Loop Engineering:2026 年每个 AI 工程师都需要掌握的新范式

- 设计循环而非手动提示agent,让系统自动发现、规划、执行、验证和迭代
- 循环工程依赖6个构建块:自动化、worktrees、skills、插件、子agent和记忆
- 循环分单agent和fleet两种规模,以及开环和闭环两种类型
- 成本是循环工程的主要障碍,DeepSeek等模型使大规模循环在经济上可行
- Prompt Engineer写提示,Loop Engineer设计产生验证结果的系统
Peter Steinberger,OpenClaw 的创造者,现就职于 OpenAI。
2026 年 6 月 9 日他发了这样一段话:
“你不应该再手动给编码 agent 发提示了。你应该设计循环(loop),让循环去提示你的 agent。”
接着,Anthropic Claude Code 的负责人 Boris Cherny 用不同的方式表达了同样的意思:
“我不再手动给 Claude 发提示了。我有一些正在运行的循环,它们会提示 Claude 并决定下一步做什么。我的工作就是写循环。”
两位最资深的 AI 工程师,同一个信息。
大多数人看到后都在想:这到底是什么意思?
我深入研究了这个问题。
以下是完整的解析——通俗易懂,没有术语,只有你需要的心智模型。
但首先:为什么大多数人永远构建不了循环
循环听起来很棒。然后你看到了账单。

以下是一些没人一开始就告诉你的事情:
- 一个中等编码任务的单 agent 循环:50,000–200,000 tokens
