Claude Code 真正吃掉额度的,不是你的那句 Prompt
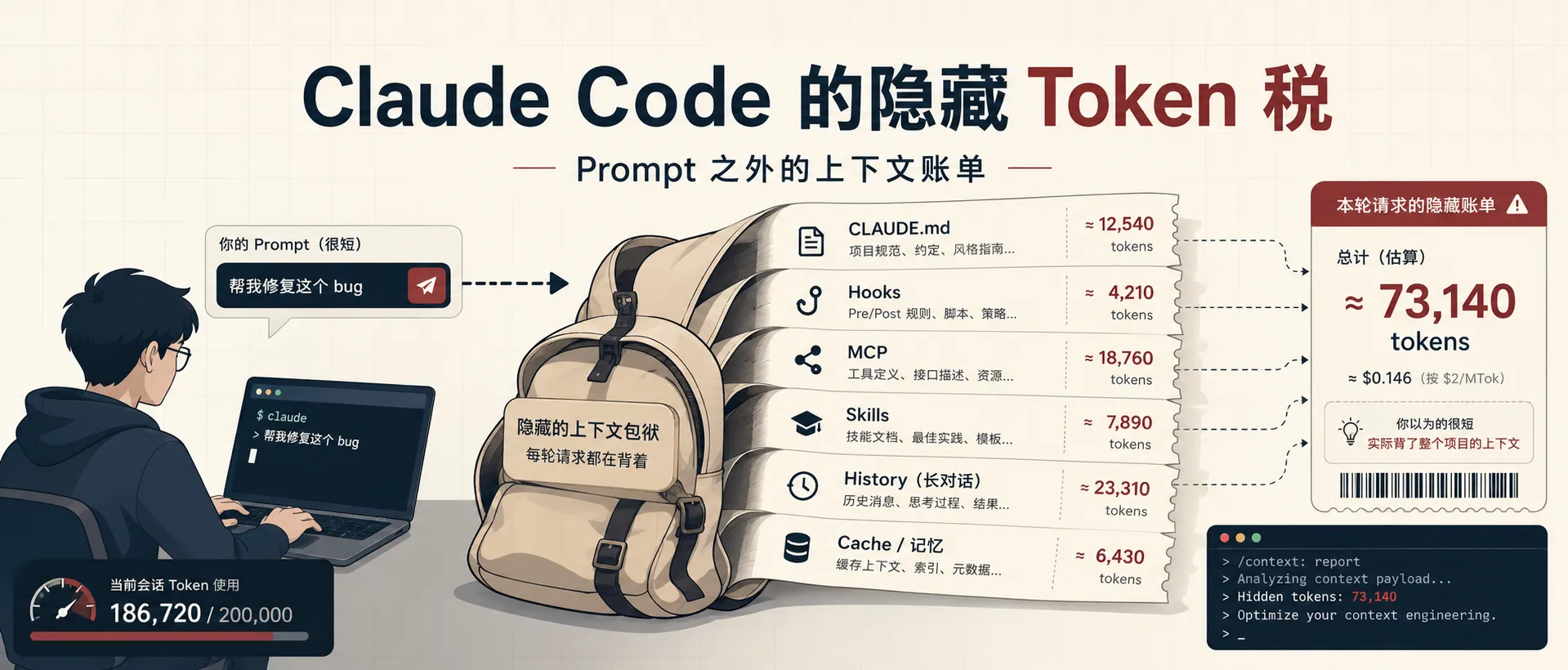
- 真正消耗额度的是每轮请求的固定上下文开销,而非用户输入的prompt
- CLAUDE.md、MCP、hooks等每轮都会加载,形成隐形token成本
- 优化应聚焦减少每轮请求的固定上下文,而非仅缩短prompt
- 按需启用MCP、精简CLAUDE.md、审查hooks注入内容、及时切段长对话
- 上下文不是敌人,无差别常驻的上下文才是敌人,需做context engineering
Karpathy 的 4 条 CLAUDE.md 规则将 Claude 错误率从 41% 降低到 11%。在修改了 30 个代码库之后,我又添加了 8 条规则。
