Firecrawl 深度调研:开源爬虫为什么开始长成 AI 数据入口

- 将网页转化为 LLM 可直接消费的 Markdown、JSON 和结构化数据
- 通过 API 封装浏览器渲染、内容清洗和反爬策略等复杂操作
- 采用开源核心加托管服务的商业化模式,降低生产环境运维成本
- 定位为 AI Agent 和 RAG 系统的实时网页上下文入口,非通用爬虫银弹
大家好,我是若风。
很多 AI Agent 的第一次翻车,不是模型不会推理,而是它打开网页以后,拿到了一堆没法用的东西。
正文只抓到半截,按钮背后还有懒加载,定价页被 Cookie 弹窗挡住,文档站里混着导航、页脚、推荐链接和脚本噪音。最后模型拿着一坨脏 HTML 开始总结,语气很自信,内容很离谱。
这就是我重新看 firecrawl/firecrawl 时最强的感受。
它很容易被一句话概括:一个开源爬虫项目。这个说法没错,但有点太轻了。因为 Firecrawl 真正有意思的地方,不是“又一个能抓网页的工具”,而是它把传统爬虫里的代理、渲染、清洗、结构化、批处理、搜索和 Agent 接口,重新包装成了一个面向 AI 应用的 Web Context API。
这也是它和很多开源爬虫项目不太一样的地方。
截至 2026 年 5 月 19 日,我从 GitHub API 看到 firecrawl/firecrawl 已经有约 121k Star、7.4k Fork,主语言是 TypeScript,许可证是 AGPL-3.0。它的官网 firecrawl.dev 也不是一个纯开源项目主页,而是一个完整的商业化产品入口:有云端 API、Playground、SDK、MCP、CLI、文档和定价页。
换句话说,Firecrawl 是一个典型的新一代开源商业项目:
核心能力开源,复杂运维收费;开发者可以自托管,但大多数真实团队会为“少踩坑”买单。
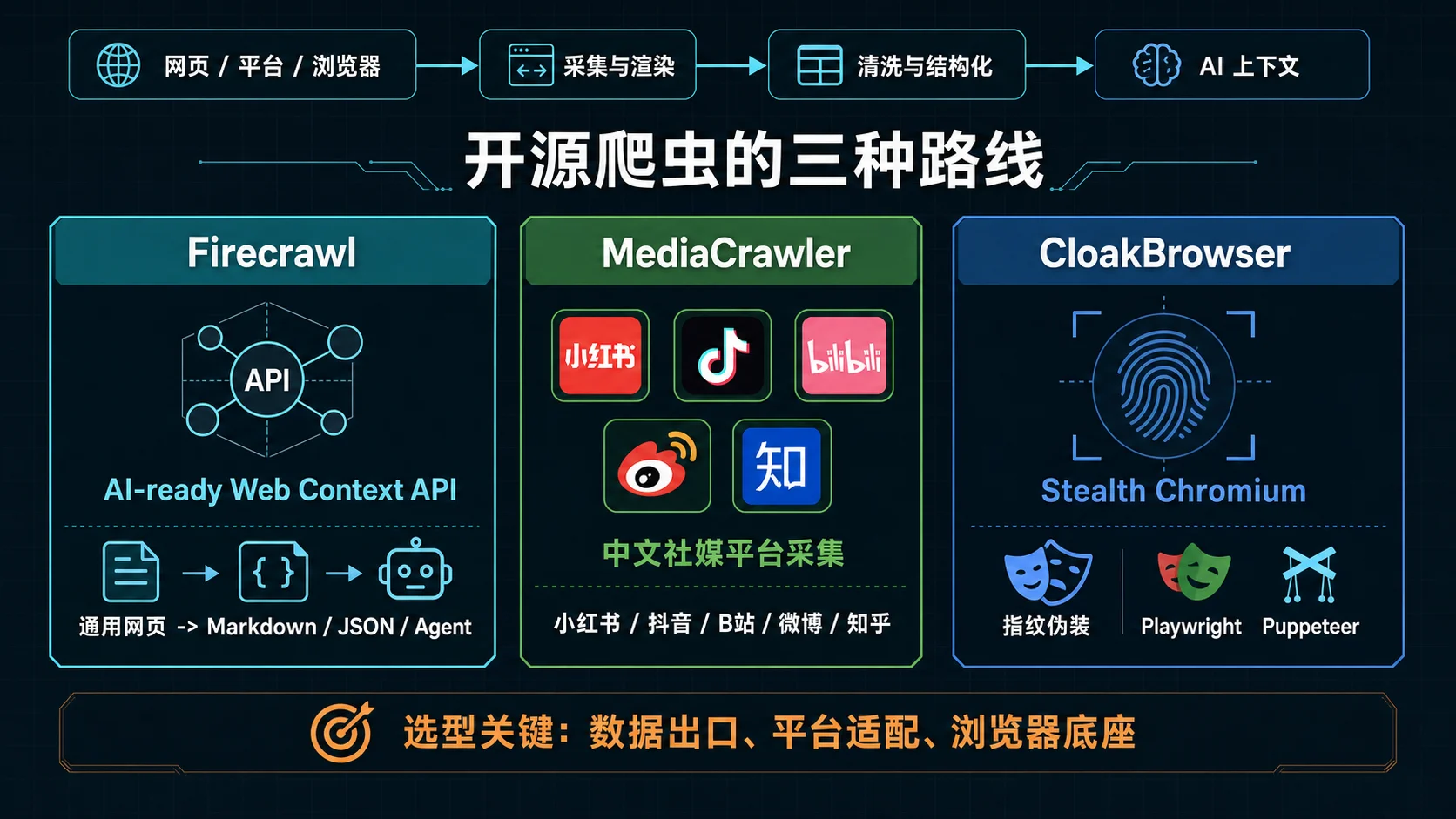
这篇文章我会围绕 3 个问题展开:Firecrawl 到底解决了什么问题,它为什么适合 AI Agent 和 RAG 工作流,以及它和 NanmiCoder/MediaCrawler、CloakHQ/CloakBrowser 这两个爬虫相关项目相比,边界分别在哪里。
先说结论
Firecrawl 不是一个“给你一把浏览器自动化锤子”的项目。
它更像一个把网页变成模型可用上下文的基础设施层。
传统爬虫关心的是:我能不能把网页抓下来。
Firecrawl 关心的是:我能不能把网页变成 LLM 能直接消费的 Markdown、JSON、截图、结构化数据和可追溯来源。
这个差别很关键。
因为 AI 应用不只是需要 HTML。HTML 里有导航栏、广告、弹窗、脚本、重复区块、懒加载内容、埋点代码,还有一堆对模型没有意义的噪音。真正昂贵的不是“请求一个 URL”,而是把这个 URL 变成干净、稳定、便宜、可重复使用的上下文。
所以我会把 Firecrawl 放在这样的位置上:
| 项目 | 核心定位 | 更像什么 | 适合谁 |
|---|---|---|---|
| Firecrawl | AI-ready Web 数据入口 | Web Context API / 爬虫基础设施 | 做 Agent、RAG、搜索、市场情报、自动研究的团队 |
| MediaCrawler | 中文社媒平台数据采集 | 多平台社媒采集脚本集合 | 学习、研究、公开信息采集实验 |
| CloakBrowser | 反检测浏览器自动化底座 | Stealth Chromium / Playwright 替代层 | 被反爬、指纹检测、自动化识别卡住的工程团队 |
