MiniMax M3:前沿编程能力、1M 上下文、原生多模态——三合一模型

- 发布MiniMax M3,首个开源权重模型整合前沿编程、1M上下文和原生多模态
- 采用MSA稀疏注意力架构,实现1M上下文窗口,计算量降至1/20
- 在SWE-Bench、Terminal-Bench等编程与Agent基准上达到前沿水平
- 原生多模态训练支持图像视频输入,交错数据扩展至100万亿token
- 真实任务中自主复现论文、优化CUDA kernel达9.4倍加速
MiniMax M3 今天正式发布。
M3 在编程和 Agent 等专业任务上达到了前沿水平。它采用了我们团队提出的全新注意力架构 MSA(MiniMax Sparse Attention),支持最高 1M token 的超长上下文窗口。同时,它也是一个原生多模态模型,支持图像和视频输入,还能操作桌面电脑。
这三项能力已经成为闭源前沿模型的标配。M3 是目前第一个也是唯一一个将三者合为一体的开源权重模型。
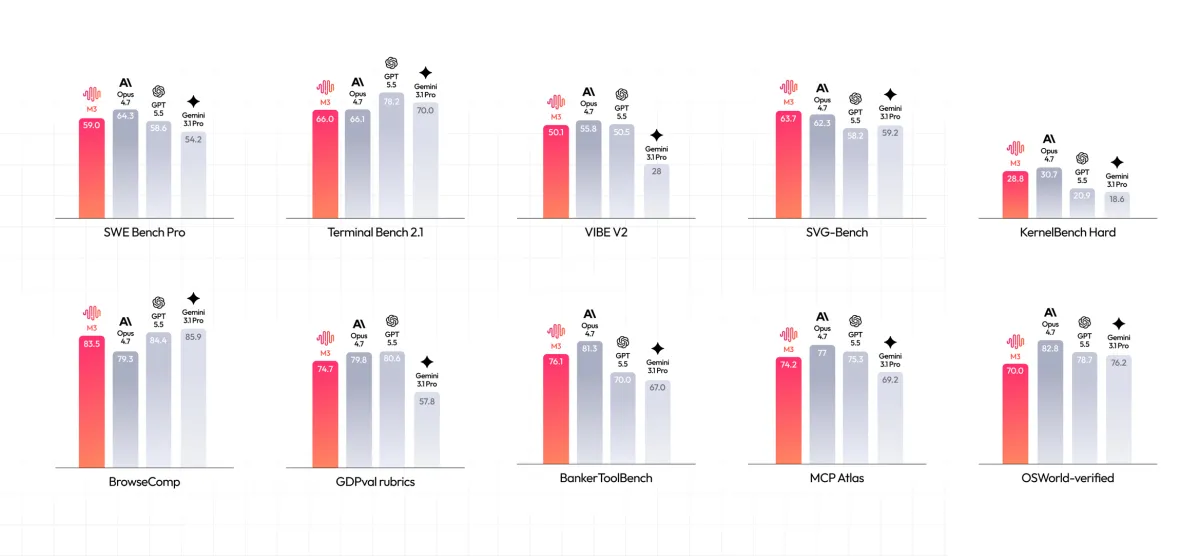
在衡量编程能力的 SWE-Bench Pro 上,MiniMax M3 超过了 GPT-5.5 和 Gemini 3.1 Pro,接近 Opus 4.7。在综合评估 SVG 生成性能的 SVG-Bench 上,MiniMax M3 超过了 Opus 4.7。
在多模态基准 OmniDocBench 上,MiniMax M3 的得分高于 Gemini 3.1 Pro。在端到端自主 Agent 评估框架 Claw-Eval 上,MiniMax M3 取得了最高分。
你可以通过 MiniMax Code、Token 套餐和我们的 API 服务立即体验 MiniMax M3。
MSA:架构创新推动上下文扩展
训练 M3 时,解决更复杂的 Agent 任务是最重要的目标之一,而其中最大的挑战之一就是上下文扩展。要实现真正的改变,必须从最基础的层面——注意力机制——入手,避免全注意力的“固有缺陷”:二次方计算复杂度增长。
