AI 时代的反向三定律:别把判断力外包给模型
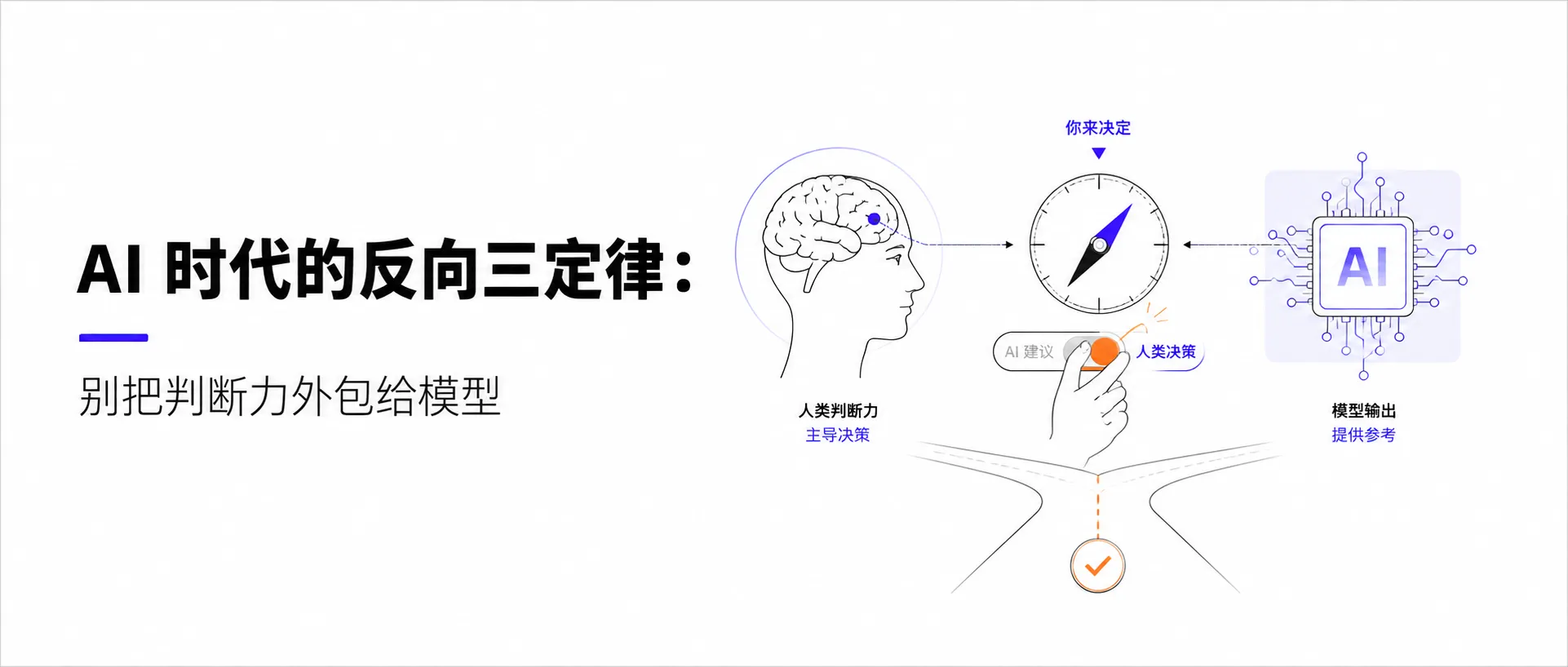
- 守住判断力是AI时代核心能力,而非提问技巧
- 不要把AI当人,它是工具而非责任主体
- 不要把AI输出当结论,必须经过验收和验证
- 不要把责任推给AI,最终由人承担后果
- Prompt决定上限,验收决定下限,花更多时间验证
2023 年,纽约一位律师在法庭上提交了一份法律文书,引用了多个判例。法官查了一下,发现这些判例全部不存在——全是 ChatGPT 编造的。律师的辩解是:我不知道它会编案例。
这个新闻当时被当成笑话传播。但如果你在日常工作中用过 AI,你可能也经历过那种瞬间:一个答案看起来严丝合缝,直到你亲自去验证才发现它错得离谱。
我自己踩过一个类似的坑。有一次让 AI 查一个 npm 包的 API 用法,它给出了一段代码,方法名、参数类型、返回值看起来都像模像样。我直接用了,运行时报错——那个方法根本不存在于那个包的任何版本里。AI 把两个不同库的 API 拼在了一起,生成了一个看起来正确但不存在的接口。
它不会像编译器那样抛一个冷冰冰的 Error,而是用温和的语气端出一个看起来完美无缺的答案。它不再像过去的搜索引擎那样给你一堆链接让你自己挑,而是直接把“结论”摆在你面前。
这当然很好用。
但也正因为太好用,它会让人慢慢忘记一件事:AI 替你降低的是生成成本,不是判断成本。
先说结论
AI 时代真正重要的能力,不是会不会提问,而是能不能守住判断力。
过去一年,很多讨论都在讲 Prompt。
怎么写指令,怎么给角色,怎么拆步骤,怎么让模型输出 JSON、Markdown,怎么让 Claude Code 或 Codex 更稳定地完成任务。
这些当然有用。我自己也每天用。
但我越来越觉得,Prompt 只是第一层。更长期的能力是验收,是判断,是能不能在一个答案写得很顺时,仍然停下来问一句:它到底对不对?
