Harness、LLM、Token、Agent、MCP…AI 圈最烧脑的 8 个概念,一文彻底讲透
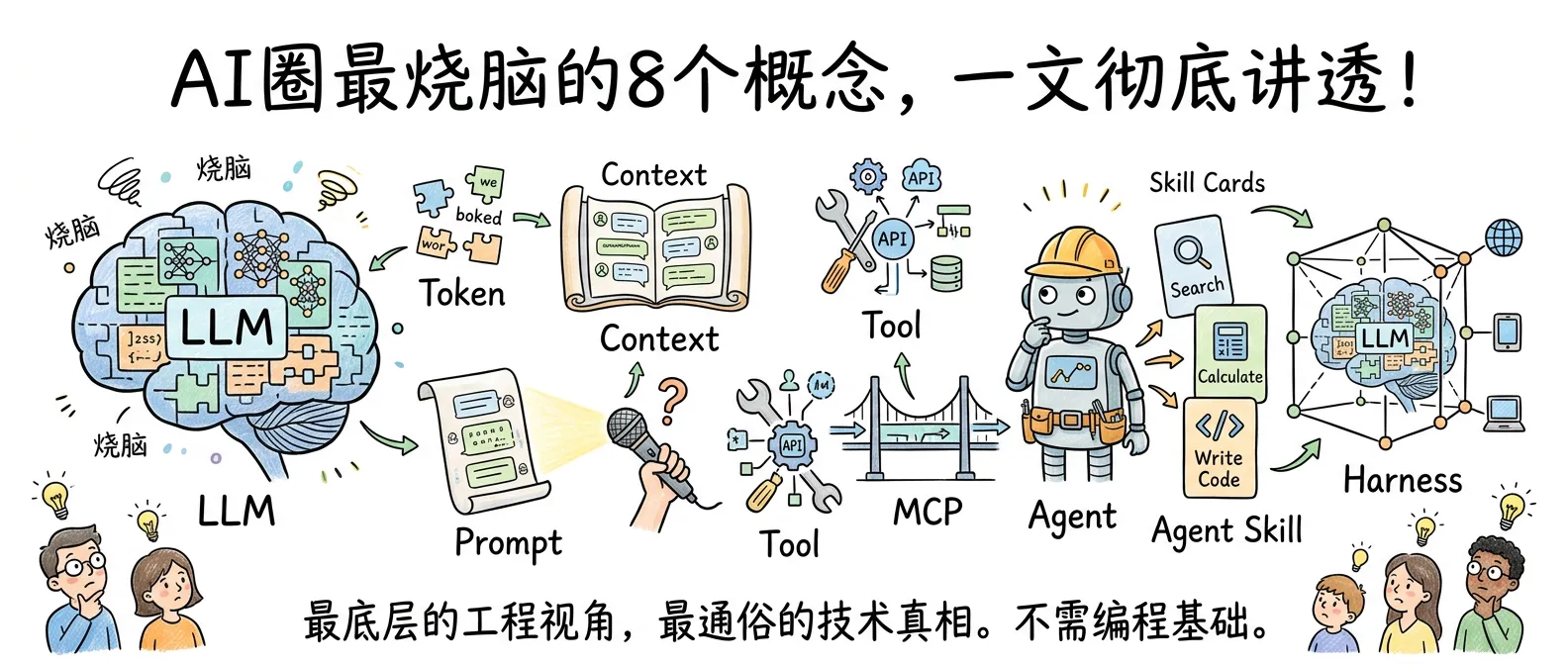
- LLM本质是预测下一个词的文字接龙引擎,基于Transformer架构
- Token是数据处理最小单元,1个Token约0.75英文单词或1.5-2汉字,直接关联成本
- Context是大模型临时记忆体,Context Window限制可处理信息量,超长文档需RAG技术
- Harness是Prompt的进化版,为AI提供完整工作手册,定义身份、规则、工具和输出格式
- Agent能自主规划并调用多个Tool完成任务,Agent Skill是预置说明书实现自动化
你有没有这种感觉——AI 圈每天都在冒新名词,刷着刷着就觉得自己落后了。
LLM、Token、Context、Prompt、Tool、MCP、Agent、Agent Skill、Harness……
随便拎一个出来,很多人其实说不太清它到底指的是什么。
更扎心的是,你以为你懂了,但一深入追问,发现全是模糊的。
这篇文章,我从最底层的工程视角出发,把 AI 的核心概念一个个拆开讲透。没有虚头巴脑的商业概念,只有最底层的技术真相。看完这篇,你对 AI 的理解会上升一个台阶。
本文适合:对 AI 感兴趣但概念模糊的普通人。不需要编程基础,我会用最通俗的方式讲清楚每一个概念。
一、最底层:LLM 大语言模型
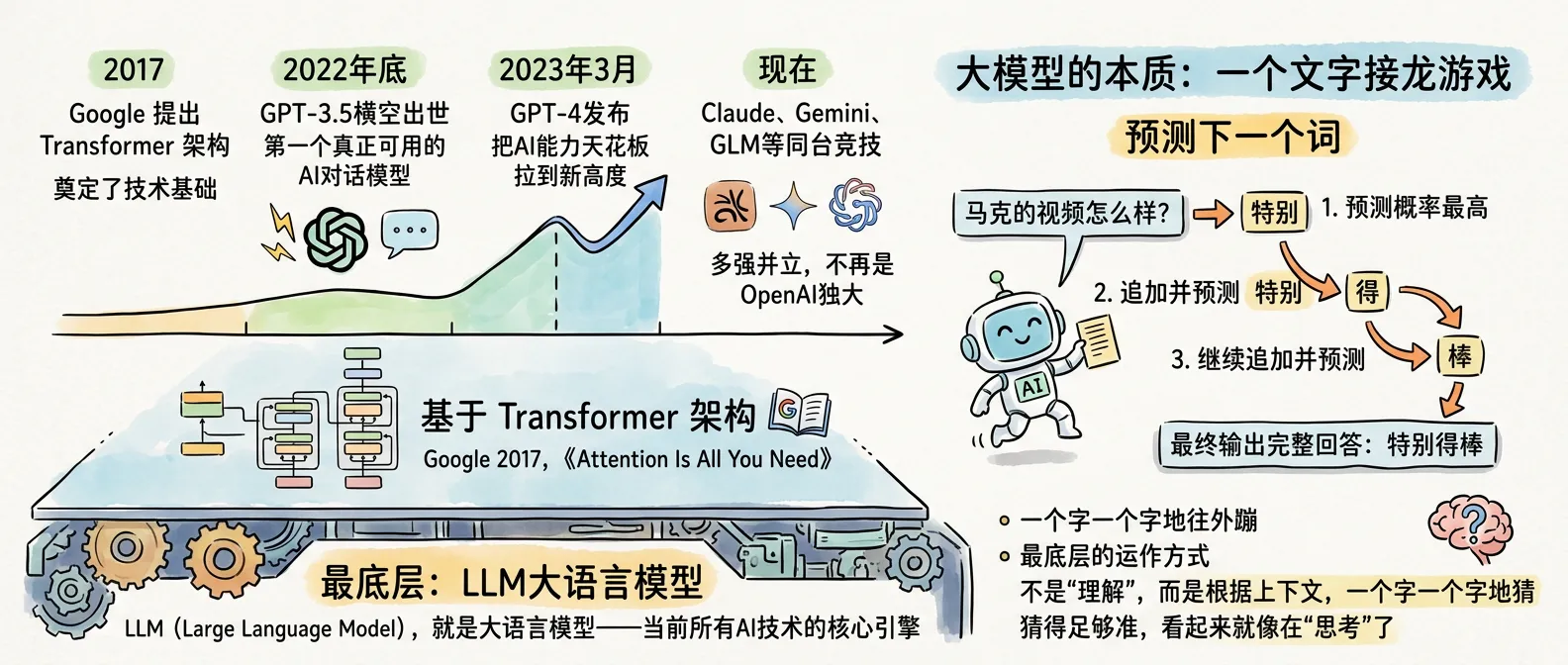
LLM(Large Language Model),就是大语言模型——当前所有 AI 技术的核心引擎。
市面上几乎所有大模型,都基于一个叫 Transformer 的架构训练而成。这个架构是 Google 团队 2017 年提出的,论文叫《Attention Is All You Need》。但真正把 LLM 引爆全球的,是 OpenAI。
