GPT-5.4 发布「官方介绍」

- 整合推理、编码与智能体工作流程,在GDPval等基准上超越前代,专为专业工作设计
- 首个原生计算机使用通用模型,支持100万token上下文,在OSWorld等基准上表现优异
- 结合GPT-5.3-Codex编码优势,在SWE-Bench Pro上匹配或超越,支持/fast模式提速
- 引入工具搜索,显著减少token使用,提升工具调用效率和准确性
- 改进可引导性,支持思考计划调整方向,减少幻觉和错误
本文基于 OpenAI 官方新闻翻译整理
GPT-5.4 介绍
专为专业工作而设计
今天,我们在 ChatGPT(作为 GPT-5.4 Thinking)、API 和 Codex 中发布了 GPT-5.4。这是我们最强大、最高效的专业工作前沿模型。同时,我们还为需要在复杂任务中获得最佳性能的用户发布了 GPT-5.4 Pro。
GPT-5.4 将我们在推理、编码和智能体工作流程方面的最新进展整合到一个前沿模型中。它集成了 GPT-5.3-Codex 行业领先的编码能力,同时改进了模型在工具、软件环境以及涉及电子表格、演示文稿和文档的专业任务中的表现。最终的结果是一个能够准确、高效地完成复杂实际工作的模型——减少来回沟通,直接交付你需要的结果。
在 ChatGPT 中,GPT-5.4 Thinking 现在可以提前提供其思考计划,这样你可以在其工作过程中调整方向,从而无需额外轮次就能获得更符合你需求的最终输出。GPT-5.4 Thinking 还改进了深度网络研究,特别是针对高度特定的查询,同时在需要长时间思考的问题上更好地保持上下文。这些改进意味着更高质量的答案,更快地到达,并始终与当前任务相关。
在 Codex 和 API 中,GPT-5.4 是我们发布的首个具有原生、最先进计算机使用能力的通用模型,使智能体能够操作计算机并在应用程序间执行复杂的工作流程。它支持高达100 万 token 的上下文,使智能体能够规划、执行和验证跨越长时间跨度的任务。GPT-5.4 还通过工具搜索改进了模型在大型工具和连接器生态系统中的工作方式,帮助智能体更高效地找到并使用正确的工具,同时不牺牲智能。最后,GPT-5.4 是我们迄今为止最高效的推理模型,与 GPT-5.2 相比,它使用更少的 token 来解决问题——这意味着减少的 token 使用和更快的速度。
结合在通用推理、编码和专业知识工作方面的进步,GPT-5.4 在 ChatGPT、API 和 Codex 上实现了更可靠的智能体、更快的开发工作流程和更高质量的输出。
| GPT-5.4 | GPT-5.3-Codex | GPT-5.2 | |
|---|---|---|---|
| GDPval(胜出或平局) | 83.0% | 70.9% | 70.9% |
| SWE-Bench Pro(公开版) | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified | 75.0% | 74.0%* | 47.3% |
| Toolathlon | 54.6% | 51.9% | 46.3% |
| BrowseComp | 82.7% | 77.3% | 65.8% |
*此前报告为 64.7%。通过新引入的保留原始图像分辨率的 API 参数,GPT-5.3-Codex 达到了 74.0%。
知识工作
在 GPT-5.2 通用推理能力的基础上,GPT-5.4 在对专业人士至关重要的实际任务上提供了一致且更加精致的结果。