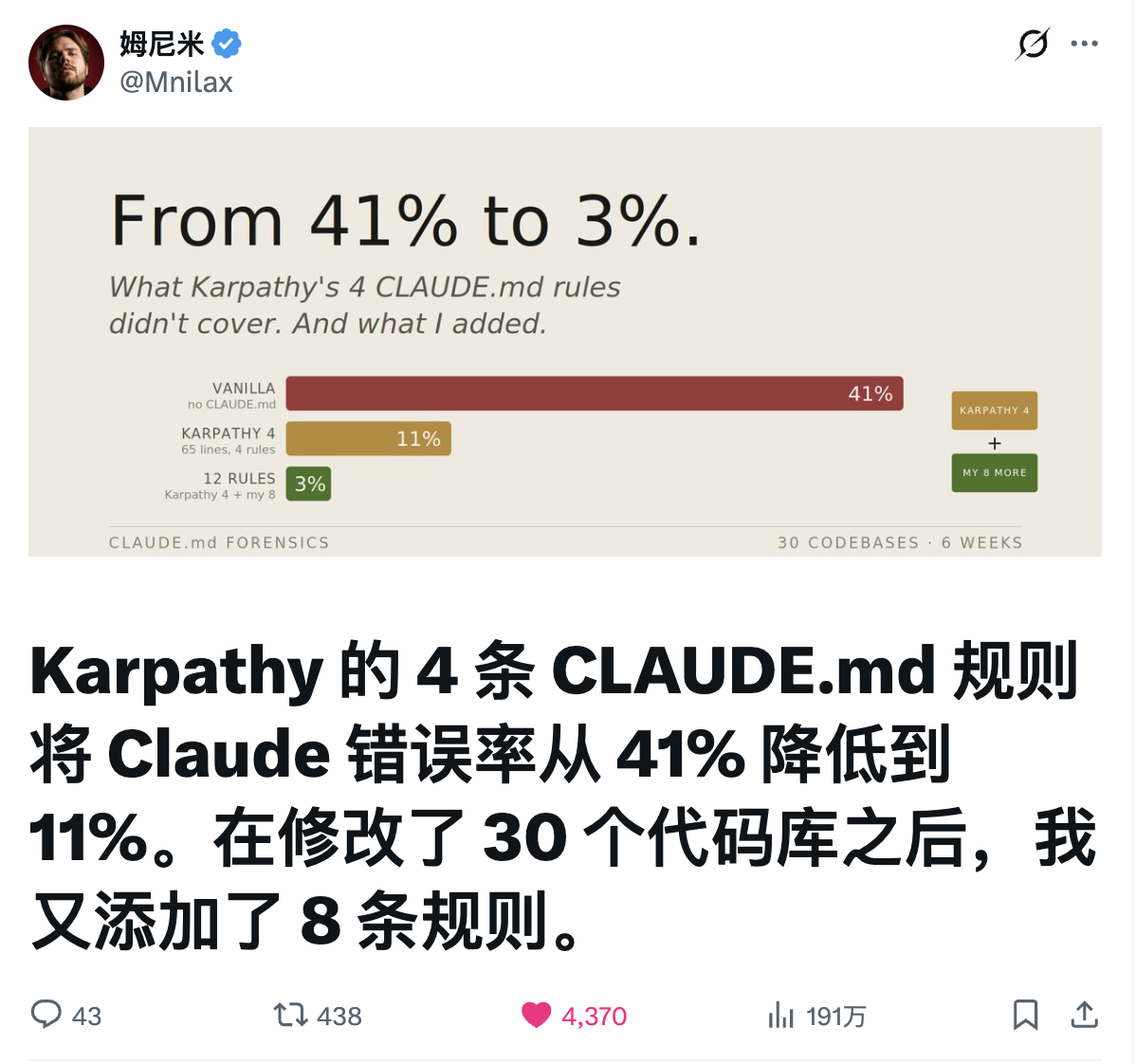
这条推文最近在 X 上被广泛转发。很多人关注的是「怎么写规则」,但很少有人追问一个更根本的问题:这些规则每轮请求都要带上,它们到底花了多少 token?
Mnimiy 的这篇 X Article 最有价值的地方,不是又给了一堆「省额度技巧」,而是把问题往下挖了一层——他发现,真正吃掉你额度的,往往不是你输入的那句 Prompt。
很多人用 Claude Code 时,第一反应是:
- 我是不是问得太频繁?
- 我是不是应该多用 Haiku?
- 我是不是应该少开几个会话?
- 我是不是应该更勤快地
/clear?