几个关键时间点:
| 时间 | 事件 | 意义 |
|---|---|---|
| 2017 年 | Google 提出 Transformer 架构 | 奠定了技术基础 |
| 2022 年底 | GPT-3.5 横空出世 | 第一个真正可用的 AI 对话模型 |
| 2023 年 3 月 | GPT-4 发布 | 把 AI 能力天花板拉到新高度 |
| 现在 | Claude、Gemini、GLM 等同台竞技 | 多强并立,不再是 OpenAI 独大 |
大模型的本质:一个文字接龙游戏
说穿了极其朴素:大模型就是一个“预测下一个词”的机器。
你问它“马克的视频怎么样?”,它的工作过程是这样的:
- 预测下一个概率最高的词:“特别”
- 把“特别”追加到输入后面,再预测下一个词:“的”
- 继续追加,再预测:“棒”
- 最终输出完整回答:“特别的棒”
这就是为什么你用 ChatGPT 的时候,它是一个字一个字地往外蹦——因为这就是它最底层的运作方式。
它不是“理解”了你的问题再“思考”答案,而是根据上下文,一个字一个字地猜接下来最可能出现的字。猜得足够准,看起来就像在“思考”了。
二、大模型的“翻译官”:Token 与 Tokenizer
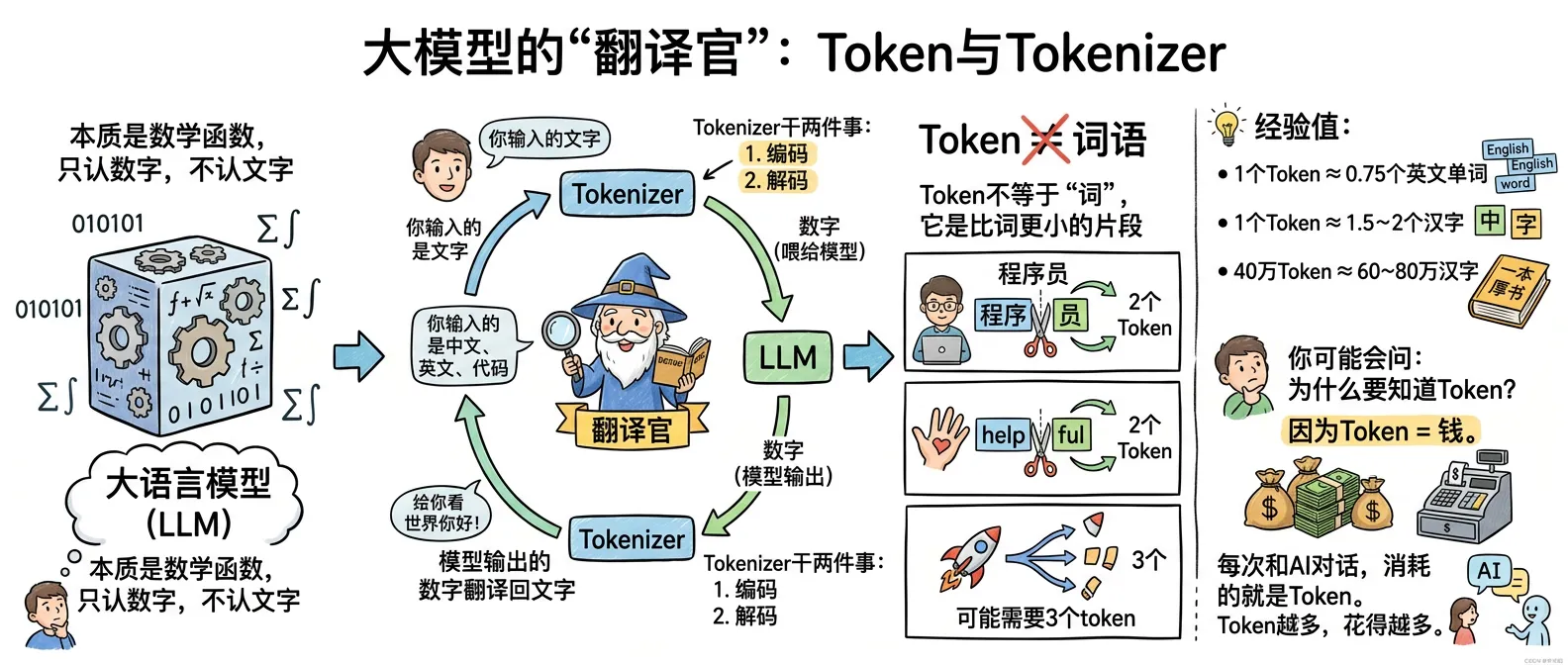
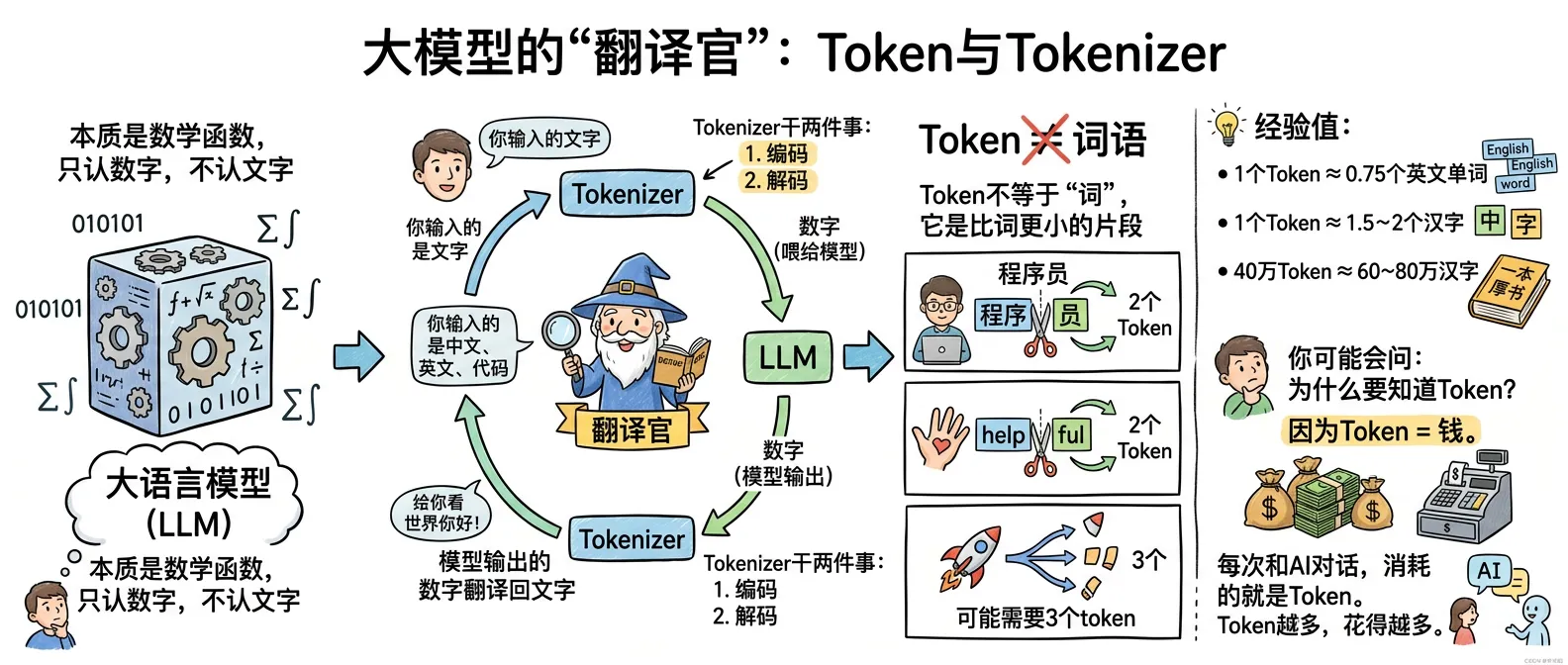
大模型本质上是数学函数,它只认数字,不认文字。
那问题来了:你输入的是中文、英文、代码,模型怎么“看懂”?
答案就是 Tokenizer——人类和模型之间的翻译官。
Tokenizer 干两件事:
- 编码:把你输入的文字翻译成数字(喂给模型)