在 GDPval 上,该测试评估智能体在 44 个职业中产出明确知识工作的能力,GPT-5.4 创造了新的最先进纪录,在 83.0% 的比较中匹配或超过行业专业人士,而 GPT-5.2 为 70.9%。
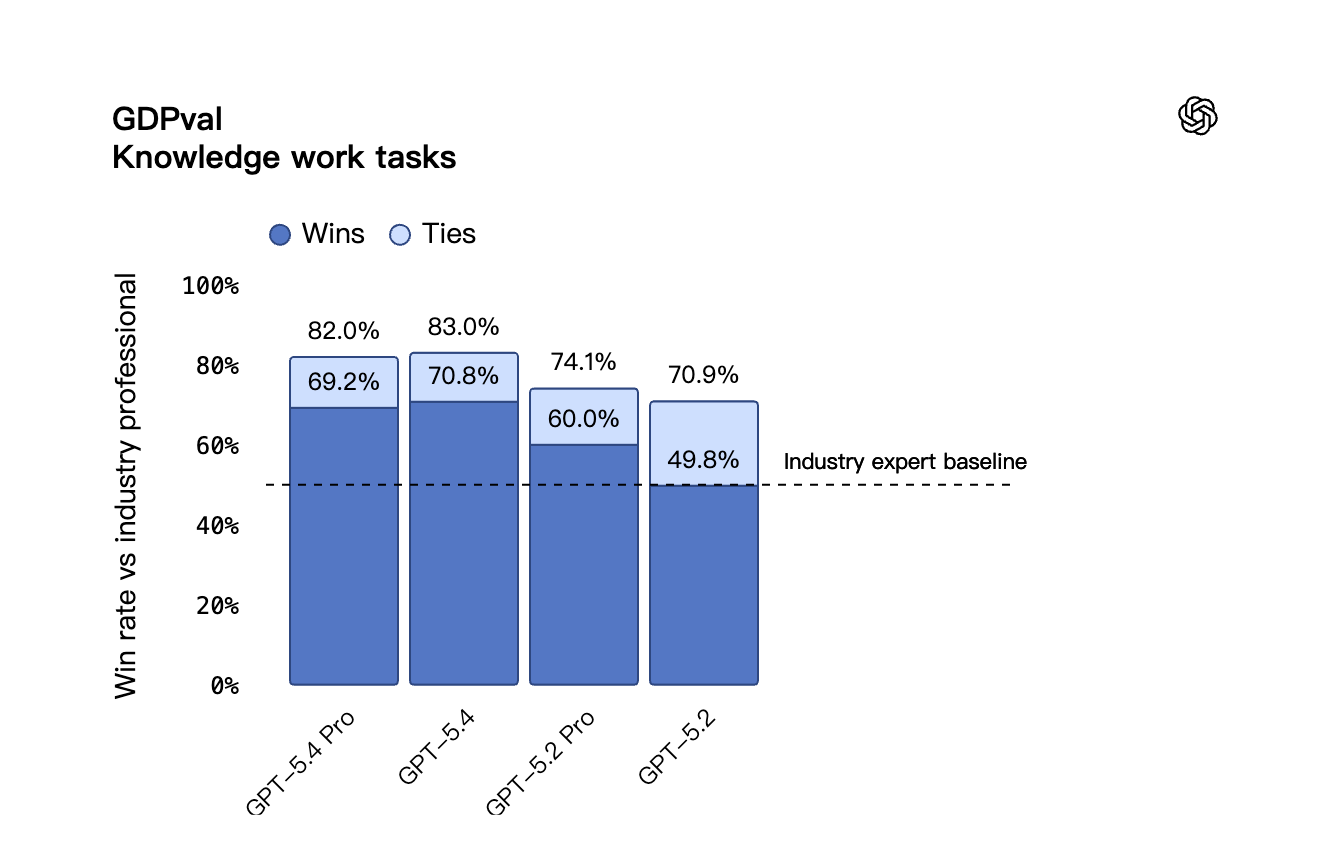
在 GDPval 中,模型尝试涵盖美国 GDP 前九大行业中 44 个职业的明确知识工作。任务要求实际的工作产品,如销售演示文稿、会计电子表格、紧急护理时间表、制造图表或短视频。GPT-5.4 的推理努力设置为 xhigh,GPT-5.2 设置为 heavy(ChatGPT 中稍低的水平)。
「GPT-5.4 是我们尝试过的最好的模型。它现在在我们用于专业服务工作的 APEX-Agents 基准测试中位居榜首。它擅长创建长期交付成果,如幻灯片组、财务模型和法律分析,在提供顶级性能的同时,运行速度更快,成本低于竞争的前沿模型。」
— Mercor CEO Brendan Foody
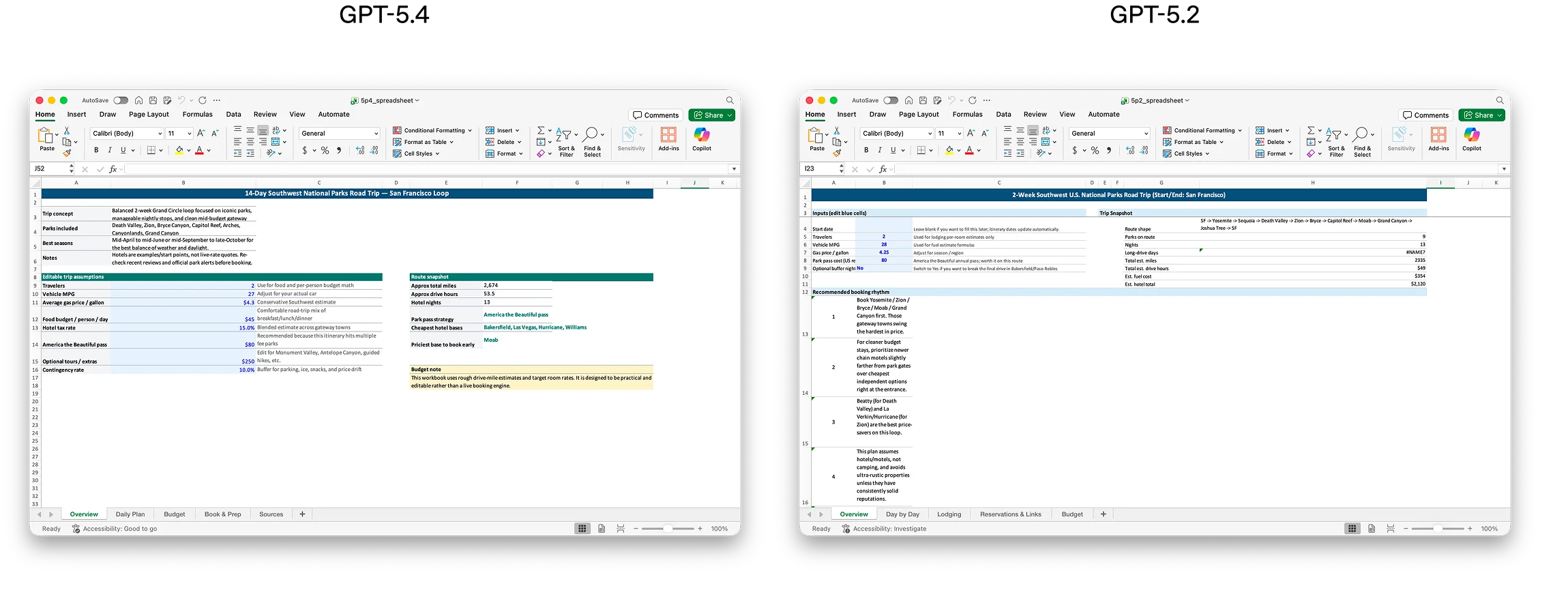
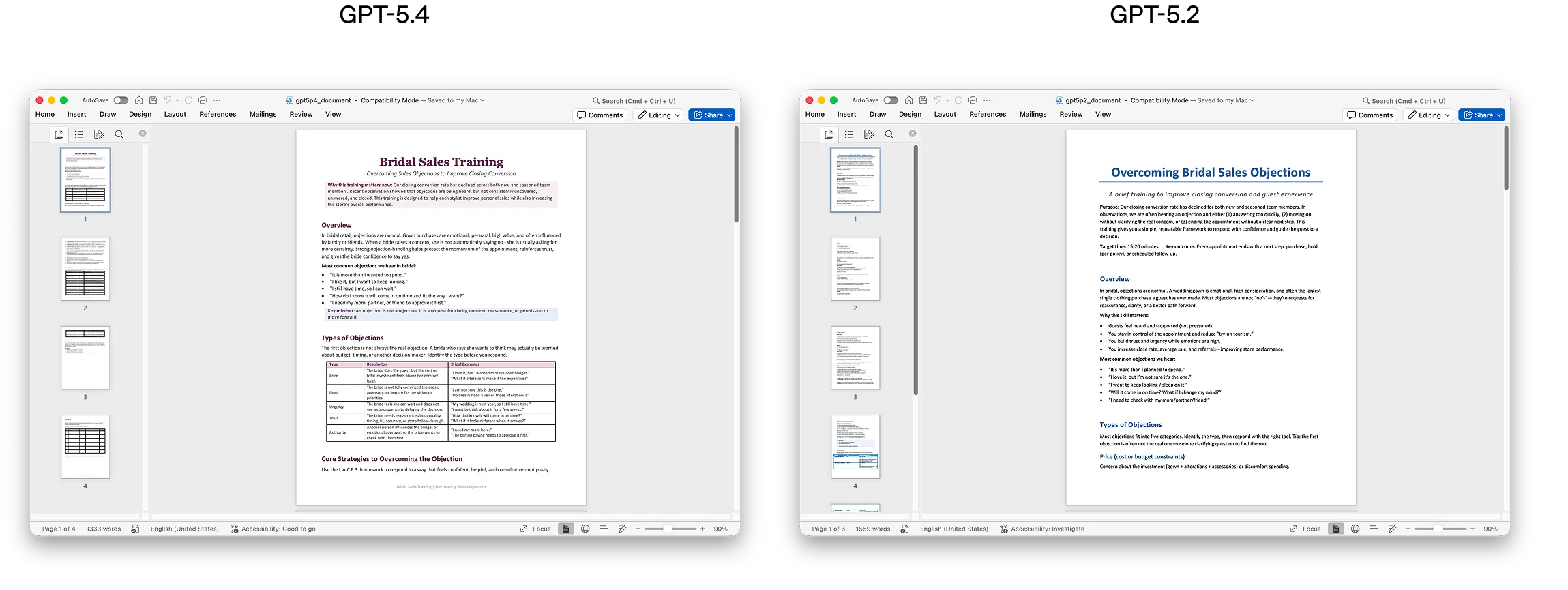
我们特别专注于改进 GPT-5.4 创建和编辑电子表格、演示文稿和文档的能力。在初级投资银行分析师可能完成的电子表格建模任务的内部基准测试中,GPT-5.4 达到 87.3% 的平均得分,而 GPT-5.2 为 68.4%。在一组演示文稿评估提示中,由于更强的美学、更丰富的视觉变化和更有效的图像生成使用,人类评估者在 68.0% 的时间里更偏好 GPT-5.4 生成的演示文稿,而非 GPT-5.2 的。
电子表格 · 文档 · 演示文稿
电子表格
文档
演示文稿
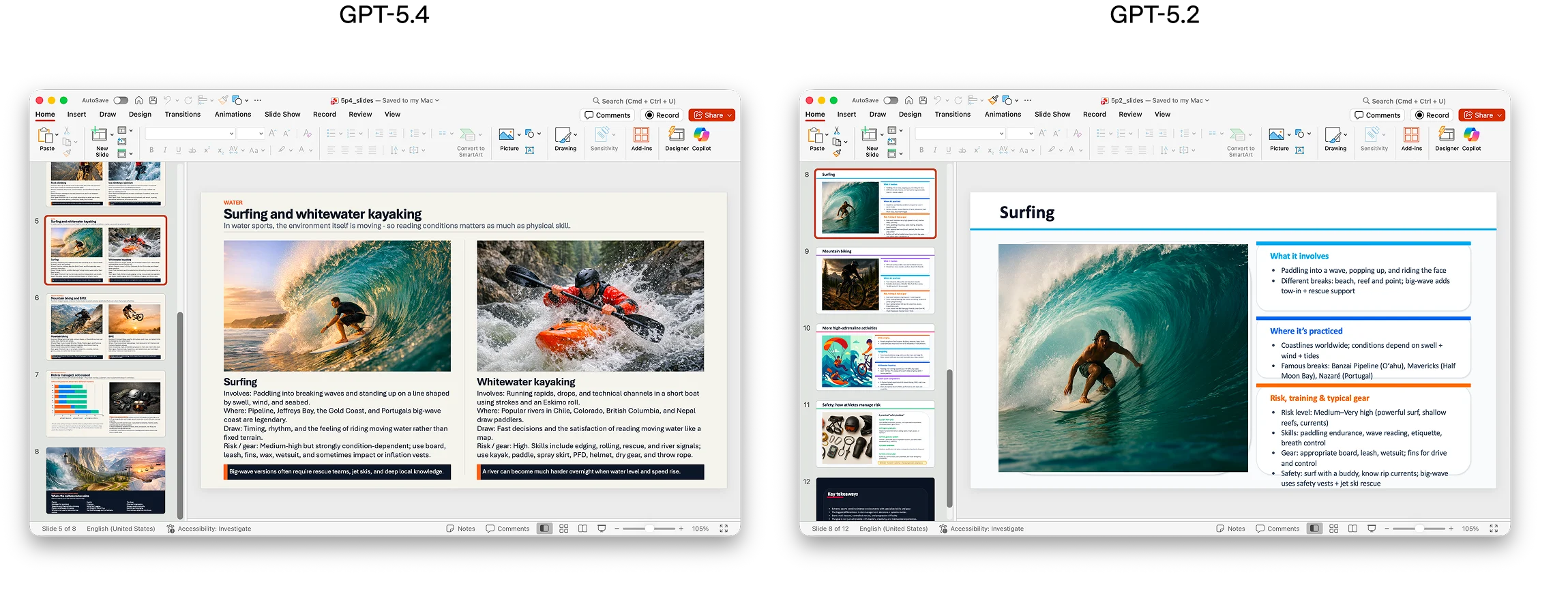
文档生成时推理努力设置为 xhigh
你可以在 ChatGPT 中使用 GPT-5.4 Thinking 或 Pro 试用这些功能。如果你是企业客户,我们推荐使用今天新发布的 ChatGPT for Excel 插件。我们还更新了 Codex 和 API 中可用的电子表格和演示文稿技能。
为了使 GPT-5.4 更擅长实际工作,我们在减少幻觉和错误方面取得了持续进展。GPT-5.4 是我们迄今为止最真实的模型:在一组用户标记事实错误去标识化的提示中,与 GPT-5.2 相比,GPT-5.4 的单个声明虚假可能性降低 33%,完整响应包含任何错误的概率降低 18%。
「GPT-5.4 为繁重的法律工作树立了新标准。在我们的 BigLaw Bench 评估中,它得分 91%。与其他模型相比,GPT-5.4 目前在构建复杂交易分析、在长合同中保持准确性以及提供法律从业者所需的高水平细节方面表现更好。」
— Harvey 应用研究主管 Niko Grupen
计算机使用和视觉
GPT-5.4 是我们首个具有原生计算机使用能力的通用模型,这标志着开发者和智能体的重大进步。对于构建跨网站和软件系统完成实际任务的智能体的开发者来说,它是目前最好的模型。
我们设计了 GPT-5.4 以在各种计算机使用工作负载中表现出色。它擅长编写代码通过 Playwright 等库操作计算机,以及根据截图发出鼠标和键盘命令。其行为可通过开发者消息进行引导,这意味着开发者可以调整行为以适应特定用例。开发者甚至可以通过指定自定义确认策略来配置模型的安全行为,以适应不同的风险容忍度水平。