如果用一句话区分:
Firecrawl 解决“网页怎么变成 AI 数据”,MediaCrawler 解决“中文内容平台怎么抓”,CloakBrowser 解决“浏览器自动化怎么更像真人”。
这三者都和爬虫有关,但它们其实站在三条不同的产业链位置上。
Firecrawl 到底是什么
Firecrawl README 对自己的描述很直接:Search, scrape, and clean the web for AI agents。它提供的能力也不是单一的 scrape,而是一组端点:
- Search:搜索网页并返回结果内容。
- Scrape:把单个 URL 转成 Markdown、HTML、截图或结构化 JSON。
- Crawl:抓取一个网站的多个页面。
- Map:发现站点里的 URL。
- Batch Scrape:异步处理一批 URL。
- Interact:先抓页面,再执行点击、滚动、输入、等待等动作。
- Agent:直接描述你要找什么,由系统自己搜索、导航和提取。
如果只是看功能列表,Firecrawl 像是把 Scrapy、Playwright、Readability、代理池、队列和结构化抽取拼在一起。
但它真正的产品感来自一个取舍:它不要求用户先理解爬虫系统的每个零件,而是把复杂性折叠进 API。
你不需要先决定什么时候用静态请求、什么时候上浏览器、什么时候换代理、什么时候等待 JS 渲染、什么时候清理正文。你给它 URL 或任务,它尽量返回可用内容。
这对 AI 应用尤其重要。
很多 Agent demo 看起来很聪明,真正接到互联网就开始翻车。原因不是模型不会总结,而是上游数据太脏:页面抓不到、正文不完整、JS 没渲染、Cookie 弹窗挡住内容、同一个页面重复抓、抓完是一坨 HTML,最后模型拿着垃圾上下文一本正经地胡说。
Firecrawl 想做的就是这层“垃圾处理厂”。
这个比喻不太浪漫,但很准确。AI 应用越往生产走,越会发现数据入口比提示词更难。Prompt 可以迭代,模型可以换,但如果网页上下文不稳定,后面所有链路都会变脆。
为什么它会在 AI 时代突然变重要
过去讲爬虫,大家通常想到的是搜索引擎、价格监控、内容采集、舆情系统、数据集构建。
这些场景还在,但 AI 把爬虫的需求形态改了一下。
以前的爬虫更像 ETL:定时抓、清洗、入库、做分析。
现在很多 AI Agent 要的是实时上下文:用户问一个问题,系统马上去查网页、读文档、比价格、找资料、交叉验证,然后把结果整理回来。
这时爬虫不再只是后台任务,而变成模型推理过程的一部分。
Firecrawl 的设计正好踩在这个变化上。它不只是提供 Python、Node.js、Java、Rust 等 SDK,也提供 MCP Server、CLI 这类入口。这个信号很明显:它不是只想服务传统数据工程师,而是想进入 Cursor、Claude Code、OpenCode、各种 MCP 客户端和 AI Agent 的工具链。
我觉得这也是它能快速增长的原因之一。
在 AI 编程和 Agent 工作流里,“访问真实网页”正在变成一个基础能力。开发者不想每次都重新写 Playwright 脚本,也不想维护代理、浏览器池、正文提取、失败重试和反爬策略。Firecrawl 把这些包成一个 API,开发者买到的其实是时间和确定性。
它的开源和商业化套餐,张力在哪里
Firecrawl 是开源项目,但不是“公益型开源工具”。