- 解码:把模型输出的数字翻译回文字(给你看)
Token ≠ 词语
这是很多人搞混的地方。Token 不等于“词”,它是比词更小的片段。
看几个真实例子:
| 输入 | Token 切分 | Token 数量 |
|---|---|---|
| “程序员” | “程序” + “员” | 2 个 |
| “helpful” | “help” + “ful” | 2 个 |
| 一个特殊符号 | 可能需要 3 个 token | 3 个 |
经验值:
- 1 个 Token ≈ 0.75 个英文单词
- 1 个 Token ≈ 1.5~2 个汉字
- 40 万 Token ≈ 60~80 万汉字(相当于一本厚书)
你可能会问:为什么要知道 Token?因为 Token = 钱。每次和 AI 对话,消耗的就是 Token。Token 越多,花得越多。了解 Token,才能用明白 AI 的成本。
三、临时记忆体:Context 与 Context Window
Context(上下文)= 大模型每次处理任务时接收到的所有信息的总和。
包括什么?比你想象的多:
- 你当前问的问题
- 之前的对话记录
- 模型正在生成的 Token
- 可用的工具列表
- System Prompt(开发者给你设的人设和规则)
- ……等等一切
Context Window = 这个记忆体能装下的最大 Token 数量。
| 模型 | Context Window | 约等于多少汉字 |
|---|---|---|
| GPT-4.5 | 105 万 Token | ~150 万汉字 |
| Claude 3.1 Pro | 100 万 Token | ~150 万汉字 |
| GLM 系列 | 视版本而定 | - |
150 万汉字是什么概念?能装下整个《哈利波特》全集。
那超长文档怎么办?