模型的性能和灵活性体现在测试不同环境下计算机使用的基准测试中。在 OSWorld-Verified 上,该测试测量模型通过截图和键盘/鼠标操作导航桌面环境的能力,GPT-5.4 达到了最先进的 75.0% 成功率,远超 GPT-5.2 的 47.3%,并超越人类表现的 72.4%1。
在 WebArena-Verified 上,该测试测试浏览器使用,当同时使用 DOM 和截图驱动交互时,GPT-5.4 达到了领先的 67.3% 成功率,而 GPT-5.2 为 65.4%。在 Online-Mind2Web 上,该测试也测试浏览器使用,GPT-5.4 仅使用基于截图的观察就达到了 92.8% 的成功率,改进了 ChatGPT Atlas 的 Agent Mode,后者成功率为 70.9%。
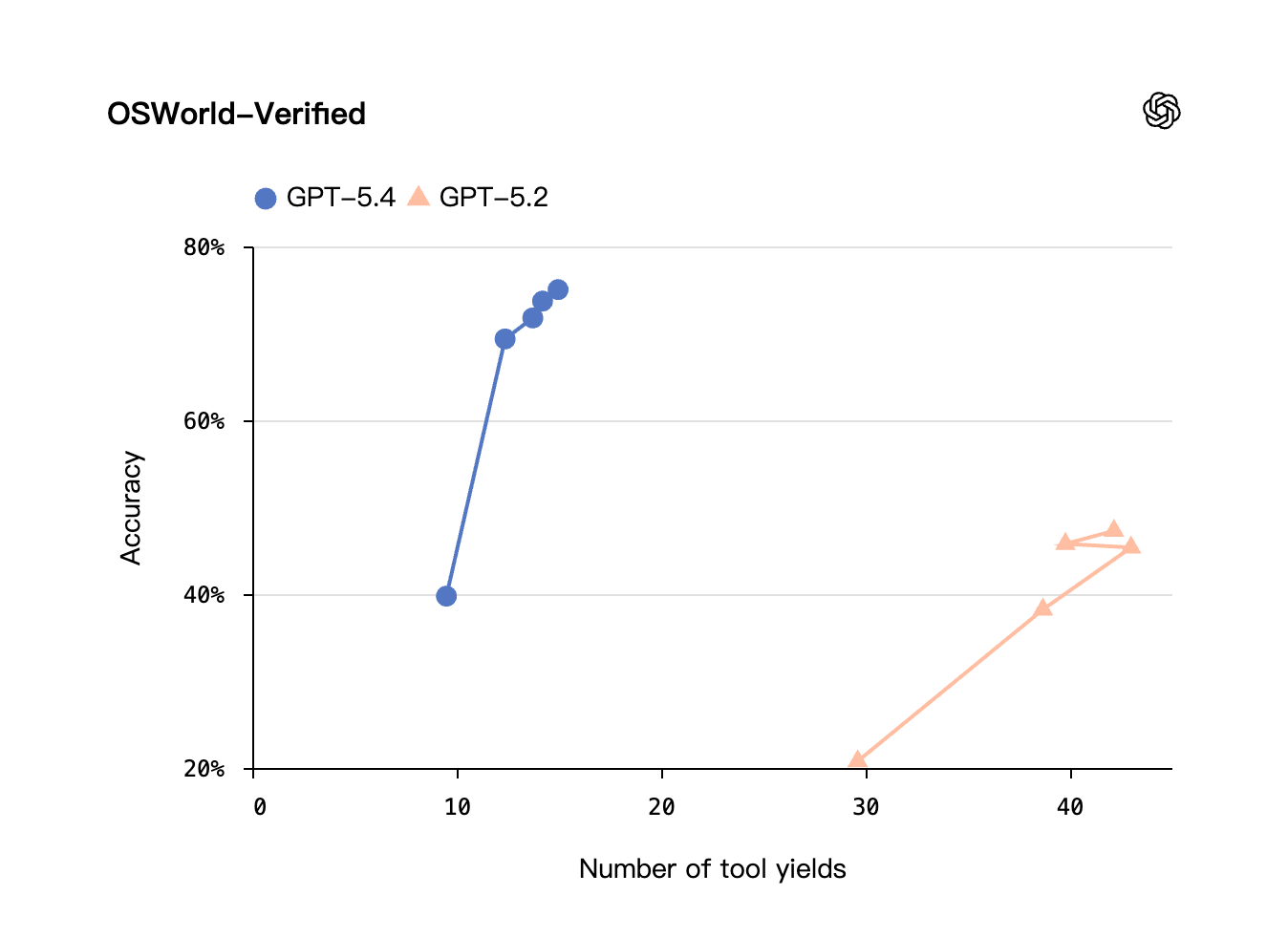
工具让渡是指助手等待工具响应时的让渡。如果并行调用 3 个工具,然后并行调用 3 个工具,让渡次数为 2。与工具调用相比,工具让渡是延迟的更好代理,因为它们反映了并行化的好处。
电子邮件和日历 · 批量数据录入
GPT-5.4 解释浏览器界面的截图,并通过基于坐标的点击与 UI 元素交互来发送电子邮件和安排日历事件。视频未加速。
GPT-5.4 改进的计算机使用建立在模型改进的通用视觉感知能力之上。在 MMMU-Pro 上,这是对模型视觉理解和推理的测试,GPT-5.4 在不使用工具的情况下达到了 81.2% 的成功率,改进了 GPT-5.2 的 79.5%。改进的视觉感知也转化为更好的文档解析能力。在 OmniDocBench 上,GPT-5.4 在不使用推理努力的情况下达到了 0.109 的平均误差(通过模型预测与真实值之间的标准化编辑距离测量),比 GPT-5.2 的 0.140 有所改进。
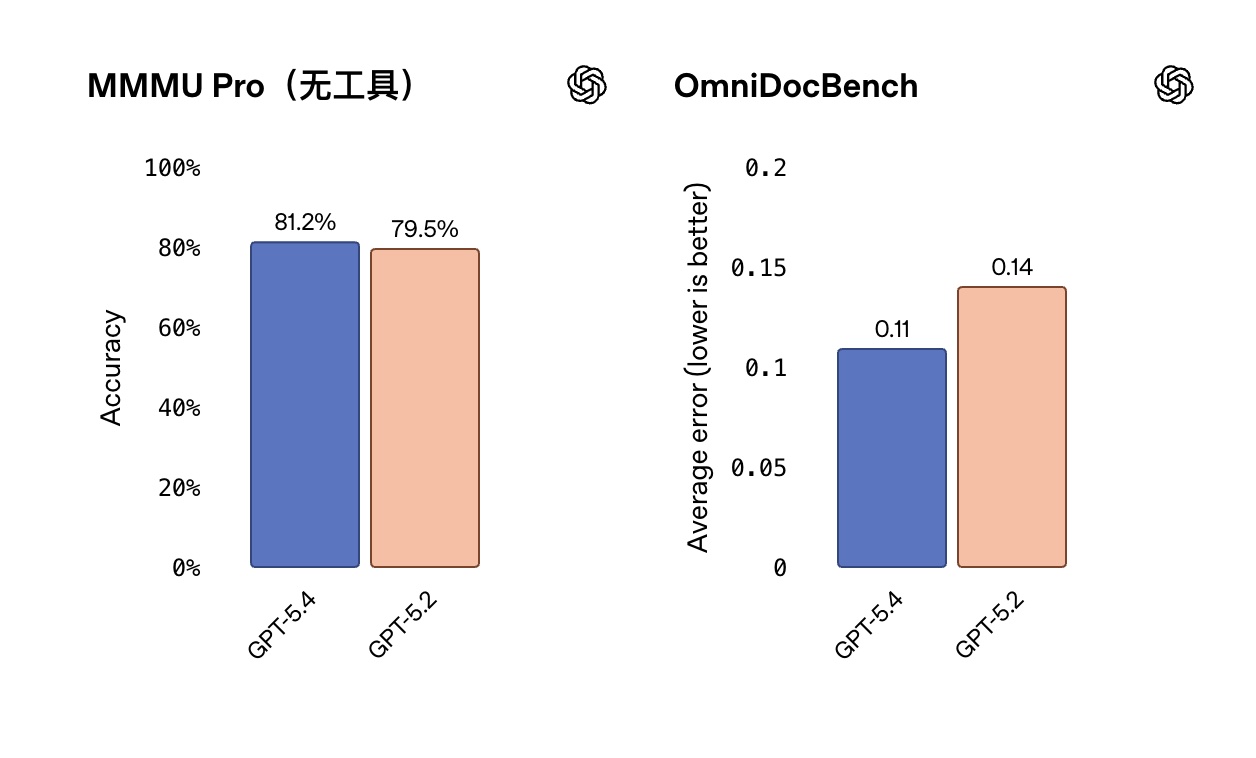 MMMUPro 运行时推理努力设置为 xhigh。OmniDocBench 运行时推理努力设置为 none,以反映低成本、低延迟性能。
MMMUPro 运行时推理努力设置为 xhigh。OmniDocBench 运行时推理努力设置为 none,以反映低成本、低延迟性能。
我们还在改进对密集、高分辨率图像的视觉理解,在这些图像中,完全保真度很重要。从 GPT-5.4 开始,我们引入了一个原始图像输入细节级别,支持高达 1024 万总像素或 6000 像素最大尺寸的完全保真感知(以较低者为准);高图像输入细节级别现在支持高达 256 万总像素或 2048 像素最大尺寸。在与 API 用户的早期测试中,我们观察到在使用原始或高细节时,定位能力、图像理解和点击准确性有显著提升。
「在我们评估约 3 万个 HOA 和财产税门户的计算机使用性能时,GPT-5.4 第一次尝试就达到 95% 的成功率,三次尝试内达到 100%,而之前的 CUA 模型约为 73-79%。它还快约 3 倍完成会话,同时使用约 70% 更少的 token,在大规模上显著提高了可靠性和成本效率。」
— Mainstay CEO Dod Fraser
在 API 中,开发者可以使用更新的计算机工具访问这些功能。请参阅我们更新的文档了解推荐的最佳实践。
编码
GPT-5.4 结合了 GPT-5.3-Codex 的编码优势和领先的知识工作及计算机使用能力,这在模型可以使用工具、迭代并进一步推进工作而需要较少人工干预的长期运行任务中最为重要。它在 SWE-Bench Pro 上匹配或超越 GPT-5.3-Codex,同时在各种推理努力下具有更低的延迟。