- 一个编排器 + 3 个专家的 fleet 循环:500,000–2,000,000 tokens
- 每天早上按计划运行的循环:每周数百万 tokens
按标准 API 定价,一周认真的循环工程花费比大多数人整月的 AI 预算还高。
这就是为什么 Peter Steinberger 的回复里充满了这样的评论:
“你说得轻松——你有无限的 OpenAI 使用权限。”
他们说得没错。
在正常预算下,循环工程很快就会崩溃。
每一次重试都要花钱。每一次自我纠正都要花钱。每一个子 agent 都要花钱。每一次验证都要花钱。
自由探索的开环?烧 token 的速度让你心疼。
这就是没人谈论的隐藏障碍。
循环不难设计。
难的是负担得起。
这正是中国大语言模型解决的问题。
像 DeepSeek、Kimi 和 MiniMax 这样的模型让 agent 循环在经济上变得可行。
自主 agent 最大的问题不是智能。
而是 token 消耗。
循环消耗 token 很快。
单次运行轻松消耗 50K–200K tokens。
运行多个 agent、每天安排循环、或处理大型代码库——成本会迅速失控。
这就是 DeepSeek 改变游戏规则的地方。
DeepSeek V4 是目前大规模运行循环最便宜的 frontier 级模型之一。
你得到的是:
- 1M 上下文窗口——为大型项目和长期运行的工作流而建
- 384K 最大输出——处理更大生成任务而不中断
- DeepSeek V4 Flash + Pro 模型
- 极低的 token 定价
- 支持工具调用 + JSON 输出的 agent 工作流
- 高并发(Flash 最高 2500 请求)
为什么 1M 上下文窗口很重要:
循环需要记忆。
一个在大型项目上工作的编码循环需要同时保持:
- 之前的运行结果
- 当前的错误信息
- 架构文档
- 测试结果
- 代码库上下文
大多数模型在中间会丢失上下文。你的循环开始忘记之前发生了什么。
DeepSeek 能保持显著更多的上下文,所以长期运行的循环能保持连贯。
而且由于定价如此之低:
循环不再让人破产。
第一部分:旧方式 vs 新方式
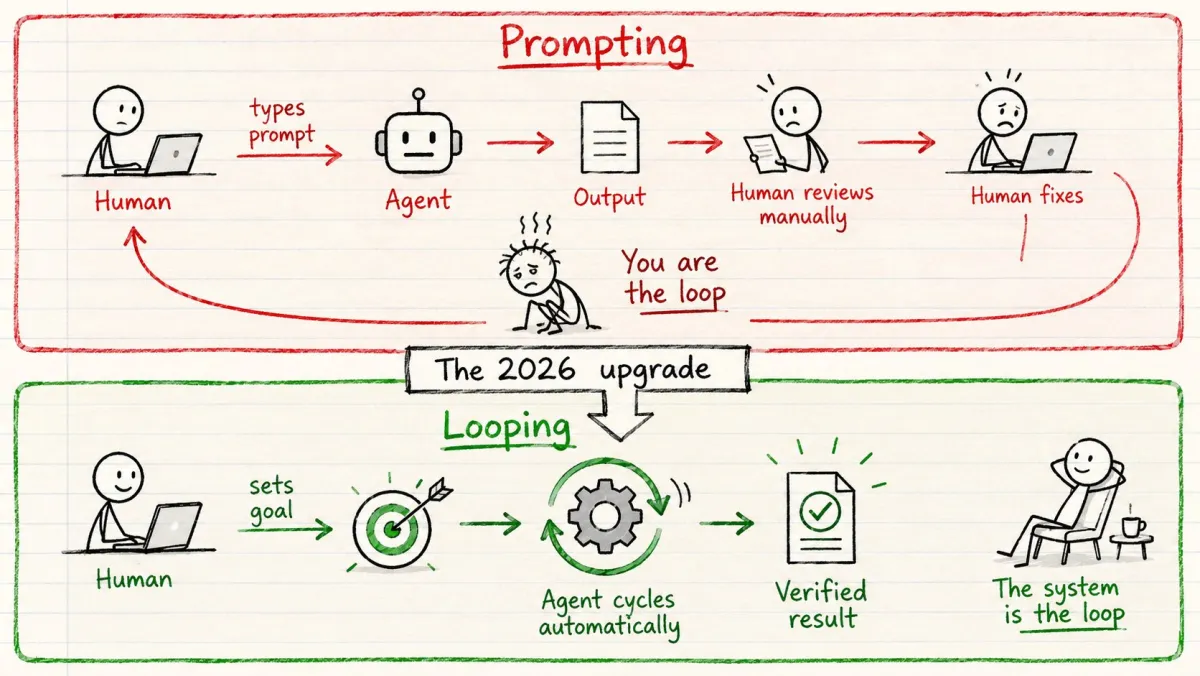
过去两年,我们一次一个任务地提示 agent。
你输入提示。agent 回应。你审查。你修复错误。你再提示。你就是那个循环。
这种情况正在改变。
你不再要求 agent 构建一个落地页然后每一步都亲自驱动,而是设置一个循环来处理发现、规划、工作、检查和迭代——直到目标达成。
区别如下:
旧方式(提示):
你 → 提示 → Agent → 输出 → 你审查 → 你修复 → 重复
新方式(循环):
你设定目标 → 循环运行 → Agent 发现 → 规划 → 执行 → 验证 → 迭代 → 完成
你不再每一步都手动提示了。
agent 替你重复这个周期。
提示给 agent 指令。
循环给 agent 一份工作。
第二部分:循环工程到底是什么
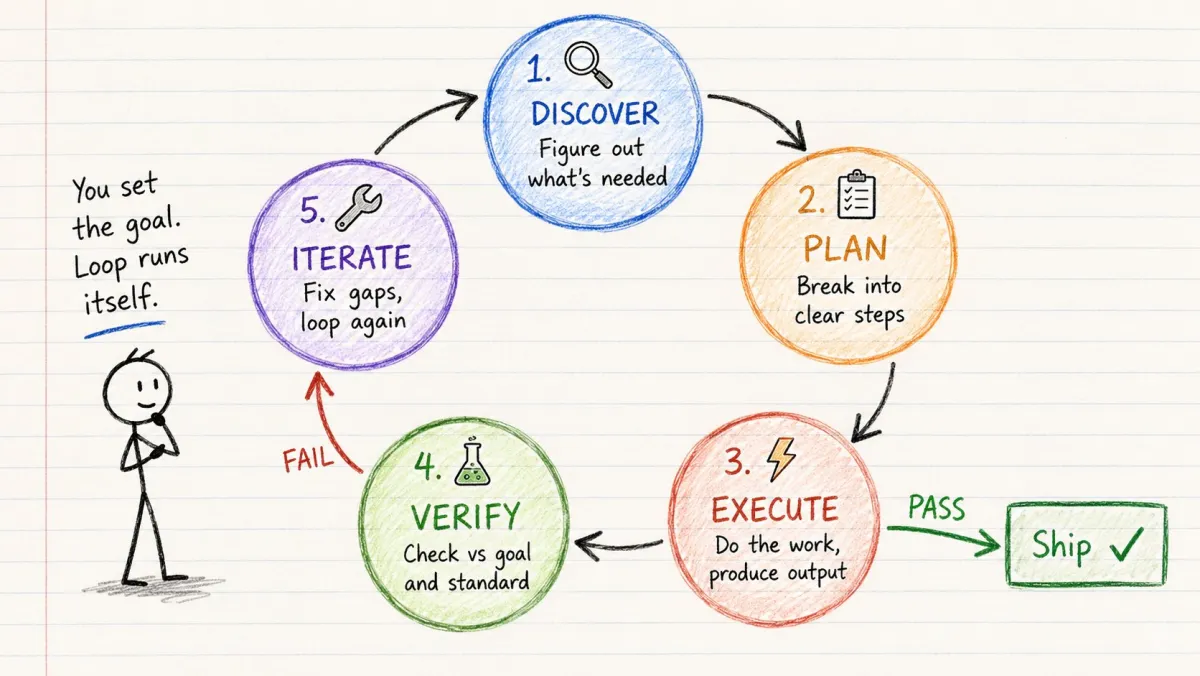
循环工程(Loop Engineering)是设计可重复的反馈循环的实践,这些循环引导 AI agent 从尝试到经过验证的结果——无需持续的人工干预。
循环是你搭建的一个系统。
几乎任何 agent 框架都能运行它。
只是取决于你如何配置它。