Susam Pal 的三条反向定律,可以压成三句中文:
- 不要把 AI 当人
- 不要把 AI 的输出当结论
- 不要把责任推给 AI
这三条听起来简单,但它们正好卡住了今天所有 AI 工作流里最核心的风险。
第一条解决的是关系错位——AI 是工具,不是同事。
第二条解决的是认知偷懒——AI 会生成答案,但不自动生成事实。
第三条解决的是责任边界——你可以让 AI 帮你写、帮你查、帮你改,但最后署名、提交、发布、发送的人还是你。
当然,三条之间也有张力。为了让 AI 输出更好,你有时需要给它角色和上下文——这看起来和“不要拟人化”有点矛盾。时间紧迫时,你不可能逐条验证——这又和“不要盲从”拉扯。但理解这些张力本身就是使用 AI 的一部分:原则不是教条,而是在具体场景里做取舍的参考线。
如果只把 AI 当“效率工具”,这三条就够用了。如果要把 AI 接进生产系统、研发流程、内容发布和客户沟通里,这三条就更像底线。
第一条:不要把 AI 当人(Non-Anthropomorphism)
今天很多 AI 产品都在往“人”的方向设计。
它有名字,有头像,有语气,有记忆,有时候还会表现得很体贴。你问它一个问题,它会先肯定你,再一步步展开。你指出它错了,它会说抱歉,然后给出一个新版本。
这些交互体验很顺,但也会制造一个错觉:你正在和一个理解世界、理解责任、理解后果的对象对话。
实际上不是。
AI 没有生活经验,没有真实处境,也没有自己的责任感。它只是根据输入、上下文和训练中学到的模式,生成一个看起来合理的输出。
这不是贬低它。恰恰相反,只有把它放回工具的位置,才能真正用好它。
你不会因为编译器报错语气很冷,就觉得它不尊重你。也不会因为搜索引擎返回了十条结果,就认为它“相信”第一条。我们早就习惯把这些系统当工具使用。
但 AI 的自然语言界面太像人了,所以它比搜索引擎和编译器更容易诱导你建立错误关系。
这种拟人化倾向不仅发生在工具使用场景里。在消费文化和内容产业中,它被刻意放大了。
数字偶像歌手 Yuri 就是一个极端案例。

AI.TALK 官网把 Yuri 称作“国内首位 AI 原生歌手”,首支单曲全网播放突破 1100 万次,粉丝量接近 80 万,已经进入品牌合作和商业化场景。官方 YouTube 视频标题直接写着 Completely AI-Generated Music Video——画面、运镜、口型到舞台感,几乎和真实偶像无异。
问题就在这里:当一个 AI 数字人能唱歌、营业、拥有稳定人设,人会很自然地把“作品真实感”误读成“主体真实性”。但 Yuri 没有自己的生活经验、创作意图和责任能力,真正做决策的始终是背后的人类团队。
所以 Yuri 不是在削弱“不要把 AI 当人”这条原则,反而是在强化它:AI 越能模拟人,我们越要清楚哪里是表演,哪里是系统,哪里才是真正承担责任的人。
一旦把它当人,很多判断都会变形。
它说得很笃定,我也会更容易信。
它说“我建议”,我也会下意识把它当专家。
它说“我理解你的意思”,我也会以为它真的理解了我的业务约束。
这也是为什么我越来越不喜欢用“AI 同事”这个比喻。它适合做产品营销,不适合做工作方法。
更准确的说法是:AI 是一个高带宽的草稿生成器、检索辅助器、结构化助手和推理模拟器。
它可以加速你,但不能替你成为那个负责的人。
第二条:不要把 AI 的输出当结论(Non-Deference)
很多人用 AI 出问题,不是因为不会问,而是因为太快接受答案。
AI 最擅长的是给你一个“看起来已经完成”的东西。
一段解释,一份表格,一段代码,一个总结,一封邮件,一套方案。它通常不会像一个初级同事那样留下明显粗糙的痕迹,反而会把内容整理得很完整。