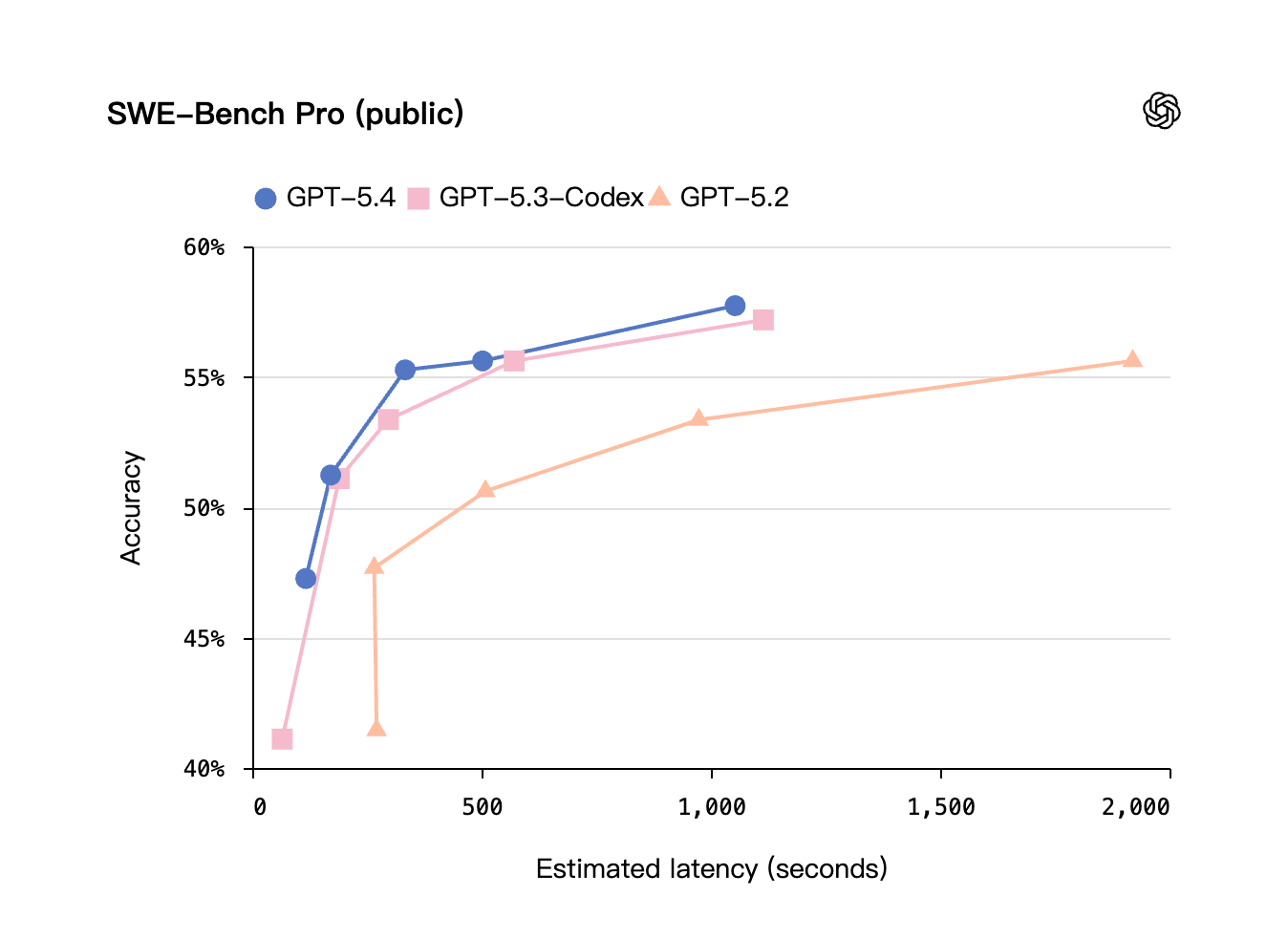
我们通过查看模型的生产行为并离线模拟来估算延迟。延迟估算考虑了工具调用持续时间(代码执行时间)、采样 token 和输入 token。实际延迟可能会有很大差异,并取决于我们模拟中未捕获的许多因素。推理努力从 none 扫描到 xhigh。
当打开时,Codex 中的 /fast 模式使用 GPT-5.4 可实现高达 1.5 倍更快的 token 速度。它是相同的模型,相同的智能,只是更快。这意味着用户可以在编码任务、迭代和调试中保持流畅。开发者可以通过使用优先处理以同样的快速速度通过 API 访问 GPT-5.4。
在评估和内部测试中,我们发现 GPT-5.4 擅长复杂的前端任务,其结果比我们之前发布的任何模型都更具美感和功能性。
作为模型改进的计算机使用和编码能力协同工作的演示,我们还发布了一个实验性 Codex 技能,称为「Playwright (Interactive)」。这允许 Codex 可视化调试 Web 和 Electron 应用;它甚至可以用于测试它正在构建的应用,在构建过程中进行测试。
主题公园模拟游戏 · RPG 游戏 · 金门大桥飞越
使用 GPT-5.4 从单个轻度指定的提示制作的主题公园模拟游戏,使用 Playwright Interactive 进行浏览器游戏测试,使用图像生成制作等距资源集。模拟包括基于图块的路径放置、游乐设施和景点建筑、客人路径寻找、排队和游乐设施循环,而公园指标如金钱、客人数量、幸福感、清洁度和评级根据布局表现和客人反应而升降。Playwright 用于自动化浏览器游戏测试,通过构建和扩展公园、放置和移除路径和游乐设施、检查相机导航以及验证客人、队列、游乐设施状态和 UI 指标在几轮游戏中正确更新。
提示:使用 $playwright-interactive 和 $imagegen。创建一个可以在浏览器中构建和导航的交互式等距主题公园模拟游戏。使用 imagegen 建立整体视觉愿景并生成游戏资源,包括游乐设施、路径、地形、树木、水、食品摊、装饰、建筑、图标和 UI 插图。世界应该感觉连贯、精致和视觉丰富,具有从等距视角效果良好的高端艺术方向。让我放置和移除路径、添加游乐设施、定位景点、在公园中平滑移动,同时监控客人活动、游乐设施状态和公园增长。包括可信的客人移动、简单的公园管理系统,如金钱、清洁、排队和幸福感,使体验感觉俏皮、清晰和完整,而不是粗糙的原型。优先考虑魅力、可读性和强烈的游戏感,而不是现实主义。
在游戏测试时,务必通过几轮游戏构建和扩展公园,验证放置和导航平滑工作,确认客人对公园布局和游乐设施做出反应,并确保视觉效果、UI 和交互感觉稳定和连贯。
「GPT-5.4 目前在我们内部基准测试中处于领先地位。我们的工程师发现它比以前的模型更自然、更有自信。它通过模糊问题而不怀疑自己,并主动并行化工作以保持进展。」 — Cursor 开发者教育副总裁 Lee Robinson
工具使用
通过 GPT-5.4,我们显著改进了模型与外部工具的协作方式。智能体现在可以在更大的工具生态系统中运行、更可靠地选择正确的工具,并以更低的成本和延迟完成多步骤工作流程。
工具搜索
在 API 中,GPT-5.4 引入了工具搜索,它允许模型在给定许多工具时高效工作。
以前,当给模型提供工具时,所有工具定义都提前包含在提示中。对于具有许多工具的系统,这可能会为每个请求增加数千甚至数万个 token,增加成本,减慢响应速度,并用模型可能永远不会使用的信息挤占上下文。