最简单的形式:一个 agent 对自己工作:
- 研究
- 起草
- 对照目标检查草稿
- 修复薄弱点
- 重复这个周期直到工作通过要求
每一个循环——无论简单还是复杂——都经过相同的 5 个阶段:
发现 → 规划 → 执行 → 验证 → 迭代
通过验证 → 交付。
未通过验证 → 再次循环。
这就是全部核心思想。
第三部分:单 agent vs Fleet
循环有两种规模:
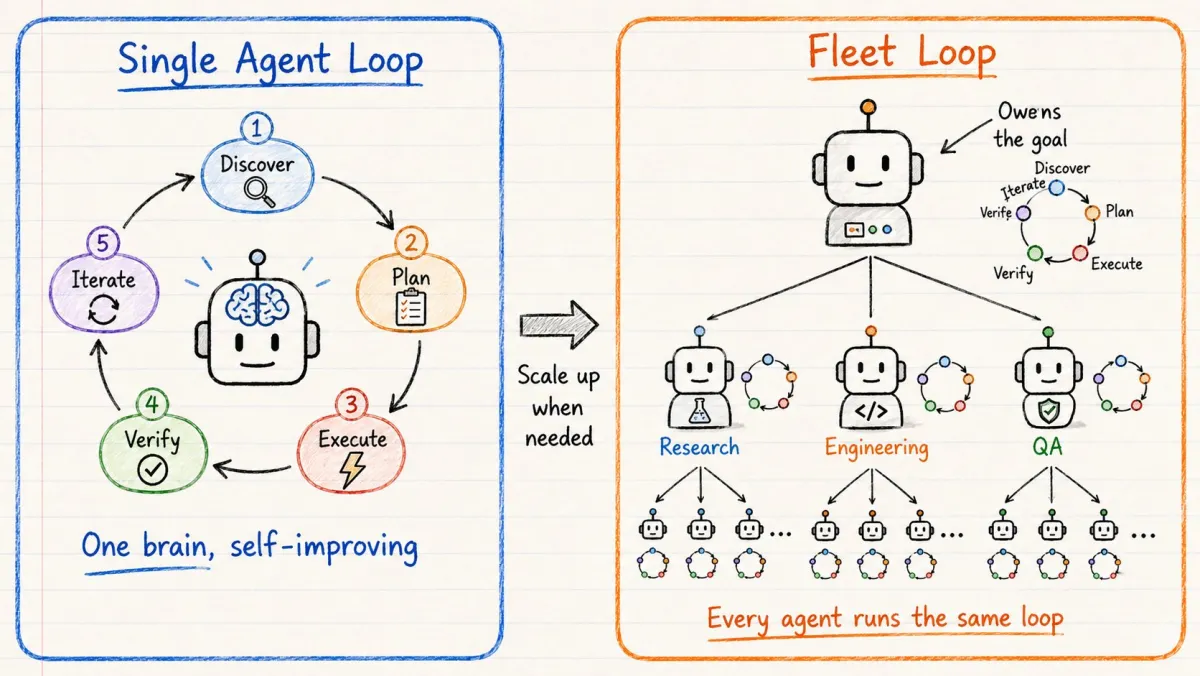
单 agent 循环
一个 agent 独自运行整个周期。
就像一个人重写自己的草稿。
它发现需要什么,规划工作,执行,验证质量,如果发现问题就迭代。
适用于:
- 聚焦的任务
- 简单的目标
- 有限的 scope
一个大脑。一个循环。自我改进。
Fleet 循环
更大的版本是 fleet 循环。
你给编排器 agent 一个目标。
它将目标分解成小块。
将每个块交给 specialist agent。
这些 specialist 将更小的任务交给自己的子 agent。
整个树持续循环——通过发现、规划、执行和验证——直到目标达成。
就像整个团队端到端地运行一个项目。
结构:
- 编排器拥有目标
- Specialist 拥有步骤
- 子 agent 做窄范围的工作
- 评估关卡确保质量
示例:“构建一个生产力应用”
编排器(拥有任务)→ Research / Engineering / QA Specialist → 各自的子 agent(Web 代码编写、测试编写、调试等)
树中的每一个 agent 都运行相同的 5 阶段循环:发现 → 规划 → 执行 → 验证 → 迭代。
