忆管理)
对话中模型需要记住之前说过什么。Harness 决定保留什么、删除什么、以及对话太长时如何压缩历史消息。
Error Handling(错误处理)
模型可能生成无效输出,工具调用可能失败,API 可能报错。Harness 需要优雅地处理这些情况,防止整个应用崩溃。
Input and Output Processing(输入输出处理)
用户输入发送给模型前要处理,模型输出展示给用户前也要处理。包括解析、格式化、验证、过滤。
Guardrails(安全护栏)
内置的安全检查机制。确保模型不生成有害内容、不泄露敏感信息、行为在预期范围内。
Harness 在 AI Agent 中的应用
AI Agent 是个有意思的东西:它能使用工具、做决策、执行多步操作来完成复杂任务。它可以读文件、写代码、搜网页、发消息……直到任务完成才会停下。
而 Agent 的 Harness 比普通模型复杂得多,因为它要管理整个 Agent 循环。
整个流程是这样的:
Step 1: Harness 接收用户任务,准备初始提示词(系统指令 + 可用工具 + 上下文)
Step 2: Harness 发送提示词给模型,获取响应
Step 3: Harness 检查模型是否建议调用工具。如果需要,Harness 执行工具并把结果传回模型
Step 4: Harness 重复 Step 2 和 3,直到模型表示任务完成
Step 5: Harness 将最终结果展示给用户
整个循环都由 Harness 管理。模型负责思考,Harness 负责执行。
没有 Harness,Agent 就无法运作。Harness 把一个简单的模型变成了强大的 Agent。
关键点:模型本身不执行任何工具,它只决定调用哪个工具。真正执行工具并把结果喂给模型的是 Harness。
举个实际例子:
用户:"帮我查下北京的天气,然后发到我邮箱"
Harness Step 1: 准备提示词,工具列表 [天气API, 邮件API]
Harness Step 2: 发送给模型
模型回复:"我来查一下天气。调用 weather_api(city='北京')"
Harness Step 3: 执行天气API -> 结果:"28°C,多云"
Harness Step 4: 把结果发给模型
模型回复:"现在发送邮件。调用 email_api(to='user@email.com', body='北京天气:28°C,多云')"
Harness Step 5: 执行邮件API -> 结果:"邮件已发送"
Harness Step 6: 把结果发给模型
模型回复:"已完成。查询了北京天气(28°C,多云)并发送到您的邮箱。"
Harness Step 7: 将最终结果展示给用户模型决定做什么,但 Harness 执行每个操作并管理整个流程。这就是 Harness Engineering 在 AI Agent 中的工作方式。
Harness 在评估中的应用
说完 Agent,再聊聊 Harness 在模型评估中的应用。
评估 Harness 本质上是一个框架:运行一组测试,测量 AI 模型的表现。
举个例子,假设要测试模型解答数学题的能力。评估 Harness 会:
- 加载包含已知答案的数学题数据集
- 逐个将题目发送给模型
- 对比模型答案与正确答案
- 计算总体得分
这和软件测试的逻辑一样:写测试用例、运行、检查结果。评估 Harness 就是用同样的方式测试 AI 模型。
有了评估 Harness,你可以回答这些关键问题:
- 模型有多准确?
- 做了改动后,模型变好了还是变差了?
- 不同模型之间对比如何?
- 模型在哪里容易出错?
没有评估 Harness,测试就只能靠人工,又慢又不可靠。
Harness Engineering 的最佳实践
聊完概念和应用,最后分享几个最佳实践,都是踩坑总结出来的:
保持模块化。提示词管理、工具编排、记忆管理这些组件必须独立。这样改一个地方不会影响其他部分。
记录一切。每个输入、输出、工具调用、错误都要记录。方便调试,也方便理解模型行为。
从第一天就加护栏。别等出事了才想到安全检查。从一开始就把安全机制建进去。
让工具可靠。工具调用可能失败,Harness 必须能优雅处理:重试、使用降级方案、或者告知模型失败原因。
测试 Harness 而不只是模型。Harness 本身也可能有 bug。对 Harness 代码的测试要像对其他软件一样认真。
生产环境要监控。上线后持续监控延迟、错误、成本和质量。问题早发现早处理。
这些实践建议从一开始就坚持,会帮你省很多时间。
总结
用一个流程图来结束今天的内容:
用户输入
↓
[输入处理] → 清洗和格式化
↓
[提示词管理] → 构建包含上下文和指令的提示词
↓
[AI模型 (LLM)] → 生成响应
↓
[输出处理] → 解析和验证输出
↓
[工具编排] → 执行需要的工具调用
↓
[记忆管理] → 存储对话以备后用
↓
[安全护栏] → 检查安全性和合规性
↓
最终输出给用户AI 模型只是系统的一个组成部分。Harness 是除此之外的一切。在很多真实应用中,Harness 的代码量比模型集成代码大得多。
正如我一直说的:模型是大脑,但 Harness 让大脑变得有用。

评论互动