通过工具搜索,GPT-5.4 相反接收可用工具的轻量级列表以及工具搜索能力。当模型需要使用工具时,它可以查找该工具的定义并将其附加到当时的对话中。
这种方法显著减少了工具密集型工作流程所需的 token 数量并保留了缓存,使请求更快、更便宜。它还使智能体能够在更大的工具生态系统中可靠地工作。对于可能包含数万 token 工具定义的 MCP 服务器,效率提升可能是巨大的。
为了演示效率提升,我们在两种模式下使用所有 36 个 MCP 服务器启用的 Scale 的 MCP Atlas 基准测试评估了 250 个任务:(1) 直接在模型上下文中公开每个 MCP 函数,(2) 将所有 MCP 服务器放在工具搜索后面。工具搜索配置在实现相同准确性的同时,将总 token 使用量减少了 47%。
示例 token 数量来自 MCP-Atlas 公共数据集中 250 个任务的平均值。
智能体工具调用
GPT-5.4 还改进了工具调用,使其在推理过程中决定何时以及如何使用工具时更加准确和高效,特别是在 API 中。与 GPT-5.2 相比,它在 Toolathlon 上以更少的轮次实现更高的准确性,Toolathlon 是一个测试 AI 智能体使用真实世界工具和 API 完成多步骤任务能力的基准测试。例如,智能体需要阅读电子邮件、提取作业附件、上传它们、评分并将结果记录在电子表格中。
工具让渡是指助手等待工具响应时的让渡。如果并行调用 3 个工具,然后并行调用 3 个工具,让渡次数为 2。与工具调用相比,工具让渡是延迟的更好代理,因为它们反映了并行化的好处。
对于偏好推理努力 None 的延迟敏感用例,GPT-5.4 进一步改进了其前身。
在 τ2-bench 中,模型必须使用工具完成客户服务任务,其中可能有可以通信并对世界状态采取行动的模拟用户。推理努力设置为 None。
改进的网页搜索
GPT-5.4 更擅长智能体网页搜索。在 BrowseComp 上,这是对 AI 智能体持续浏览网页以查找难以定位信息的能力的测量,GPT-5.4 比 GPT-5.2 高出 17%,GPT-5.4 Pro 创造了 89.3% 的新最先进纪录。
在实践中,这意味着 GPT-5.4 Thinking 更擅长回答需要从网络上的许多来源整合信息的问题。它可以更持续地在多轮中搜索以确定最相关的来源,特别是对于「大海捞针」式的问题,并将它们综合成清晰、合理的答案。
在 BrowseComp 中,我们使用搜索阻止列表排除了包含基准测试答案的网站,以防止污染并确保性能的公平测量。GPT-5.4 的测量日期晚于 GPT-5.2,因此分数反映了模型、我们的搜索系统和互联网状态的变化。GPT-5.4 使用了更长、更新的阻止列表进行测试。模型使用 ChatGPT 搜索工具,该工具可能与 API 搜索略有不同。
「GPT-5.4 xhigh 是多步骤工具使用的新最先进纪录。Zapier 运行行业中最严格的工具使用基准测试之一,在数百个高级真实世界工作流程中测试模型。GPT-5.4 完成了以前模型放弃的工作——迄今为止最持久的模型。」 — Zapier CEO Wade
可引导性
与 Codex 开始工作时概述其方法类似,ChatGPT 中的 GPT-5.4 Thinking 现在将为更长、更复杂的查询使用前言概述其工作。您还可以在响应中途添加指令或调整其方向。这使得将模型引导到你想要的确切结果变得更容易,而无需重新开始或需要额外的轮次。此功能现已在 chatgpt.com 和 Android 应用上提供,即将推出 iOS 应用。