这很有用,也很危险。
因为完整感会降低警惕。
尤其是在你不熟悉的领域,AI 的输出很容易变成一种“语气上的权威”。它把答案写得越顺,你越不容易意识到里面可能有错。
开头提到的律师案例就是极端版本:AI 不仅编造了判例,还给每个编造的判例配上了看起来很正规的引用格式。如果不是法官亲自去查,这些“判例”在文书里看起来和真实的一模一样。
所以我觉得所有 AI 工作流都应该默认加一层验收,而不是默认信任。
写代码时,验收层是测试、类型检查、构建、代码审查。
写文章时,验收层是来源、日期、数字、原文上下文。
做调研时,验收层是一手资料、交叉验证和反例搜索。
做产品方案时,验收层是用户场景、约束条件和落地成本。
也就是说,AI 给你的不是结论,而是一个候选版本。
你要做的不是“看它像不像对”,而是问:这个输出经过了什么验证?
这里面有一个很实用的判断标准:凡是可以自动验证的东西,尽量不要只靠人工感觉。
代码能跑测试,就跑测试。
数据能查来源,就查来源。
链接能打开,就打开。
API 用法能看官方文档,就看官方文档。
事实能追到原始出处,就不要停在二手转述。
但更难的部分,是那些不能自动验证的东西。
AI 给你一个架构方案,没有测试能告诉你它三年后还能不能撑住。AI 帮你分析一个市场,没有 CI 能跑出“这个结论有没有遗漏关键变量”。AI 写了一份产品路线图,没有 linter 能检查它是否忽略了组织内部的政治成本和迁移成本。
这些地方只能靠人的经验、直觉和领域知识。而这恰恰是“判断力”真正发挥作用的区域——不是检查拼写错误,而是在信息不完整的情况下做取舍。
AI 会让产出速度变快,但速度越快,越需要验收层跟上。否则你只是把错误生产得更快。
第三条:不要把责任推给 AI(Non-Abdication of Responsibility)
这是最重要的一条。
“AI 让我这么做的”不是一个有效解释。
如果你把 AI 生成的代码合进主分支,最后负责的是你。
如果你把 AI 总结的内容发给客户,最后负责的是你。
如果你把 AI 给出的数字写进文章,最后负责的是你。
如果你把 AI 生成的结论拿去影响产品、招聘、投资、医疗、法律、教育这些高风险决策,最后负责的仍然是你。
AI 可以成为过程的一部分,但不能成为责任主体。
这件事在开发者场景里特别明显。
以前你复制 Stack Overflow 上的代码,代码炸了,不能说“Stack Overflow 让我复制的”。现在你复制 AI 写的代码,出了问题,也不能说“模型这么生成的”。
工具不会替你承担上线事故。
我之前让 AI 帮我写一段处理用户数据的逻辑,代码跑通了,测试也过了。后来 code review 时才发现,它在某个边界条件下会把用户的邮箱明文写进日志。AI 不知道这是隐私问题——它只是按照我描述的功能生成了一个技术上正确的实现。但最后负责的人是我。
更现实的是,AI 生成的东西经常处在一种很尴尬的中间态:它不是完全随机的,也不是完全可靠的;它不是没有价值,也不是天然可信的。
人类的责任没有减少,反而变得更集中。
过去你可能要亲自写一百行代码,所以错误分散在写作过程中。现在 AI 一次生成一百行,你的责任就集中在“是否接受、如何验证、要不要发布”这几个决策点上。
这也是 AI 工具真正改变工作方式的地方。
它减少了生成成本,但提高了判断成本。
Prompt 是第一层,验收才是护城河
很多 AI 教程喜欢讲 prompt。
怎么写指令,怎么给角色,怎么拆步骤,怎么让模型输出 JSON,怎么让它先思考再回答。
这些当然有用,但它们只是第一层。更长期的能力是验收。