比如你要 AI 分析一份上千页的产品手册,不可能全塞进去。这时候就需要 RAG 技术(检索增强生成):
RAG 的核心思路:不把整本书给模型看,只把和问题最相关的几页摘出来给它。
- 从文档中搜索和你的问题最匹配的片段
- 只把这些片段发给模型
- 模型基于这些片段回答你的问题
既突破了 Context Window 的限制,又控制了成本。
这里不对 RAG 概念做深入阐述,因为这又是一门专门的学科:RAG 工程
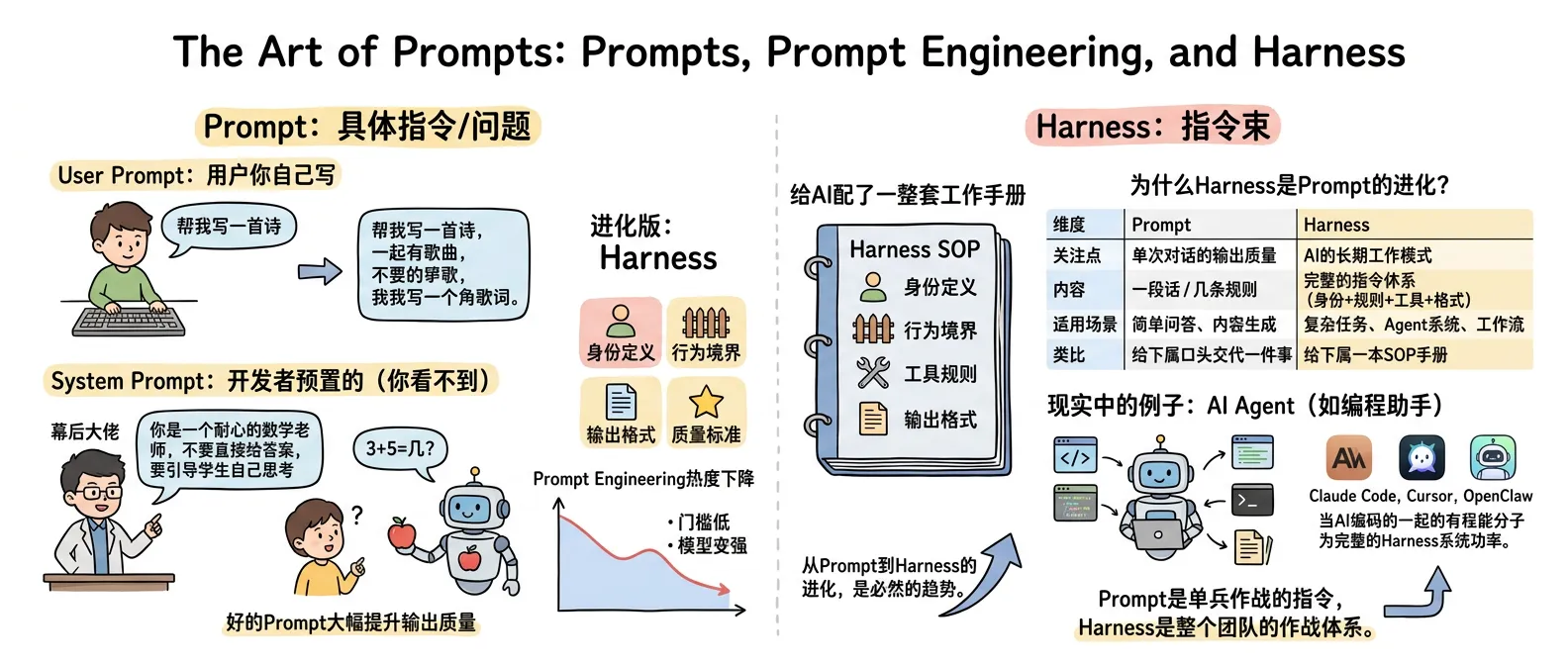
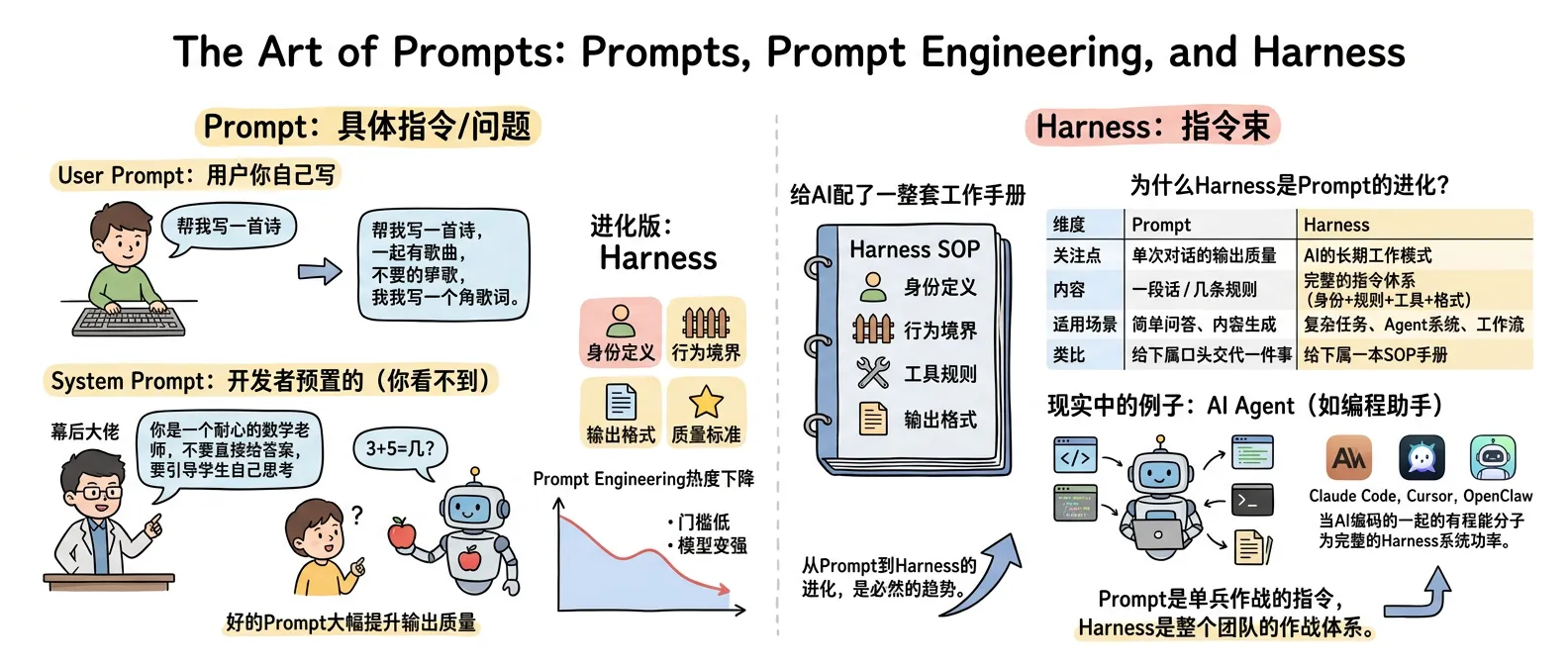
四、指令的艺术:Prompt、Prompt 工程与 Harness
Prompt = 你给大模型的具体指令或问题。
它分两种:
| 类型 | 谁写的 | 例子 |
|---|---|---|
| User Prompt | 用户你自己 | “帮我写一首诗” |
| System Prompt | 开发者预置的(你看不到) | “你是一个耐心的数学老师” |
Prompt 写得好不好,差别有多大?