模型还可以在困难任务上思考更长时间,同时保持对对话中较早步骤的更强意识。这使它能够处理更长的工作流程和更复杂的提示,同时在整个过程中保持答案的连贯性和相关性。
此视频为演示目的而加速。
安全性
在过去几个月中,我们继续改进 GPT-5.3-Codex 引入的保障措施,同时为 GPT-5.4 的部署做准备。与 GPT-5.3-Codex 类似,我们在准备框架下将 GPT-5.4 视为高网络能力,并按照系统卡中的文档部署相应的保护措施。这些包括扩展的网络安全堆栈,包括监控系统、可信访问控制以及针对零数据保留 (ZDR) 表面上高风险请求的异步阻止,同时持续投资于更广泛的安全生态系统。
由于网络安全能力本质上具有双重用途,我们在部署时保持预防性方法,同时继续校准我们的策略和分类器。对于某些 ZDR 表面上的客户,请求级别阻止仍然是我们网络风险缓解堆栈的一部分;由于分类器仍在改进,在我们继续完善这些保障措施时,可能会出现一些误报。这些更新旨在改善保障措施的实际运作,包括减少不必要的拒绝和过度警告的响应,同时保持对滥用的强大保护。
我们继续对思维链 (CoT) 可监控性进行安全研究,以更好地了解模型如何推理并帮助检测潜在的不当行为。作为这项工作的一部分,我们引入了一个新的开源评估 CoT 可控性,测量模型是否可以故意混淆其推理以逃避监控。我们发现 GPT-5.4 Thinking 控制 CoT 的能力很低,这是安全的一个积极属性,表明模型缺乏隐藏其推理的能力,CoT 监控仍然是一个有效的安全工具。
可用性和定价
GPT-5.4 今天开始在 ChatGPT 和 Codex 中逐步推出。在 API 中,GPT-5.4 现在可以作为 gpt-5.4 使用。GPT-5.4 Pro 也在 API 中作为 gpt-5.4-pro 提供,供需要在最复杂任务中获得最佳性能的开发者使用。
在 ChatGPT 中,GPT-5.4 Thinking 从今天开始可供 ChatGPT Plus、Team 和 Pro 用户使用,取代 GPT-5.2 Thinking。GPT-5.2 Thinking 将在模型选择器的旧模型部分向付费用户开放三个月,之后将于 2026 年 6 月 5 日退役。企业版和教育版计划可以通过管理员设置启用早期访问。GPT-5.4 Pro 可供 Pro 和 Enterprise 计划使用。ChatGPT 中 GPT-5.4 Thinking 的上下文窗口保持与 GPT-5.2 Thinking 不变。
GPT-5.4 是我们的首个主线推理模型,集成了 GPT-5.3-codex 的前沿编码能力,并在 ChatGPT、API 和 Codex 中推出。我们称其为 GPT-5.4 以反映这一飞跃,并简化使用 Codex 时模型之间的选择。随着时间的推移,你可以期望我们的 Instant 模型和 Thinking 模型以不同的速度发展。
Codex 中的 GPT-5.4 包括对 100 万上下文窗口的实验性支持。开发者可以通过配置 model_context_window 和 model_auto_compact_token_limit 来尝试此功能。超过标准 272K 上下文窗口的请求以正常速率的 2 倍计入使用限制。
在 API 中,GPT-5.4 的每 token 价格高于 GPT-5.2,以反映其改进的能力,而其更高的 token 效率有助于减少许多任务所需的总 token 数。批处理和 Flex 定价以标准 API 费率的一半提供,而优先处理以标准 API 费率的两倍提供。
| API 模型 | 输入价格 | 缓存输入价格 | 输出价格 |