MSA 是一种干净且易于扩展的全新稀疏注意力架构。它赋予了 M3 1M 的上下文窗口,让上下文真正成为可以独立扩展的维度。
稀疏注意力机制通常通过添加预过滤阶段来避免复杂度爆炸问题。与 DSA 和 MoBA 等方法相比,MSA 能够更精确地将 KV 划分为块,实现更高的有效上下文覆盖率。
同时,我们还在算子层面进行了直接优化,采用了“KV 外层 gather Q”的方式,以 KV 块为外层循环来聚合命中的查询。每个块只读取一次,内存访问是连续的;在 M3 的 head 配置下,算术强度显著优于常见方法——比开源的 Flash-Sparse-Attention 和 flash-moba 快 4 倍以上。
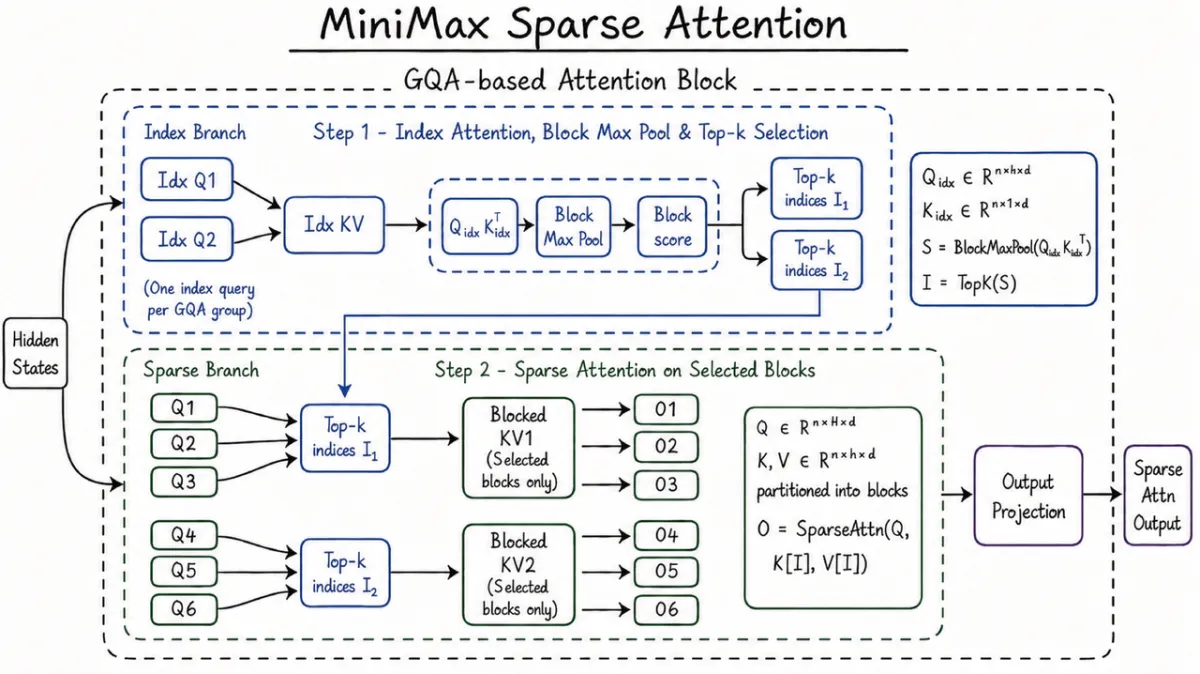
其干净、可扩展、易实现且硬件友好的特性使得理论增益能够在实践中完全兑现:在 100 万的上下文长度下,M3 每 token 的计算量仅为上一代模型的 1/20。我们在预填充阶段实现了超过 9 倍的加速,在解码阶段实现了超过 15 倍的加速。此外,在多次消融实验中,MSA 在绝大多数能力上与全注意力匹配。
前沿编程与 Agent 能力
编程和 Agent 能力是 M3 的重点改进领域。在软件工程和终端执行等国际公认基准上,M3 达到了前沿水平:
- SWE-Bench Pro:59.0%
- Terminal-Bench 2.1:66.0%
- SWE-fficiency:34.8%
- KernelBench Hard:28.8%
- MCP Atlas:74.2%
如今,编程能力越来越取决于模型能否基于真实用户逻辑进行训练。现有的编程基准往往无法完全捕捉真实用户体验。
目前大多数代码 Agent 的训练和评估都基于单轮任务的假设。但真实使用场景并非如此。用户通常在同一会话中持续协作:澄清需求、调整方案、跨上下文分配任务、基于中间结果进行多轮迭代。