重要的是:
单 agent 循环就像一个人重写自己的草稿。
Fleet 循环就像整个团队端到端地运行一个项目。
第四部分:开环 vs 闭环
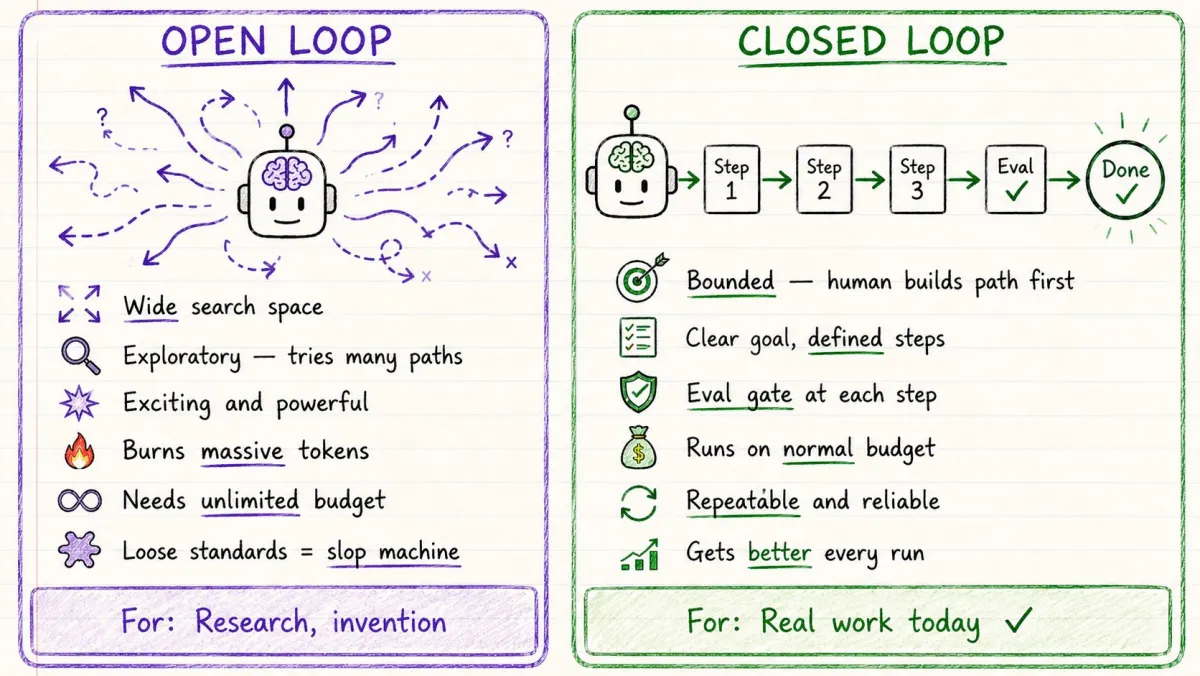
这是 2026 年最重要的实用区别:
并非所有循环都是平等的。
有两种类型。
开环(Open Loop)
探索性的。有广阔的活动空间。
你给 agent 一个目标,让它自由探索。
它可以尝试不同的路径,发现新东西,构建你没有完全规定的东西。
这是令人兴奋的那一面。这就是 Peter Steinberger 和 OpenAI 正在做的事情。
问题?
它消耗的 token 量惊人。
对于 90% 没有无限 API 预算的人来说,开环还不现实。
应用于标准宽松的项目,它会变成垃圾制造机。
快。乱。贵。
闭环(Closed Loop)
有边界的。人类先设计端到端的路径。
- 清晰的目标
- 定义的步骤
- 每一步都有评估
- 一个停止点或交回给你的点
agent 仍然循环——但在你构建的框架内。
每一次运行都会变得更好,因为每次传递会喂给下一次。
它在正常预算下运行,因为路径是紧凑的。
标准让它保持诚实。
没有质量关卡:AI 会偏离。
有质量关卡:AI 会改进。
对于当今大多数实际工作,闭环是那个能带来回报的。
你应该用哪个?
从闭环开始。
构建一个可靠的系统。
然后一旦你有了质量关卡,再打开它。
第五部分:每个好循环的 6 个构建块

每个能持续运行的循环都有这 6 样东西:
概念上循环有 5 个阶段。
但实际你要构建什么来让它运行?