|---|---|---|---|
| gpt-5.2 | $1.75 / M tokens | $0.175 / M tokens | $14 / M tokens |
| gpt-5.4 | $2.50 / M tokens | $0.25 / M tokens | $15 / M tokens |
| gpt-5.2-pro | $21 / M tokens | - | $168 / M tokens |
| gpt-5.4-pro | $30 / M tokens | - | $180 / M tokens |
评估
专业工作
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| GDPval | 83.0% | 82.0% | 70.9% | 70.9% | 74.1% |
| FinanceAgent v1.1 | 56.0% | 61.5% | 54.0% | 59.5% | — |
| 投资银行建模任务(内部) | 87.3% | 83.6% | 79.3% | 68.4% | 71.7% |
| OfficeQA | 68.1% | — | 65.1% | 63.1% | — |
编码
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro(公开版) | 57.7% | — | 56.8% | 55.6% | — |
| Terminal-Bench 2.0 | 75.1% | — | 77.3% | 62.2% | — |
计算机使用和视觉
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| OSWorld-Verified | 75.0% | — | 74.0% | 47.3% | — |
| MMMU Pro(无工具) | 81.2% | — | — | 79.5% | — |
| MMMU Pro(有工具) | 82.1% | — | — | 80.4% | — |
工具使用
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| BrowseComp | 82.7% | 89.3% | 77.3% | 65.8% | 77.9% |
| MCP Atlas | 67.2% | — | — | 60.6% | — |
| Toolathlon | 54.6% | — | 51.9% | 45.7% | — |
| Tau2-bench 电信 | 98.9% | — | — | 98.7% | — |
学术
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| Frontier Science Research | 33.0% | 36.7% | — | 25.2% | — |
| FrontierMath Tier 1–3 | 47.6% | 50.0% | — | 40.7% | — |
| FrontierMath Tier 4 | 27.1% | 38.0% | — | 18.8% | 31.3% |
| GPQA Diamond | 92.8% | 94.4% | 92.6% | 92.4% | 93.2% |
| Humanity’s Last Exam(无工具) | 39.8% | 42.7% | — | 34.5% | 36.6% |