GitHub 仓库使用 AGPL-3.0 许可证,代码可以看、可以自托管、可以改。但官网同时提供商业化云服务。公开定价页显示,它有 Free、Hobby、Standard、Growth、Scale / Enterprise 等不同套餐,围绕 credits、并发能力、支持级别和企业需求做区分。具体价格和额度会变,所以真正选型时还是要以官网实时页面为准。
这类模式的核心逻辑是:开源解决信任和传播,托管服务解决复杂运维。
如果你只是做实验,自托管当然很有吸引力。你可以把 Firecrawl 接到自己的队列、数据库和模型系统里,成本也更可控。
但一旦进入生产,账就变了。
爬虫系统最麻烦的部分往往不是代码能不能跑,而是失败率、并发、队列、代理质量、页面渲染成本、重试策略、反爬变化、结果质量和监控。你今天抓 100 个页面没问题,不代表明天抓 10 万个页面还能稳定。你今天抓官网文档没问题,不代表抓电商、社媒、招聘、地图、SaaS pricing 页面也一样顺。
所以 Firecrawl 的商业化不是简单卖“代码的云版本”。
它卖的是一组开发者不想长期背在身上的麻烦:
| 麻烦 | 自托管时你要自己处理 | 云服务替你吸收的部分 |
|---|---|---|
| JS 渲染 | 浏览器池、资源占用、超时 | 托管渲染和调度 |
| 代理与反爬 | 代理质量、失败重试、封禁 | 代理和请求编排 |
| 批量任务 | 队列、状态、并发控制 | Batch / Crawl 状态管理 |
| 内容清洗 | 正文抽取、Markdown 转换、噪音过滤 | LLM-ready 输出 |
| 结构化抽取 | Schema 设计、失败回退 | JSON / Agent 输出 |
| 可观测性 | 日志、成本、错误定位 | Dashboard / 支持 |
这也是为什么开源和商业不一定冲突。
真正的分界线不在“能不能抓”,而在“你愿不愿意为稳定抓付钱”。
和 MediaCrawler 比:一个是平台化 API,一个是中文社媒采集工具箱
MediaCrawler 是另一个很火的爬虫项目。截至 2026 年 5 月 19 日,它在 GitHub 上约 49.8k Star、10.5k Fork,主语言是 Python。项目 README 里写得很清楚:它支持小红书、抖音、快手、B 站、微博、贴吧、知乎等主流平台的公开信息抓取。
它和 Firecrawl 的差异不是“谁更强”,而是服务对象完全不同。
MediaCrawler 更像一个面向具体中文内容平台的采集工具箱。它的价值在于平台适配:登录态、平台参数、页面结构、内容类型、评论、视频、帖子、问答等。
Firecrawl 则更像一个通用网页上下文 API。它不专门围绕某一个平台深挖,而是把“任意网页转成 AI 可用数据”做成统一接口。
这会带来两个结果。
第一,MediaCrawler 在中文社媒场景里更贴近目标平台。你要采集小红书笔记、抖音视频评论、微博帖子,通用 scrape API 未必知道你真正想要什么字段,MediaCrawler 这种项目反而更有针对性。
第二,Firecrawl 在 AI 应用集成上更顺手。你不一定关心平台字段,只关心“给我可读正文、来源、结构化结果、批量抓取状态、搜索结果内容”,那 Firecrawl 的 API 抽象更省事。
我会这样选:
| 场景 | 更适合 |
|---|---|
| 做中文社媒平台研究、学习平台采集技术 | MediaCrawler |
| 做 AI Agent 的网页读取工具 | Firecrawl |
| 做企业内部 RAG 的外部网页补充 | Firecrawl |
| 针对某个平台长期维护字段和评论采集 | MediaCrawler 或自研适配器 |