6 样东西。Claude Code 和 Codex 现在都提供了所有这些。
以下是它们——以及每个在循环内部实际做什么。
1. 自动化
这是触发「发现」阶段、启动循环的东西。
循环的心跳。
自动化让循环成为真正的循环——而不仅仅是你做了一次的单次运行。
你定义一个提示、一个节奏和一个目标。
循环按计划运行。结果来找你。你不用去检查。
/loop按节奏重新运行/goal持续运行直到你写的条件为真
给它:“test/auth 中的所有测试通过且 lint 干净”。
走开。
2. Worktrees
这让多个「执行」阶段并行运行而互不干扰。
并行 agent 无混乱。
一旦你运行超过一个 agent,文件就开始冲突。
两个 agent 写同一个文件,就像两个工程师不沟通就改同一行代码。
git worktree 给每个 agent 自己隔离的工作目录和独立分支——相同的仓库历史,零冲突。
一个 agent 的编辑不可能碰到另一个的 checkout。
3. Skills
这让「发现」阶段更快——agent 在开始之前就已经了解你的项目。
不要再每次运行都从零解释你的项目。
Skill 是一个包含 SKILL.md 的文件夹——项目约定、构建步骤、“我们不用这种方式因为那次事故”。
一次写好。每次循环都读取。
没有 skills:循环每次周期都从零重新推导你的整个项目。
有 skills:它不断累积。agent 在开始之前就已经了解你的项目。
- VISION.md——成功是什么样的
- ARCHITECTURE.md——技术栈和文件夹结构
- RULES.md——agent 永远不允许做的事
4. 插件和连接器
这让「执行」阶段变得真实——循环在你的实际环境中行动,而不仅仅是文件系统。
只能看到文件系统的循环是一个微小的循环。
连接器(基于 MCP)让 agent 读取你的 issue 追踪器、查询数据库、访问 staging API、在 Slack 中发消息。
这就是「agent 说‘这是修复方案’」和「循环打开 PR、关联 Linear ticket、CI 变绿后自动通知频道」之间的区别。
5. 子 Agent
这让「验证」阶段保持诚实——检查者和制造者永远不会是同一个 agent。
让制造者远离检查者。
写代码的模型给自己打分时太仁慈了。
第二个具有不同指令——有时是不同的模型——的 agent 能抓到第一个 agent 说服自己放过的错误。
有效的分工:
- 一个 agent 探索
- 一个 agent 实现
- 一个 agent 对照规格验证
这也是 /goal 在底层做的。
一个全新的模型决定循环是否完成——而不是那个做工作的模型。