| Humanity’s Last Exam(有工具) | 52.1% | 58.7% | — | 45.5% | 50.0% |
长上下文
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| Graphwalks BFS 0K–128K | 93.0% | — | — | 94.0% | — |
| Graphwalks BFS 256K–1M | 21.4% | — | — | — | — |
| Graphwalks parents 0–128K(准确率) | 89.8% | — | — | 89.0% | — |
| Graphwalks parents 256K–1M(准确率) | 32.4% | — | — | — | — |
| OpenAI MRCR v2 8-needle 4K–8K | 97.3% | — | — | 98.2% | — |
| OpenAI MRCR v2 8-needle 8K–16K | 91.4% | — | — | 89.3% | — |
| OpenAI MRCR v2 8-needle 16K–32K | 97.2% | — | — | 95.3% | — |
| OpenAI MRCR v2 8-needle 32K–64K | 90.5% | — | — | 92.0% | — |
| OpenAI MRCR v2 8-needle 64K–128K | 86.0% | — | — | 85.6% | — |
| OpenAI MRCR v2 8-needle 128K–256K | 79.3% | — | — | 77.0% | — |
| OpenAI MRCR v2 8-needle 256K–512K | 57.5% | — | — | — | — |
| OpenAI MRCR v2 8-needle 512K–1M | 36.6% | — | — | — | — |
抽象推理
| 评估 | GPT-5.4 | GPT-5.4 Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| ARC-AGI-1(已验证) | 93.7% | 94.5% | — | 86.2% | 90.5% |
| ARC-AGI-2(已验证) | 73.3% | 83.3% | — | 52.9% | 54.2% (high) |
无推理评估
| 评估 | GPT-5.4 (none) | GPT-5.2 (none) | GPT-4.1 |
|---|---|---|---|
| OmniDocBench(标准化编辑距离) | 0.109 | 0.140 | — |
| Tau2-bench 电信 | 64.3% | 57.2% | 43.6% |
评估运行时推理努力设置为 xhigh,除非另有说明。基准测试是在研究环境中进行的,在某些情况下可能与生产 ChatGPT 提供略有不同的输出。
继续阅读
- openAI 全部产品
- 介绍 ChatGPT for Excel 和新的金融数据集成 · 产品 · 2026年3月5日
- GPT-5.3 Instant:更流畅、更有用的日常对话 · 产品 · 2026年3月3日
- 在 ChatGPT 中引入锁定模式和升级风险标签 · 安全 · 2026年2月13日
- 5.3 Instant Art Card
- ChatGPT Excel 1x1
- Lockdown-Mode Art-Card

评论互动