还有一个不得不说的点:MediaCrawler README 里有非常醒目的免责声明,强调仅供学习和参考,禁止商业用途和非法用途。这个提醒不只是法律话术,也是在告诉开发者:爬虫不是“能写就能用”,平台条款、数据合规、频率控制和授权边界都要自己承担。
和 CloakBrowser 比:一个处理数据出口,一个处理浏览器伪装
CloakBrowser 更不一样。
它不是传统意义上的爬虫框架,而是一个 Stealth Chromium。项目 README 的核心卖点是:不是配置层补丁,也不是 JS 注入,而是在 Chromium C++ 源码层修改指纹,让 Playwright / Puppeteer 自动化更像正常浏览器。截至 2026 年 5 月 19 日,它在 GitHub 上约 14.8k Star,MIT 许可证,主语言是 Python。
所以 CloakBrowser 的位置更底层。
Firecrawl 关心的是“我拿到网页以后,怎么输出干净数据”。CloakBrowser 关心的是“我怎么不在第一步就被识别成机器人”。
这两者甚至可以组合:Firecrawl 这类系统内部可能需要浏览器、代理和反检测策略;CloakBrowser 这类项目则可以作为某些高阻抗页面的浏览器执行层。
但它们给开发者的抽象完全不同。
Firecrawl 是高层 API,你把任务丢进去,拿结果。
CloakBrowser 是低层能力,你仍然要自己写 Playwright / Puppeteer 脚本、处理页面逻辑、抽取字段、重试、入库和清洗。
这也是我对它的判断:
| 你遇到的问题 | 更像 Firecrawl | 更像 CloakBrowser |
|---|---|---|
| 不想写爬虫,只想拿干净 Markdown / JSON | 是 | 否 |
| 已经有脚本,但被指纹识别、Turnstile、BrowserScan 卡住 | 否 | 是 |
| 需要接入 Agent / MCP / RAG | 是 | 需要自己封装 |
| 需要最大程度控制浏览器行为 | 不一定 | 是 |
| 需要低成本、大规模自建采集管道 | 视场景 | 可能更适合作为底层组件 |
不过 CloakBrowser 这类工具也更敏感。
它的能力天然接近反检测、指纹伪装、自动化绕过。合法的 QA、安全研究、反欺诈测试、数据可用性测试当然存在,但滥用空间也很大。对团队来说,技术上能跑通只是第一步,更重要的是把授权、用途、频率和数据处理边界写清楚。
Firecrawl 的技术价值:把脏活变成 API
我最喜欢 Firecrawl 的地方,不是它某个单点能力多酷,而是它承认爬虫是一个系统问题。
很多爬虫项目的问题,是把“抓网页”描述得太简单。
好像发一个 HTTP 请求,解析一下 DOM,事情就结束了。
真实世界不是这样。
真实网页会有:
- 客户端渲染,HTML 首屏没内容。
- Cookie 弹窗、登录墙、地区提示、年龄确认。
- 无限滚动、懒加载、点击展开。
- 反爬检测、速率限制、IP 风控。
- 结构频繁变化,选择器今天能用明天就断。
- 正文和导航、推荐、广告混在一起。
- 同一站点不同页面模板完全不同。
Firecrawl 的路线是把这些不确定性尽量包进平台层,然后给开发者一个相对稳定的输出协议。
它不一定每次都比你手写脚本更便宜,也不一定适合所有极端定制场景。但对于大量 AI 应用来说,它把“从 0 到能用”的路径缩短了很多。
尤其是当你的目标不是构建一个爬虫公司,而是构建一个产品功能时,这个抽象很有价值。
你做一个竞品监控、销售线索研究、文档问答、行业新闻分析、招聘信息聚合、投资研究助手,最不想做的就是先花两周搭浏览器集群和清洗管道。Firecrawl 的价值就在这里:它让你先把产品闭环跑起来。