举个最直观的对比:
模糊 Prompt: “帮我写一首诗” → 可能生成现代诗、打油诗、文言诗……你得不到想要的结果
精准 Prompt: “请帮我写一首五言绝句,主题是秋天的落叶,风格要明亮一点” → 精准命中你的需求
5W1H 原则:
| 要素 | 英文 | 说明 | 示例 |
|---|---|---|---|
| What | 什么 | 要做什么任务 | 写一首诗 |
| Who | 谁 | 目标受众是谁 | 给小学生看 |
| When | 何时 | 时间背景 | 秋天 |
| Where | 何地 | 地点场景 | 公园里 |
| Why | 为何 | 目的是什么 | 用于作文 |
| How | 如何 | 具体要求 | 五言绝句 |
System Prompt 才是真正的“幕后大佬”
开发者可以预设一套规则,比如:“你是一个耐心的数学老师,不要直接给答案,要引导学生自己思考。”
这时候你问“3+5=几?”,模型不会直接说“8”,而是回答:
“可以这样想:你手里有 3 个苹果,又拿了 5 个,现在一共有多少个?可以数一数。”
它不是在“装”,是 System Prompt 在背后操控它的行为模式。
行业真相:Prompt Engineering 这个概念曾经很火,但现在提的人越来越少了。两个原因:①门槛太低,本质就是“把话说清楚”;②模型越来越强,你说得模糊它也能猜出你的意思。但这不意味着 Prompt 不重要——好的 Prompt 依然能大幅提升输出质量。
Prompt 的进化版:Harness
说到 Prompt,就不得不提一个最新的概念——Harness(指令束)。
你可能注意到了,Prompt 工程的热度在下降。不是因为 Prompt 不重要了,而是因为 AI 的能力已经进化到了需要一种全新的指令方式。
Harness 是什么? 如果说 Prompt 是“给 AI 写一封邮件”,那 Harness 就是“给 AI 配了一整套工作手册”。 Prompt 关注的是“这一次怎么回答”,Harness 关注的是“AI 应该怎么工作”——包括身份定义、行为边界、工具使用规则、输出格式、质量标准……所有东西打包在一起,形成一个完整的约束框架。
为什么 Harness 是 Prompt 的进化?
| 维度 | Prompt | Harness |
|---|---|---|
| 关注点 | 单次对话的输出质量 | AI 的长期工作模式 |