这些建议都没错,但它们只是在上层省钱。
Mnimiy 做了一件更狠的事:把代理接在 Claude Code 和 Anthropic API 中间,连续观察真实请求链路。可公开检索到的转述提到,他记录了大约 90 天、430 小时的使用数据,结论非常刺眼:大量 token 根本不是花在你刚输入的那句 Prompt 上,而是花在每一轮请求都会预付的上下文开销上。
换句话说,你以为你在为「这次提问」付费,实际上你还在为整个工具链的默认上下文付费。
真正的泄漏点:每轮请求都会重新带上的东西
Claude Code 不是一个简单的聊天框。
它是一个 agentic coding harness。它要知道你的项目规则,要知道当前分支,要知道可用工具,要知道 MCP server,要知道 hooks 注入的信息,要知道历史对话。
这些能力很好用,但问题是:能力越多,每轮请求的固定成本也越高。
根据公开转述,真正的「漏水点」包括这些:
CLAUDE.md每轮都会加载;UserPromptSubmithooks 会注入分支状态、最近文件、记忆片段;- MCP server 会把工具 schema 带进请求,即使这轮任务根本用不到;
- Skills 可能因为相关性判断偏保守而自动加载;
- 对话历史会在后续消息里持续占用上下文;
- 缓存一旦失效,你就重新为这些内容付费。
这就解释了一个很多人都遇到过的现象:明明只是让 Claude 改一行代码,额度却掉得比想象中快。
因为模型看到的不是「改一行代码」这么简单。
它看到的是:你的系统提示词、项目规则、工具列表、hooks 上下文、MCP schema、历史对话,再加上你那一句「帮我改一下」。
CLAUDE.md 很有用,但它不是免费的
我之前一直强调 CLAUDE.md 的价值:它能把项目规则沉淀下来,让 Claude Code 少犯重复错误。
这个判断仍然成立。
但这篇文章提醒了另一个现实:长期规则也是成本。
如果你的 CLAUDE.md 写成了一篇 3,000 字宣言,每次请求都会带上大量口号式内容,那它不只是「没帮助」,还是稳定扣费项。
一个好的 CLAUDE.md 应该像工程规则,不像企业文化墙。
坏例子:
我们追求卓越的软件工程质量,坚持可维护、可扩展、可读性强的代码风格,在开发过程中保持严谨、负责、专业的态度……这类话人看了都没法执行,模型看了也只能消耗 token。
好例子:
- 修改前先读相关测试。
- 只做当前任务需要的最小改动。
- 命令失败必须停止并报告,不要包装成完成。
- 新增依赖前必须说明必要性,并等待确认。规则越短,越像约束;规则越长,越像噪音。
MCP 的问题:工具越多,不代表越强
MCP 很容易让人上头。
文件系统、浏览器、数据库、GitHub、Linear、Notion、Figma、搜索、监控……能接的都想接上。
但从 token 视角看,MCP 不是「装了不用就没成本」。很多 agent harness 需要把工具说明、参数 schema、调用约束等上下文提供给模型,这样模型才知道什么时候能调用什么工具。
所以,如果你接了 12 个 MCP server,即使当前任务只是改一个 CSS class,也可能要为一堆无关工具的描述付出上下文成本。
这不是说 MCP 不该用。
而是说 MCP 应该像生产依赖一样管理:
- 当前项目真的需要吗?
- 这个 server 是不是只在少数任务用到?
- 能不能按工作区拆分,而不是全局常驻?
- 能不能把高频工具和低频工具分开?
- 能不能定期清理不用的 server?
工具越多,agent 的行动空间越大;但工具越多,每轮推理前要解释的世界也越大。
Hooks 和 Skills:自动化也会制造隐形账单
Hooks 和 Skills 的问题更隐蔽。
它们往往是为了提升体验:自动注入分支信息、最近修改、任务记忆、项目约定、工作流说明。
一开始你会觉得很爽,因为 Claude 好像更懂你了。
但过一段时间,项目会变成这样:
- 每个 prompt 前都塞一点 Git 状态;
- 每个 prompt 前都塞一点最近文件;
- 每个 prompt 前都塞一点记忆;
- 每个 prompt 前都自动加载几个可能相关的 skill;
- 每个 prompt 前都带上之前越滚越长的对话。
这些东西单独看都不大,叠在一起就是固定税。
而且最麻烦的是:用户通常看不到这笔税。
你在输入框里只看见一句话,API 请求里却可能已经塞了一大包上下文。
为什么你感觉「额度消失得不合理」
这篇文章真正解释的是一种体感:
我明明没问多少,为什么 Claude Code 又到限制了?