为了缩小基准与真实用户体验之间的差距,我们构建了交互式用户模拟器框架。
通过模拟真实开发者在协作中的行为模式,该框架在训练和评估期间让模型接触到更接近生产环境的交互场景。它可以模拟需求细化、方案讨论、基于反馈的修正、持续任务切换和复杂项目迭代等行为。因此,Agent 不再仅仅是被动执行指令,而是能够主动与用户协作完成任务。
下一代 Agent 编程不仅以代码生成来衡量,还取决于长期协作能力、规划能力和人机协作效率。M3 在编程和 Agent 真正重要的数据上进行了规模化扩展,目标不仅是在基准上领先,更是成为开发者在真实研发工作流中的可靠协作伙伴。
多模态:交错训练,持续扩展
M3 是一个从第 0 步就经过混合模态训练的模型。这种原生多模态方式让不同模态的语义空间更自然、更深层次地融合。
同时,在数据混合和组成方面,我们大量实验表明,交错数据对提升模型性能的重要性比通常认为的更大。
这种文本与图像或其他模态在序列中自然交错的数据,对于扩展整体训练数据也很重要。在为这类数据重建了整个数据管线后,我们现在能够将训练数据扩展到 100 万亿 token 的量级。
真实世界任务
在我们内部使用和测试 M3 的过程中,几个真实世界任务给人留下了深刻印象。
独立论文复现
作为前沿模型的三个核心能力,我们想看看 1M 超长上下文、顶级编程和 Agent 能力以及原生多模态能力在长线程中解决复杂任务时的表现。
我们给 M3 一篇获得 ICLR 2025 杰出论文奖的论文《Learning Dynamics of LLM Finetuning》,让它独立复现。该论文研究大语言模型在微调过程中的“学习动力学”。最终,M3 自主运行了近 12 小时,独立产出了 18 个 commit 和 23 张实验图表,成功完成了核心实验。
它不仅成功匹配了 SFT 阶段预测概率变化的趋势,还清晰观察到 DPO 实验中强调的挤压效应,并成功验证了原论文提出的 Extend 缓解方法。
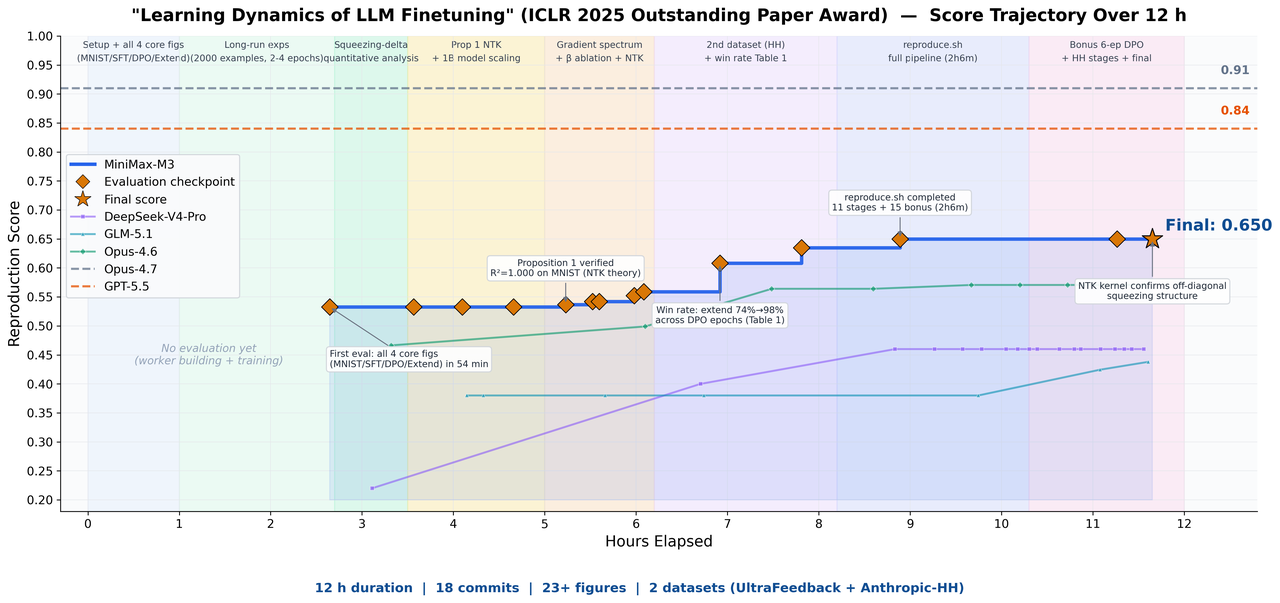