| 内容 | 一段话/几条规则 | 完整的指令体系(身份+规则+工具+格式) |
| 适用场景 | 简单问答、内容生成 | 复杂任务、Agent 系统、工作流 |
| 类比 | 给下属口头交代一件事 | 给下属一本 SOP 手册 |
现实中的例子:你现在用的各种 AI Agent,比如 Claude Code、Cursor、OpenClaw,它们背后都不是靠一个 Prompt 在驱动,而是靠一套完整的 Harness 系统。
Claude Code 的 Harness 定义了:它是一个编程助手、怎么读代码、怎么执行命令、什么时候该问你、输出格式是什么。这些规则不是你每次手动输入的,是开发者在后台配好的,AI 每次启动自动加载。
你可以把 Harness 理解成 Prompt 的“Pro Max 版”。Prompt 是单兵作战的指令,Harness 是整个团队的作战体系。随着 AI 从“聊天工具”进化成“工作伙伴”,从 Prompt 到 Harness 的进化,是必然的趋势。
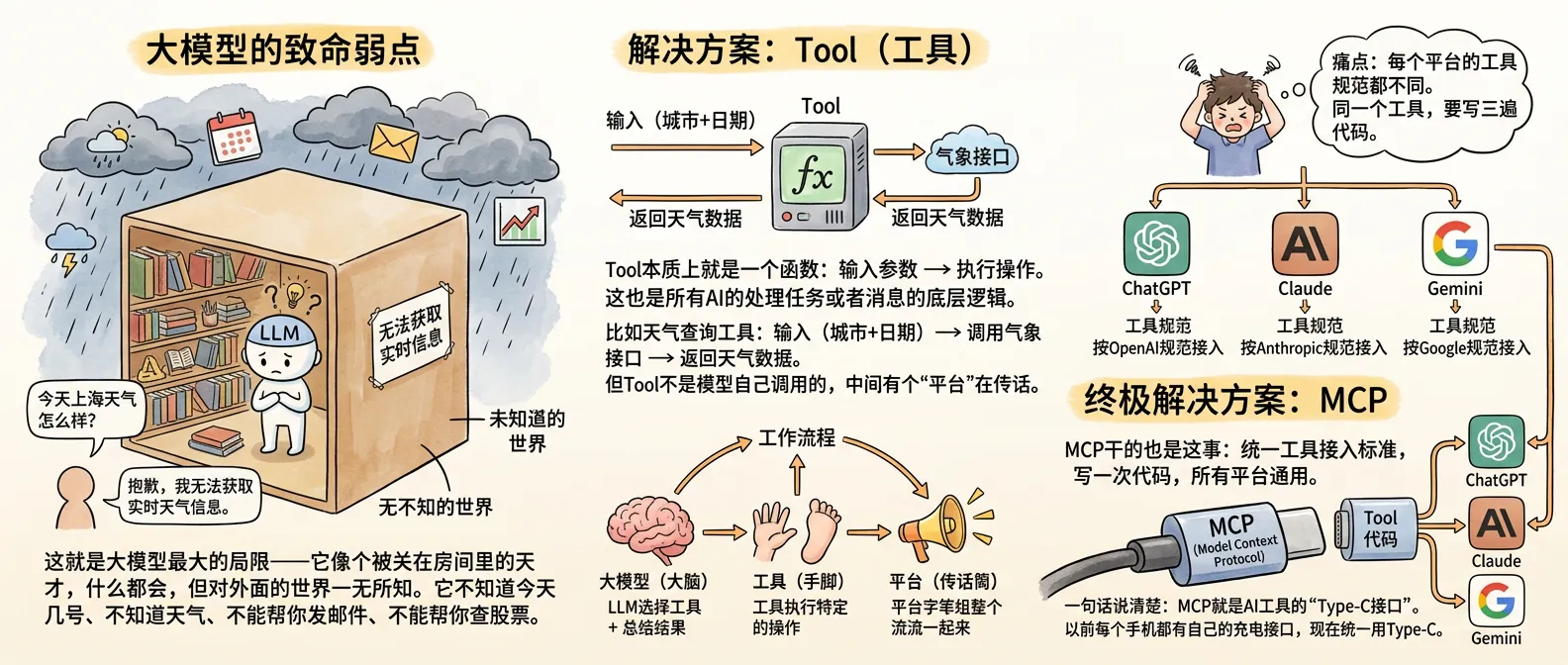
五、感知世界的钥匙:Tool 与 MCP
大模型的致命弱点
你有没有问过 ChatGPT“今天上海天气怎么样?”,然后它回答:
“抱歉,我无法获取实时天气信息。”
这就是大模型最大的局限——它像个被关在房间里的天才,什么都会,但对外面的世界一无所知。它不知道今天几号、不知道天气、不能帮你发邮件、不能帮你查股票。
解决方案:Tool(工具)
Tool 本质上就是一个函数:输入参数 → 执行操作 → 返回结果。这也是所有 AI 处理任务或者消息的底层逻辑。
比如天气查询工具:输入(城市+日期)→ 调用气象接口 → 返回天气数据。
但 Tool 不是模型自己调用的,中间有个“平台”在传话。完整的工作流程是这样的:
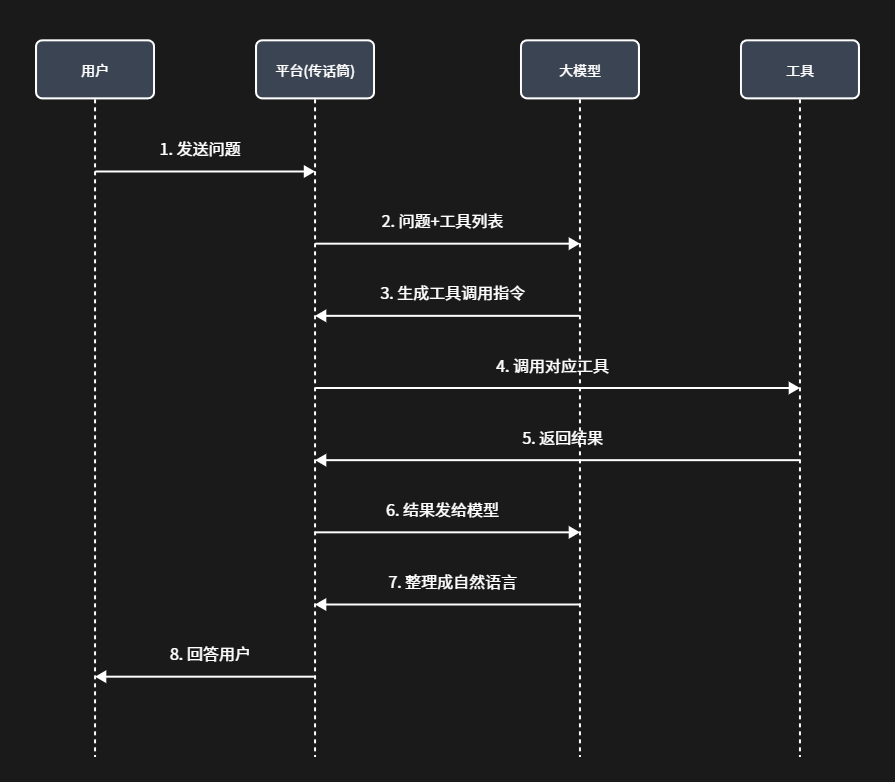
角色分工很清晰:
- 大模型:负责选择工具 + 汇总结果(大脑)
- 工具:负责执行具体操作(手脚)
- 平台:负责串联整个流程(传话筒)
痛点:每个平台的工具规范都不同
这就是最烦的地方:
| 平台 | 工具规范 |
|---|---|
| ChatGPT | 按 OpenAI 规范接入 |
| Claude | 按 Anthropic 规范接入 |
| Gemini | 按 Google 规范接入 |
同一个工具,要写三遍代码。