Prompt 决定的是 AI 输出的上限。验收决定的是你最终产出的下限。
我自己有一个明显的变化:用 AI 越久,花在验收上的时间比例越高。刚上手时,大部分时间在调 prompt,扫一眼结果就过了。现在可能反过来——几分钟描述清楚需求,然后花大量时间逐条确认输出对不对。
这不是效率变低了,而是对“什么可能出错”的感知变敏锐了。
也是在这个过程中,我越来越确定一件事:未来几年真正拉开差距的不是“谁会问 AI”,而是“谁会验收 AI”。
不会用 AI 的人,会慢。
只会让 AI 生成的人,会快但不稳。
真正厉害的人,是能把 AI 的生成能力接到自己的判断系统里。
这些能力看起来没有 Prompt 技巧那么酷,但它们才决定 AI 产出能不能进入真实世界。
可以把这三条落成工作流
这三条反向定律不是口号,可以直接变成日常工作流。
如果是写代码,我会这样用:
- 让 AI 先给方案,不直接改核心路径
- 让 AI 生成测试或补充边界条件
- 本地跑测试、类型检查和构建
- 对安全、权限、数据迁移这些地方人工复查(之前让 AI 改过一次权限配置,漏了一个边界条件,差点上线出事)
- 合并前确认自己能解释每一处关键改动
如果是写文章,我会这样用:
- 让 AI 先提纲,不直接当成最终稿
- 所有数字、日期、公司名、产品能力追原始来源
- 对二手报道保留“据报道”“媒体称”这类边界
- 不确定的地方宁可删掉,也不要让语气显得过度肯定(AI 特别擅长用笃定的语气说不确定的事)
- 最后用自己的结构和判断重写,而不是保留模型腔
如果是做调研,我会这样用:
- 先让 AI 帮我铺地图
- 再找一手资料确认关键节点
- 专门让它找反例和风险
- 把“事实”“判断”“猜测”分开写
- 最后只保留自己能承担的结论
这套流程看起来慢一点,但它能避免最糟糕的情况:你以为自己在提效,实际上只是把未经验证的东西包装得更漂亮。
AI 越强,人越不能偷懒
这也是 Susam Pal 原文最打动我的地方。
它没有陷入“AI 是好是坏”的老问题,而是换了一个更实用的角度:当 AI 越来越像人,我们反而更需要提醒自己,它不是人。
这件事放到更大的历史里看,也不新鲜。
人类一直有把不确定性外包给权威的冲动。以前可能是占卜,后来是专家,再后来是搜索引擎,现在是 AI。
我们都想要一个声音告诉自己:放心,就这么做。
因为自己判断太累了,承担后果也太痛苦了。
但 AI 的出现没有取消这件事,只是把它放大了。
当然,AI 在变好,幻觉率在下降。但问题不在于它经常错,而在于你不知道它哪次会错。一个 99% 可靠的系统,剩下 1% 的错误如果恰好落在你没有验证的那个盲区,代价可能比 50% 的错误率还高——因为你已经完全信任它了。
它能生成更多选择,也会制造更多需要判断的候选项。它能让你更快进入工作状态,也可能让你更快接受一个未经验证的答案。
所以 AI 越强,人越不能偷懒。
这里的“不偷懒”,不是说所有事情都要手工做一遍,而是不要把最后那一下判断交出去。
写在最后
如果你本来就有判断,AI 会让你的判断跑得更快。
如果你本来就没有判断,它也会让你的混乱跑得更快。
这才是 AI 时代最公平、也最残酷的地方。
你可以大量使用它——搜索、总结、写草稿、写代码、找漏洞、提建议。AI 最好的状态,不是替你思考,而是把你的思考放大。
但你不能把它当成责任主体。
Susam Pal 的三条反向定律,说到底是一件事:在使用 AI 的每一个环节里,守住“最后做判断的那个人是我”。
这个判断不会因为 AI 变得更强而自动出现。恰恰相反,AI 越强,你越需要主动维护它。
因为真正危险的不是 AI 犯错,而是你在它犯错的时候,已经完全信任了它。

评论互动