理解论文中的曲线、数据和公式需要多模态能力,而长上下文确保了论文、代码和实验日志都能同时放入上下文窗口。只有具备足够强的编程和 Agent 能力,模型才能在长线程中甚至并发执行的情况下完成复现。
M3 做到了这一切。
CUDA Kernel 优化
FP8 矩阵乘法(GEMM)是大模型推理中计算最密集的部分之一,也是最难优化的部分之一。工程师必须同时处理多个紧密耦合的问题,包括数据布局、计算流水线调度和硬件特性适配。在 NVIDIA Hopper 架构 GPU 上,手写一个生产级 FP8 GEMM kernel 通常需要经验丰富的团队一到两周的集中投入。
我们用这个任务来评估 M3 的长期自主迭代能力。我们让 MiniMax M3 在 NVIDIA Hopper 架构 GPU 上优化这个 kernel。模型只有任务描述、一个基准评估脚本和一个无法直接运行的 Triton 骨架代码,没有可参考的高性能实现。这意味着模型无法通过模仿现有方案走捷径,必须从第一性原理出发,自主探索优化路径。
在接下来约 24 小时的持续执行中,M3 完成了 147 次基准提交和 1,959 次工具调用。它独立走过了从基线实现到生产级优化的全过程,包括基线实现、autotune 配置生成、性能瓶颈诊断、CUDA Graph 集成、持久化 kernel 重写和 host 端调度优化。每一步都通过基准反馈自我验证,无需人工干预。
最终,经过六轮里程碑式优化,M3 将 Hopper FP8 硬件峰值利用率从第一版的 7.6% 提升到了 71.3%,相比原始版本实现了 9.4 倍加速。
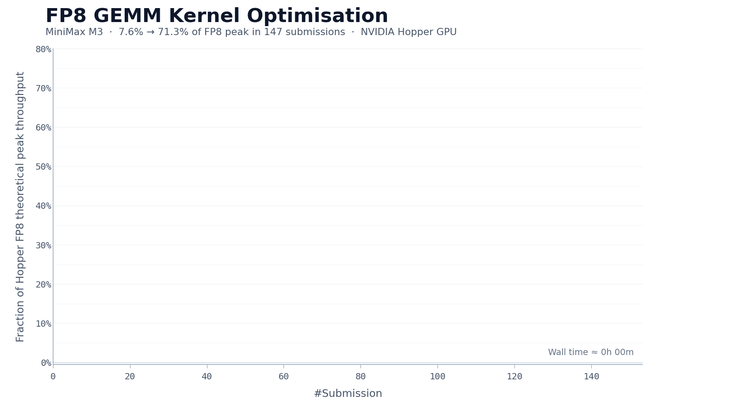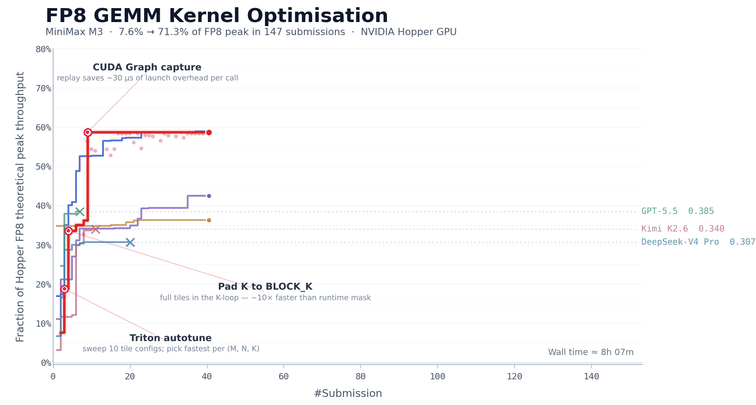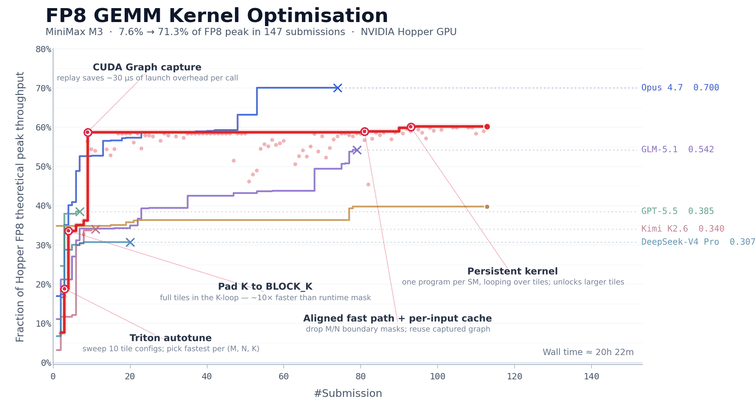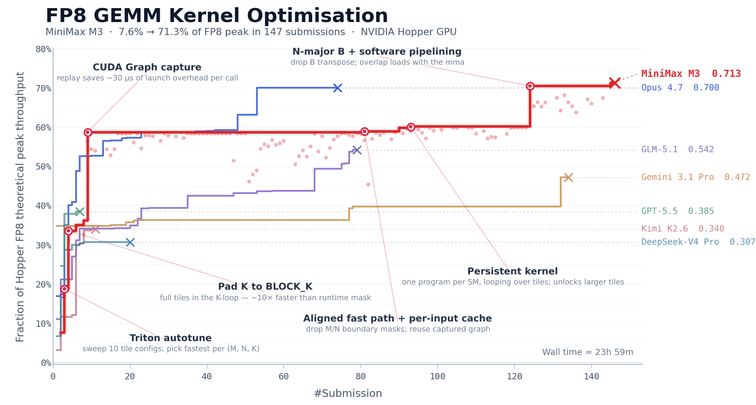