6. 记忆
这让循环持久化——第 47 次「发现」知道第 1 到第 46 次已经尝试了什么。
整个循环的脊柱。
一个 markdown 文件。一个 Linear 面板。任何存在于单个对话之外的东西。
模型会忘记两次运行之间的一切。
仓库不会。
记忆文件保存着:尝试了什么、通过了什么、还有什么未完成。
明天早上循环从今天停止的地方继续。
这听起来简单到不值得提。
每个长期运行的循环都依赖它。
第六部分:真实的循环示例
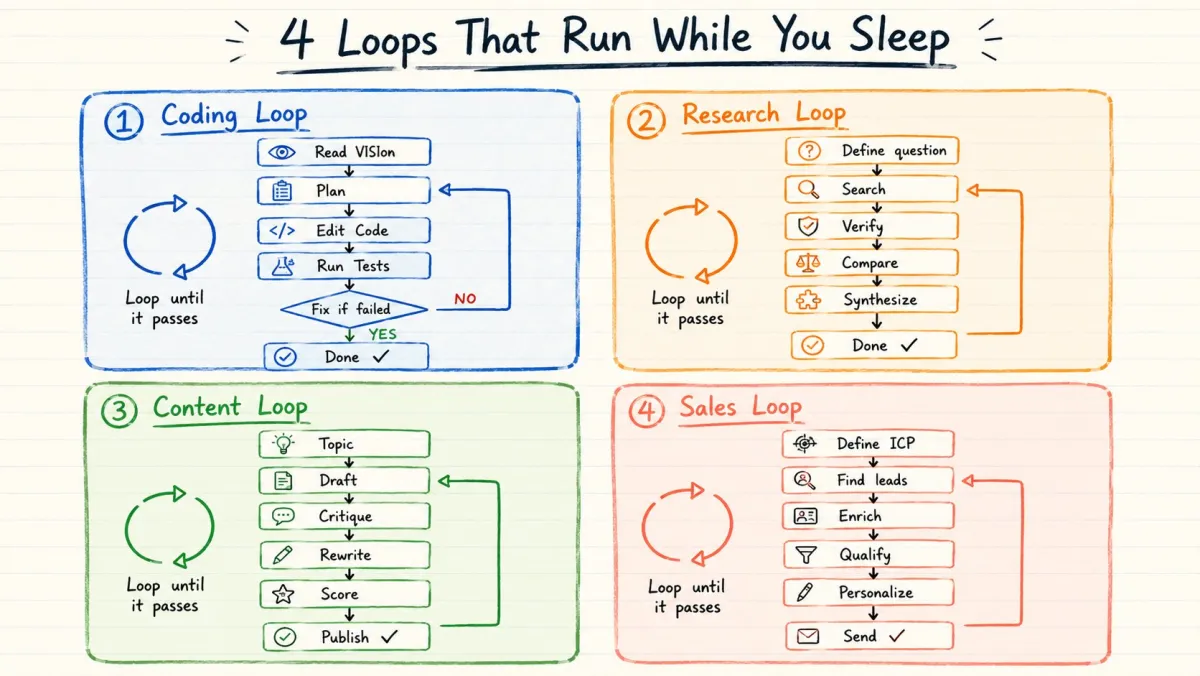
编码循环
读取 VISION.md + ARCHITECTURE.md
↓
规划下一个变更
↓
编辑代码
↓
自动运行测试
↓
如果测试失败 → 读取错误 → 修复 → 重新测试
↓
如果测试通过 → 总结变更
↓
停止没有人在中间。
agent 自己编写、测试、修复和验证。
研究循环
定义研究问题
↓
搜索来源
↓
总结发现
↓
对照来源验证声明
↓
比较冲突信息
↓
综合最终答案
↓
达到置信阈值时停止内容循环
定义主题 + 受众 + 目标
↓
创建草稿
↓
评论 agent 审查草稿
↓
基于评论重写
↓
对照成功标准评分
↓
如果分数通过 → 发布
↓
如果分数失败 → 再次重写销售外联循环
定义 ICP(理想客户画像)
↓
查找匹配画像的潜在客户
↓
用公司数据丰富信息
↓
对照标准筛选
↓
个性化消息
↓
质量审查
↓
发送或升级给人类每个循环都有相同的骨架:
目标 → 行动 → 检查 → 修复 → 重复直到完成。
第七部分:Prompt Engineer vs Loop Engineer
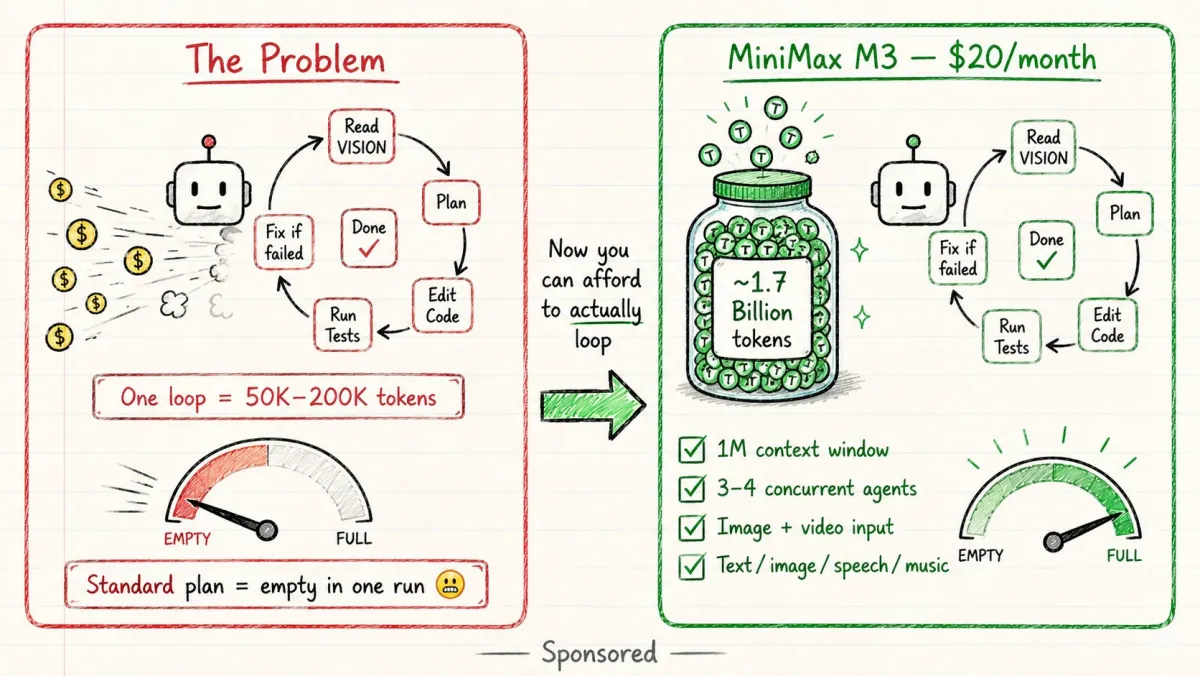
2026 年正在出现的技能差距:
Prompt Engineer
- 编写更好的指令
- 语言技能
- 更好的提示 → 更好的单次输出
- 每次运行后仍然手动审查输出
- 你就是反馈循环
Loop Engineer
- 设计更好的反馈周期
- 软件工程技能
- 更好的循环 → 可靠的经过验证的结果
- 系统运行、检查和自我纠正
- 系统就是反馈循环
Prompt Engineer: “给我写个函数”
Loop Engineer: “写 → 测试 → 修复直到通过”
| Prompt Engineer | Loop Engineer |
|---|---|
| 写更好的提示 | 写 VISION.md |
| 手动审查输出 | 自动审查测试 |
| 运行 agent 一次 | 构建重复系统 |
| 为单次输出付费 | 为验证结果付费 |