但它也不是银弹
Firecrawl 适合 AI 数据入口,不代表它适合所有爬虫任务。
如果你有很稳定的目标站点、很明确的字段、很大的规模、很强的成本敏感度,自研或专用爬虫可能更合适。
如果你采集的是强平台属性数据,比如社媒评论、视频信息、用户关系链、互动数据,通用网页抽取也未必够。这个时候 MediaCrawler 这种平台适配项目,或者自己写平台-specific pipeline,可能更接近需求。
如果你的主要瓶颈是反检测,而不是内容清洗,CloakBrowser 这种底层浏览器能力会更贴近问题。
还有一个现实点:商业 API 的计费模型会改变工程判断。
Firecrawl 的 credits 机制很适合快速启动,但到高频、重复、大规模采集时,你必须算账:哪些页面可以缓存,哪些任务适合自托管,哪些任务只在失败时调用托管 API,哪些内容根本不应该抓。
我更推荐把 Firecrawl 当成一个“默认入口”和“兜底能力”,而不是无脑把所有网页访问都丢进去。
一种更稳的架构可能是:
| 任务类型 | 推荐策略 |
|---|---|
| 少量实时网页理解 | 直接用 Firecrawl |
| RAG 外部资料补充 | Firecrawl + 缓存 + 来源记录 |
| 大规模固定站点采集 | 自研 pipeline,Firecrawl 做失败兜底 |
| 中文社媒公开内容研究 | 专用平台爬虫 + 合规审查 |
| 反检测压力大的浏览器任务 | Playwright / CloakBrowser 类底座 + 自定义抽取 |
这比单纯问“Firecrawl 好不好”更有用。
工具没有绝对好坏,只有它站在系统里的哪一层。
我会怎么用它
如果我在一个 AI 产品里引入 Firecrawl,我不会一上来就把它当全站爬虫。
我会先从 3 个低风险场景开始。
第一,做实时资料补充。
比如用户问某个开源项目、产品定价、API 文档变化,系统先用 Firecrawl search / scrape 拉回来源,再让模型基于来源回答。这里最重要的是速度和可追溯,不是抓得多。
第二,做 RAG 的外部文档入口。
很多团队的知识库不只在内部文档,也散落在官网、GitHub README、博客、release note、API docs。Firecrawl 可以负责把这些页面转成 Markdown,再进入分块、嵌入和索引流程。
第三,做失败兜底。
如果已有采集系统抓不到某些 JS-heavy 页面,或者临时要读一个新站点,Firecrawl 可以作为“高成本但省时间”的兜底 API。等需求稳定以后,再决定要不要沉淀成自研采集器。
这也是我对这类工具比较现实的态度。
不要一开始就追求最省钱。
也不要永远依赖最省事。
先用托管 API 换速度,等模式稳定以后再把高频路径内化。这是很多开源商业工具最舒服的使用方式。
最后
Firecrawl 的流行,表面上是一个开源爬虫项目的增长。
但更深一层,它反映的是 AI 应用栈里一个新位置正在变重要:Web Context Layer。
模型需要上下文。
上下文需要来源。
来源在真实网页里。
而真实网页,远比一个 URL 看起来脏得多。
Firecrawl 把这件脏活产品化了:你可以自己部署,也可以为托管能力付费;你可以把它当爬虫,也可以把它当 Agent 的眼睛;你可以用它快速启动,也可以在规模化以后拆出更精细的自研路径。
这就是我觉得它值得看的原因。
它不是因为“能爬网页”而重要。
而是因为 AI 产品越往真实世界走,越需要一个可靠的数据入口。
Firecrawl 只是把这句话,提前做成了 API。

评论互动