除了数据之外,模型的执行过程也值得关注。除 Opus 4.7 和 M3 外,大多数其他模型在前 30 次提交内就停止了进展并自行退出。而 M3 的最佳方案出现在第 145 次提交。在此之前,模型经历了多个无法进一步提升的性能平台期,但它仍持续探索不同的优化方向。
这里所需的能力超越了传统的代码生成。重复工具调用产生的上下文是高度结构化且密集的,这正是 MSA 的长上下文注意力分配机制发挥作用的地方。
让 M3 训练模型
在 CUDA 算子优化任务中,M3 展示了在具有明确优化目标和清晰反馈信号的单个工程任务上的长程迭代能力。但真实的研究工作往往没有如此清晰的反馈结构;研究者通常面对的是更开放的问题。
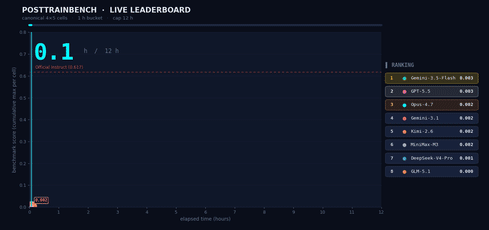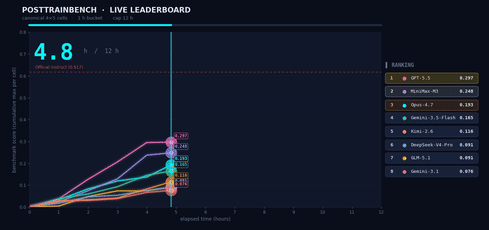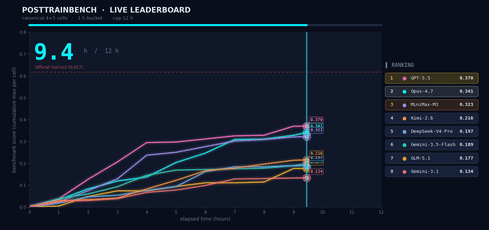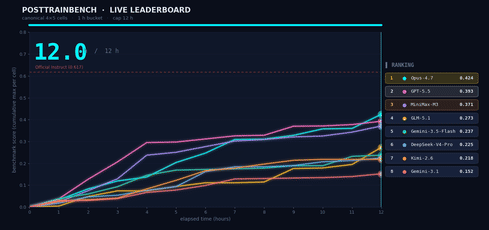
我们想了解 M3 在需要自主决策的场景中的表现,因此我们在 PostTrainBench 上进行了测试。任务如下:给 M3 四个仅完成预训练、尚不具备任何下游能力的 Base 模型,让它在 12 小时内自主完成数据合成、训练、评估和迭代的全过程。最终目标是让这些模型在数学推理(AIME2025)、工具调用(BFCL)、科学知识推理(GPQA Main)、基础算术推理(GSM8K)和代码生成(HumanEval)方面获得基本能力。
整个“数据合成 → 训练 → 评估 → 迭代”过程在无任何人工干预下进行。Agent 必须自主决定合成什么样的数据、选择什么训练策略、如何根据评估结果调整下一轮计划。M3 最终得分 0.37,略低于 Opus 4.7(0.42)和 GPT-5.5(0.39),但明显领先于其他模型。
MiniMax Code