工具是一样的。
但思维方式完全不同。
Prompt Engineer 向 AI 索要输出。
Loop Engineer 设计产生验证结果的系统。
2026 年薪酬最高的 AI 工程师不是在写更好的英文句子。
他们在编写控制 agent 如何发现、规划、检查自己工作以及知道何时完成的逻辑。
结语
这就是 Loop Engineering。
让我总结一切:
转变:
- 过去两年我们一次一个任务地提示 agent
- 现在我们设计运行整个周期的循环
你实际构建的 6 样东西:
- 自动化——心跳,触发发现
- Worktrees——并行 agent 无冲突
- Skills——每次运行累积的项目知识
- 插件和连接器——循环在你的真实工具中行动
- 子 agent——制造者和检查者永远不会是同一个 agent
- 记忆——循环在两次运行之间永不忘记
两种规模:
- 单 agent:一个大脑,自我改进
- Fleet:编排器 + specialist + 子 agent——每个 agent 运行相同的循环
两种类型:
- 开环:探索性、强大、昂贵、需要无限预算
- 闭环:有边界、可靠、负担得起、当今能带来回报的
每个好循环的 5 个部分:
- 目标——精确定义「完成」的含义
- 上下文——VISION.md、ARCHITECTURE.md、RULES.md
- 行动——只给 agent 真正需要的
- 反馈——测试、类型检查、linter、结构化错误
- 停止条件——循环知道何时完成
成本问题:
- 循环快速消耗 token
- 在 DeepSeek 上 20 美元比大多数 frontier 模型走得更远
- 这移除了最后一个真正的障碍
重大转变:
- Prompt Engineer 向 AI 索要输出
- Loop Engineer 设计产生验证结果的系统
Peter Steinberger 说得对:
停止提示你的 agent。
开始设计循环。
因为一个可靠的循环胜过一千个完美的提示。
还有一件事没人说出来。
两个人可以构建完全相同的循环,得到完全相反的结果。
一个人用它来在自己深刻理解的工作上更快行动。
另一个人用它来避免理解工作本身。
循环不知道区别。
你知道。
这就是让循环设计比提示工程更难的原因——而不是更简单。
Boris Cherny 的意思不是说工作变容易了。
而是说杠杆点移动了。
构建循环。
但要以打算继续做工程师的人——而不是仅仅按按钮的人——的方式去构建。
因为一个可靠的循环胜过一千个完美的提示。
而有了 20 美元 17 亿 token 的定价,你终于能负担得起构建一个了。

评论互动