终极解决方案:MCP
MCP(Model Context Protocol),全称“模型上下文协议”。
一句话说清楚:MCP 就是 AI 工具的“Type-C 接口”。以前每个手机都有自己的充电接口,现在统一用 Type-C。MCP 干的也是这事——统一工具接入标准,写一次代码,所有平台通用。
六、自主智能体:Agent 与 Agent Skill
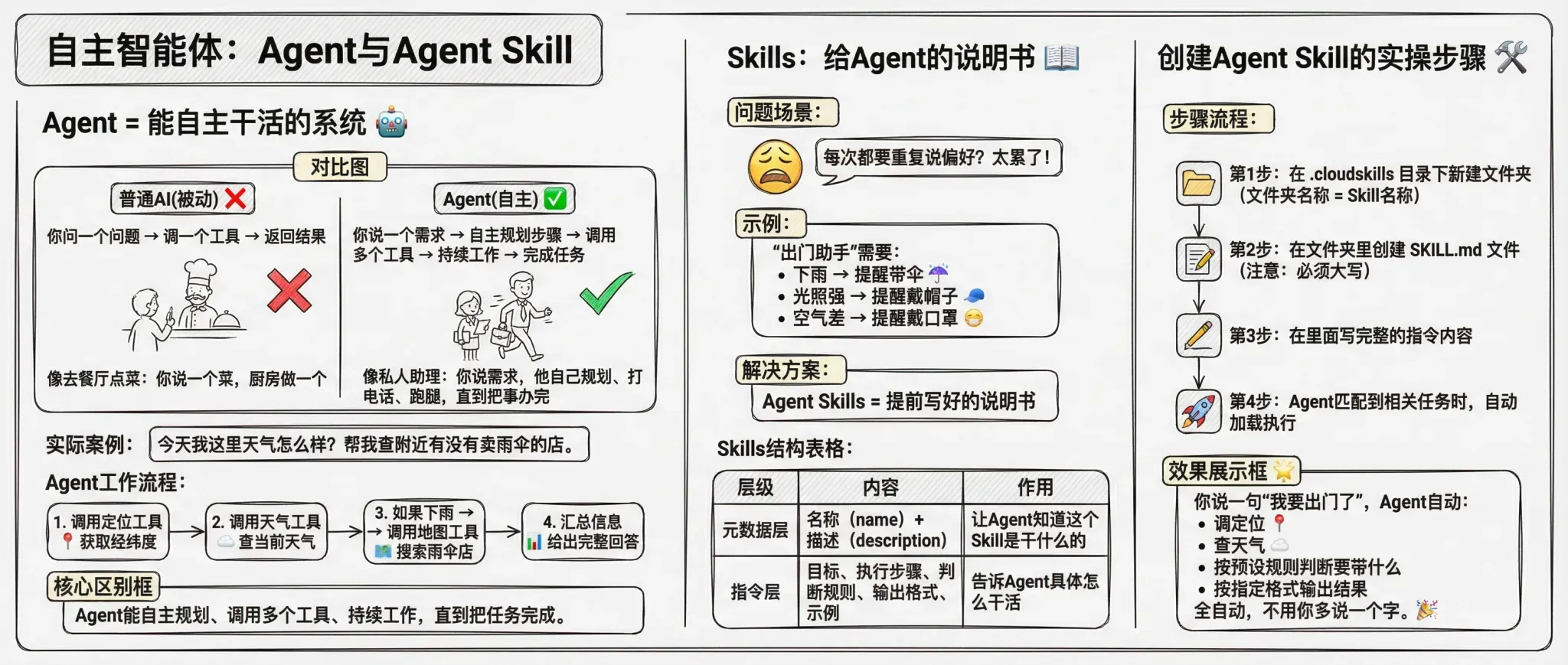
Agent = 能自主干活的系统
前面说的 Tool,是被动调用的——你问一个问题,它调一个工具。但现实生活中,很多任务是复杂的,需要多步操作。
比如你说:“今天我这里天气怎么样?帮我查附近有没有卖雨伞的店。”
这就需要一个 Agent(智能体)来协调:
- 先调用定位工具,获取你的经纬度
- 调用天气工具,查当前天气
- 如果下雨,调用地图工具,搜索附近的雨伞店
- 把所有信息汇总,给你一个完整的回答
Agent 和普通 AI 对话的核心区别:Agent 能自主规划、调用多个工具、持续工作,直到把任务完成。
说个类比你就懂了:普通 AI 对话像去餐厅点菜——你说一个菜,厨房做一个。Agent 像请了个私人助理——你说了个需求,他自己规划步骤、打电话、跑腿,直到把事办完。
Skills:给 Agent 的说明书
但 Agent 有个问题:每次你都要重复说一遍你的偏好。
比如你有个“出门助手”,你希望它:下雨提醒带伞、光照强提醒戴帽子、空气差提醒戴口罩……每次都得说一遍?太累了。
Agent Skills 就是解决方案——提前写好一份说明书,Agent 每次干活前自动读取。本质上就是一个 Markdown 格式的文档,包含:
| 层级 | 内容 | 作用 |
|---|---|---|
| 元数据层 | 名称(name) + 描述(description) | 让 Agent 知道这个 Skill 是干什么的 |
| 指令层 | 目标、执行步骤、判断规则、输出格式、示例 | 告诉 Agent 具体怎么干活 |
创建一个 Agent Skill 的实操步骤
- 在
.cloudskills目录下新建一个文件夹(文件夹名称就是 Skill 名称) - 在文件夹里创建 SKILL.md 文件(注意:必须大写)
- 在里面写完整的指令内容
- Agent 在匹配到相关任务时,自动加载执行