随着 M3 的发布,MiniMax Code 也进行了更新。作为专门为 M3 设计并与 M3 联合训练的 Agent 产品,MiniMax Code 能够充分发挥 M3 在长上下文、编程/Agent 任务和原生多模态方面的能力,是搭配 MiniMax-M3 的首选 Agent。
对于长程复杂任务,MiniMax Code 的 Agent Team 可以将大任务分解为多阶段、并发且动态可调的工作流,由 Agent 集群协作推进。通过 Producer + Verifier 对抗性 Harness 循环,Agent Team 在执行过程中能够持续产出、反思和自我纠正。它可以自主运行数天无需人工干预,最终交付高质量结果。
我们看到 Claude Code 最近也发布了类似方向的 Dynamic Workflows。与 Claude Code 更强调基于 JS 代码的固定编排相比,MiniMax Code 更专注于“深度反思和持续纠错”:Agent 根据任务进度实时调整计划和优先级,同时用户可以随时介入添加需求或纠正方向。
得益于 M3 的原生多模态能力,MiniMax Code 还支持计算机使用(Computer Use)。例如,用户可以在手机上说:“帮我打开本地的 ERP 客户端,根据这张 Excel 表格批量录入发票信息。”MiniMax Code 会自动在电脑上跨应用、跨文件、跨系统完成所需操作。
MiniMax Code 基于优秀的开源社区项目 OpenCode 和 Pi 构建。我们也计划在未来开源这个项目,回馈开源社区。
MiniMax Code 桌面端:agent.minimaxi.com/download
MiniMax Code 可搭配 MiniMax Token 套餐使用。
MiniMax Token 套餐:将前沿模型带入开发者日常
MiniMax M3 是为服务更多用户而构建的前沿模型。
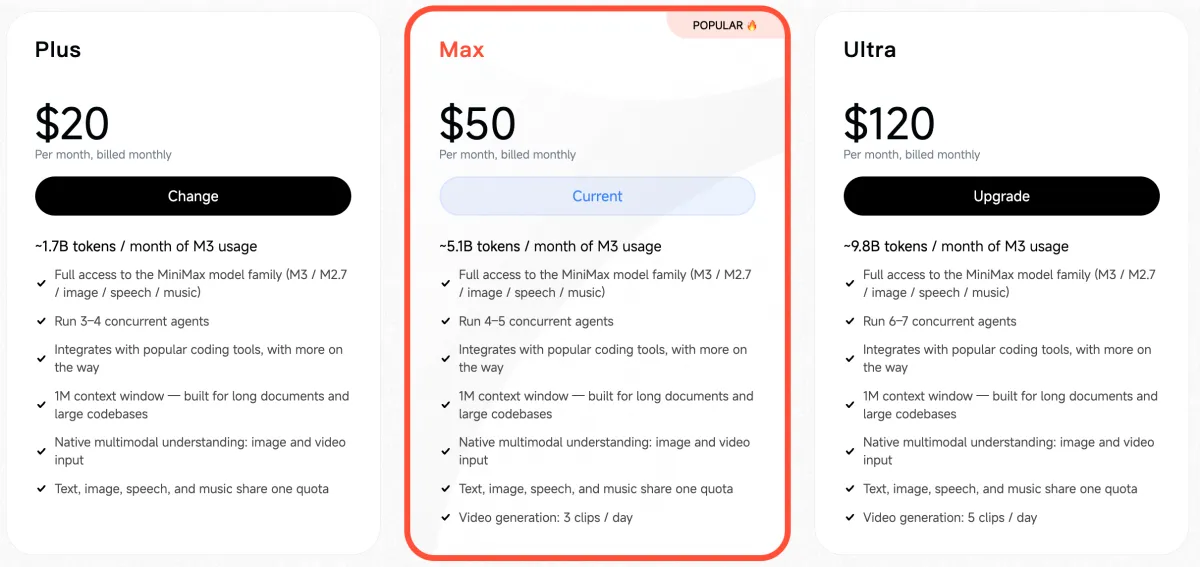
随着本次发布,MiniMax Token 套餐也进行了更新,共三个档位:
- Plus $20/月:约 17 亿 token/月的 M3 使用量
- Max $50/月:约 51 亿 token/月的 M3 使用量
- Ultra $120/月:约 98 亿 token/月的 M3 使用量
在同等价位的订阅方案中,MiniMax Token 套餐提供了全球最高的 token 额度之一。文本、图像、语音和音乐共享同一用量池。
三个档位均已开放,订阅后立即开始使用!
订阅链接:platform.minimax.io/subscribe/token-plan
API
M3 API 现已上线。
定价取决于输入长度:输入 token ≤512K 的调用按标准费率计费,覆盖绝大多数对话和编程场景;输入 超过 512K 的调用按更高的长上下文费率计费,主要用于超长文档解析和全仓库代码理解等高负载场景。
M3 支持开启或关闭思考模式。开启思考时,模型适合复杂推理、Agent 任务和长程协作;关闭思考时,响应更快,适合对话和代码补全等延迟敏感场景。两种模式共享相同定价,可在请求时按需切换。
所有价格还可搭配两种服务级别:默认的 standard 级别适用于常规请求;priority 级别(service_tier=priority)在高并发场景下获得调度优先权和更稳定的响应延迟,适合对 SLA 敏感的工业场景。Priority 通道目前通过销售支持开通,预计数天内向所有用户开放。
API 指南:platform.minimax.io/docs/api-reference/api-overview

我们将持续提升模型服务稳定性并优化吞吐量。未来 10 天内,我们将发布模型技术报告并开源相应的模型权重。
如今,模型更新的速度之快,很容易让人忘记这本质上仍然是扎实、渐进的进步。它遵循自身的客观规律,奖励那些按这些规律稳步前进的团队。正如我们创立之初就坚信的那样,我们将竭尽全力持续提升模型的智能水平,让更多人用上它们。
感谢你的信任、建议和批评。
Intelligence with Everyone!

评论互动