答案可能不是你问得太多,而是每次问的基础包太大。
可以把一次 Claude Code 请求想象成点外卖:
- 你点的菜:当前 prompt;
- 包装费:系统提示词;
- 配送费:项目规则;
- 平台服务费:工具 schema;
- 会员附加项:hooks 和 skills;
- 历史订单备注:对话上下文;
- 缓存失效:本来能免的费用又重新收一遍。
最后账单比菜本身贵,你当然会觉得离谱。
怎么优化:不要只省 prompt,要省上下文
如果这篇文章只留下一句话,我会选这句:Claude Code 的额度优化,不是少说几句话,而是减少每轮请求的固定上下文。
下面是我会立刻执行的检查清单。
1. 把 CLAUDE.md 删短
保留真正改变模型行为的规则,删掉价值观作文。
建议控制在 30-80 行以内。不是绝对数字,但足够提醒你:这个文件不是知识库,不是项目百科,也不是新人手册。
如果内容很长,拆出去:
- 高频规则放
CLAUDE.md; - 低频文档放
docs/; - 特定任务流程放 skill;
- 需要时再让 Claude 读取。
2. MCP 按项目启用,不要全局堆满
全局 MCP 只保留你每天都会用的工具。
项目专用工具放项目配置。低频工具需要时再开。测试完一个 MCP server,如果不用,就删掉。
一个简单原则:如果一个工具连续一周没被调用,它就不该常驻。
3. 检查 hooks 到底注入了什么
很多 hooks 写着写着就膨胀了。
一开始只注入分支名,后来加入最近提交、最近文件、任务状态、TODO、环境变量、测试摘要……最后每次 prompt 前都塞一页纸。
把 hooks 当成生产代码审查:
- 注入内容是否真的每轮都需要?
- 有没有重复信息?
- 有没有可以按条件触发?
- 有没有从「摘要」退化成「全文粘贴」?
4. 长对话及时切段
长对话不是免费上下文。
如果一个任务已经完成,开新会话。如果任务进入新阶段,让 Claude 先写一个短 handoff,再切到新会话继续。
不要把「需求讨论、实现、调试、重构、发版、复盘」全塞在同一个无限长对话里。
5. 用便宜模型处理低价值步骤
这条是老建议,但仍然有效。
不是所有任务都需要最强模型:
- 查找文件;
- 总结日志;
- 整理待办;
- 格式化文档;
- 生成简单脚本;
- 批量替换文本。
这些任务可以交给更便宜的模型或确定性脚本。把最贵的模型留给架构判断、复杂 debug、跨文件推理和高风险改动。
但别走向另一个极端
看到这里,很容易得出一个错误结论:那我把所有上下文都删掉,只保留 prompt,不就最省了吗?
不对。
上下文不是敌人,无差别常驻的上下文才是敌人。
CLAUDE.md、MCP、Hooks、Skills 都是好东西。没有它们,Claude Code 就会退化成一个会写代码的聊天框。
真正的问题是:
- 什么信息应该常驻?
- 什么信息应该按需读取?
- 什么工具应该默认可见?
- 什么工具应该任务触发?
- 什么规则值得每轮请求都付费?
这就是 context engineering。
不是「多给上下文」,也不是「少给上下文」,而是让正确的信息在正确的时刻出现。
我的结论
这篇文章最值得警惕的地方,是它拆掉了一个幻觉:
我输入框里只有 20 个字,所以这次请求应该很便宜。
在 Claude Code 这种 agentic coding 工具里,这个直觉经常是错的。
你输入的是 20 个字,但系统发送的可能是一个完整工作台:项目规则、工具说明、MCP schema、hooks 状态、skills 内容、历史对话,全都跟着走。
所以,接下来优化 Claude Code,不要只盯着「我怎么问得更短」。
更应该问:
- 哪些上下文每轮都在重复发送?
- 哪些 MCP 工具其实没必要常驻?
- 哪些 hooks 注入了过量信息?
- 哪些规则可以从常驻文件挪到按需文档?
- 哪些任务根本不需要最贵模型?
省 token 的关键,不是让人少说话。
而是让系统少带包袱。

评论互动