效果:你说一句“我要出门了”,Agent 自动调定位、查天气、按预设规则判断要带什么、按你指定的格式输出结果。全自动,不用你多说一个字。
七、完整知识体系:一张图串起来
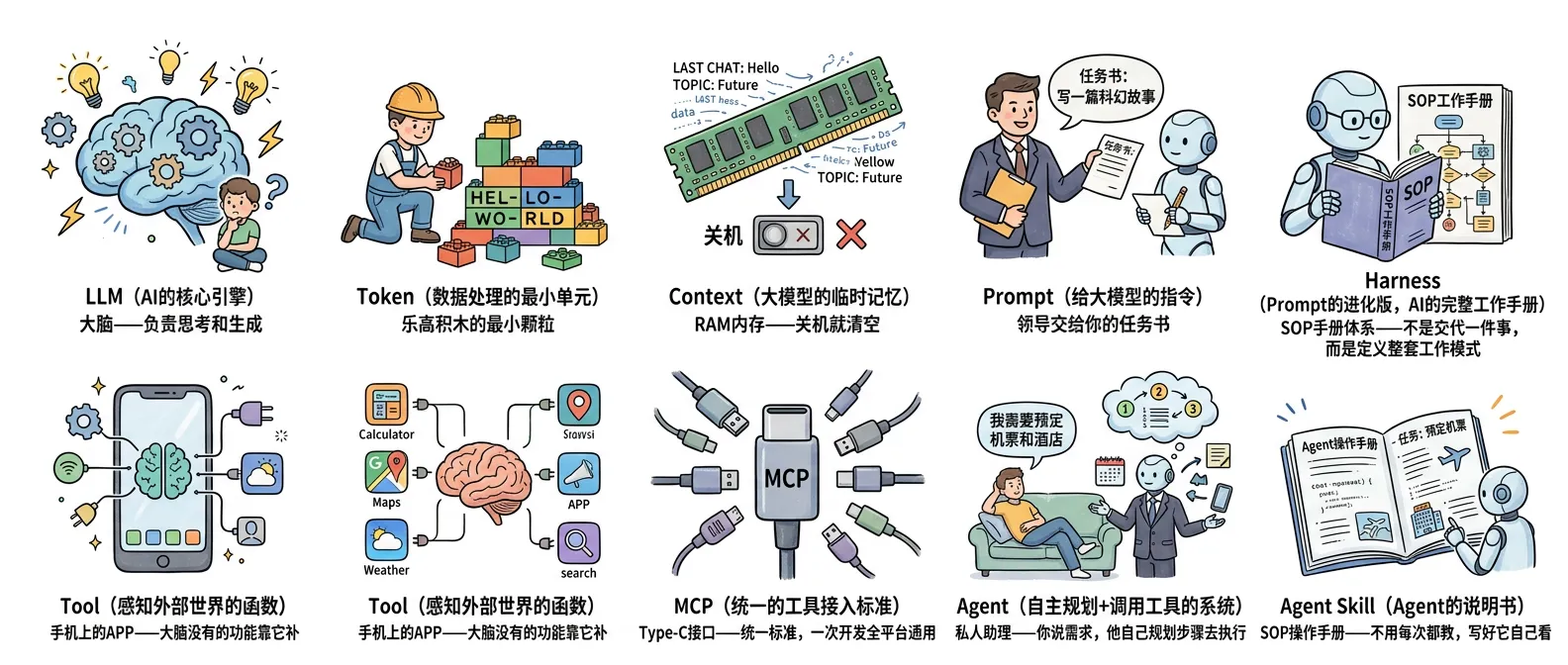
前面讲了 9 个概念,它们之间的关系用一张表总结:
| 概念 | 一句话定义 | 生活类比 |
|---|---|---|
| LLM | AI 的核心引擎 | 大脑——负责思考和生成 |
| Token | 数据处理的最小单元 | 乐高积木的最小颗粒 |
| Context | 大模型的临时记忆 | RAM 内存——关机就清空 |
| Prompt | 给大模型的指令 | 领导交给你的任务书 |
| Harness | Prompt 的进化版,AI 的完整工作手册 | SOP 手册体系——不是交代一件事,而是定义整套工作模式 |
| Tool | 感知外部世界的函数 | 手机上的 APP——大脑没有的功能靠它补 |
| MCP | 统一的工具接入标准 | Type-C 接口——统一标准,一次开发全平台通用 |
| Agent | 自主规划+调用工具的系统 | 私人助理——你说需求,他自己规划步骤去执行 |
| Agent Skill | Agent 的说明书 | SOP 操作手册——不用每次都教,写好它自己看 |
八、理解底层,才能驾驭未来
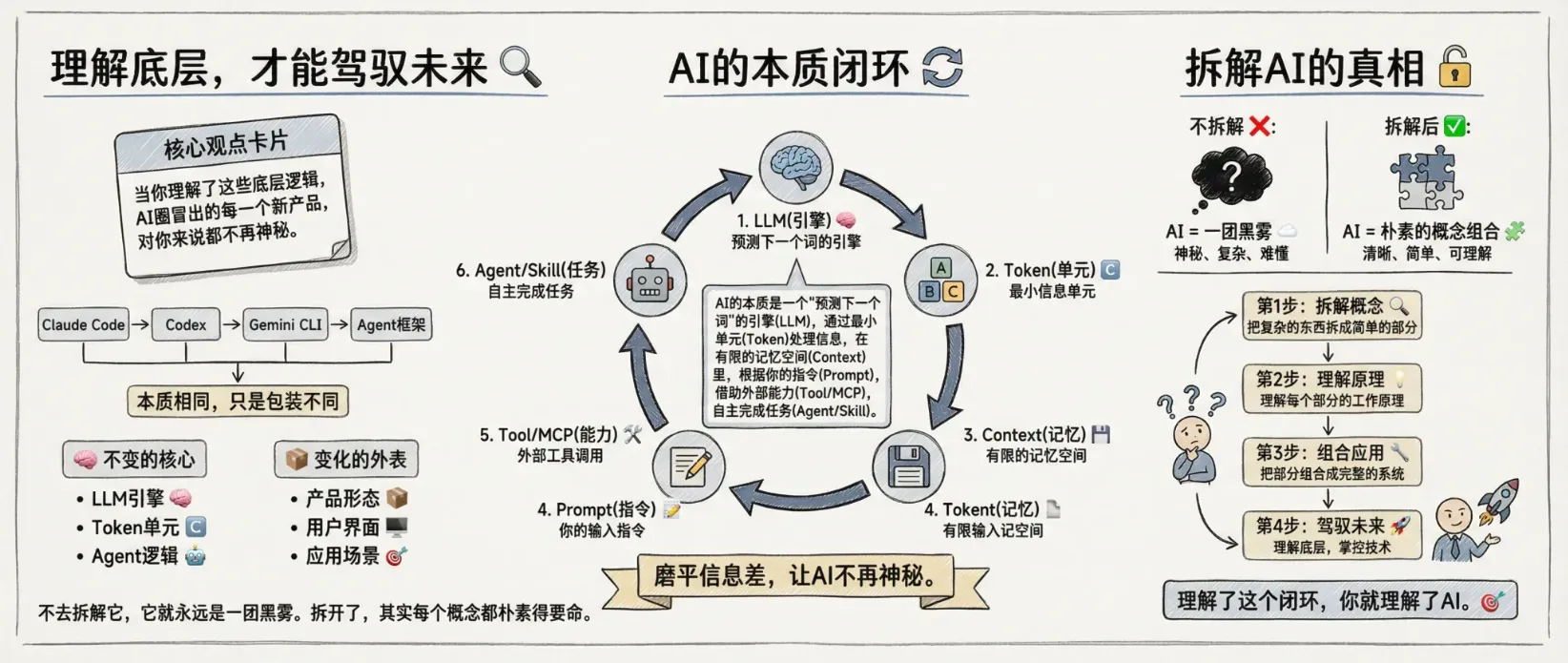
你可能觉得这些概念很“技术”,跟你没什么关系。但实际上,当你理解了这些底层逻辑,AI 圈冒出的每一个新产品,对你来说都不再神秘。
Claude Code、Codex、Gemini CLI、各种 Agent 框架……它们本质上都是在这个架构上玩花样。
无论技术怎么迭代,核心原理不会变。
LLM 还是那个引擎,Token 还是那个最小单元,Agent 还是那套规划+工具调用的逻辑。变了的是包装和产品形态,没变的是底层骨架。
一句话总结这篇文章:
AI 的本质是一个“预测下一个词”的引擎(LLM),通过最小单元(Token)处理信息,在有限的记忆空间(Context)里,根据你的指令(Prompt/Harness),借助外部能力(Tool/MCP),自主完成任务(Agent/Skill)。
理解了这个闭环,你就理解了 AI。
AI 这东西,你不去拆解它,它就永远是一团黑雾。你拆开了,其实每个概念都朴素得要命。磨平一些信息差,这事儿本身,就挺有意思的。

评论互动