ChatGPT Images 2.0 图像生成模型提示词指南

- 模型核心能力包括高保真照片级真实感、可靠文字渲染和精准风格控制
- 提示词按背景/场景→主体→关键细节→约束顺序编写并明确预期用途
- gpt-image-2为默认模型,低质量设置适合大批量生成,旧模型仅用于迁移
- 具体描述材质、光照、视角,使用photorealistic激活照片级真实感模式
- 从干净基础提示词开始迭代,小幅度单一更改,避免长提示词堆砌
本文翻译自 OpenAI 官方 Cookbook:GPT Image Generation Models Prompting Guide
1. 简介
OpenAI 的 gpt-image 系列图像生成模型专为生产级视觉内容和高度可控的创意工作流而设计。它们既适用于专业设计任务,也适用于迭代式内容创作,并可根据工作流需求在高画质渲染和低延迟用例之间灵活切换。
核心能力包括:
- 高保真照片级真实感——自然光照、精准材质和丰富的色彩渲染
- 灵活的质量-延迟权衡——在较低设置下仍能以更快速度生成图像,且视觉质量仍超越前代图像模型
- 稳健的面部和身份保持——适用于编辑、角色一致性和多步骤工作流
- 可靠的文字渲染——清晰的字形、一致的排版和良好的对比度
- 复杂结构化视觉内容——包括信息图、图表和多面板合成
- 精准的风格控制与风格迁移——仅需极少提示词,即可覆盖品牌设计系统到美术风格等多种场景
- 强大的真实世界知识与推理能力——能够准确描绘物体、环境和场景
本指南重点介绍 gpt-image-2 的提示词模式、最佳实践和源自真实生产用例的示例提示词。gpt-image-2 是我们最强大的图像模型,具有更强的图像质量、改进的编辑性能以及对生产级工作流的更广泛支持。low 质量设置特别适合对延迟敏感的用例,而 medium 和 high 则在需要最大保真度时仍然是理想选择。
OpenAI 图像模型参数
本节是本指南所涵盖图像模型的参考信息,重点介绍:
- 模型名称
- 支持的
outputQuality值 - 支持的
input_fidelity值 - 支持的
size/ 分辨率行为 - 按工作流推荐的用例
模型概览
截至 2026 年 4 月 21 日,OpenAI 提供以下图像模型。
| 模型 | outputQuality | input_fidelity | 分辨率 | 推荐用途 |
|---|---|---|---|---|
gpt-image-2 | low、medium、high | 已禁用。input_fidelity 对此模型无效,因为输出默认已是高保真 | 满足以下约束的任意分辨率 | 推荐作为新项目的默认选择。适用于最高质量的生成和编辑、含大量文字的图像、照片级真实感、合成、对身份敏感的编辑,以及减少重试次数比最低成本更重要的工作流。 |
gpt-image-1.5 | low、medium、high | low、high | 1024x1024、1024x1536、1536x1024、auto | 仅在迁移期间保留用于已有的经过验证的工作流。对于新项目,优先使用 gpt-image-2,尤其在质量、编辑可靠性或灵活尺寸方面有要求时。 |
gpt-image-1 | low、medium、high | low、high | 1024x1024、1024x1536、1536x1024、auto | 仅用于旧版兼容。如果你正在启动新工作流或更新提示词,请迁移至 gpt-image-2;仅在验证升级期间需要短期稳定性时保留 gpt-image-1。 |
gpt-image-1-mini | low、medium、high | low、high | 1024x1024、1024x1536、1536x1024、auto | 适用于成本和吞吐量为主要约束的场景:大批量变体生成、快速构思、预览、轻量级个性化,以及不需要最强生成或编辑性能的草稿素材。 |
gpt-image-2 尺寸选项
gpt-image-2 支持在 size 参数中传入任意分辨率,前提是满足以下所有约束:
- 最大边长必须小于
3840px - 两条边长都必须是
16的倍数 - 长边与短边之比不得超过
3:1 - 总像素数不得超过
8,294,400 - 总像素数不得少于
655,360
如果输出图像超过 2560x1440 像素(共 3,686,400 像素),即通常所说的 2K,请将其视为实验性功能,因为在此尺寸以上结果可能更不稳定。
以下是一些符合上述约束的常用参考分辨率:
| 标签 | 分辨率 | 备注 |
|---|---|---|
| 竖版高清 | 1024x1536 | 标准竖版选项 |
| 横版高清 | 1536x1024 | 标准横版选项 |
| 正方形 | 1024x1024 | 通用默认选项 |
| 2K / QHD | 2560x1440 | 流行宽屏格式,推荐作为 gpt-image-2 的可靠性上限 |
| 4K / UHD | 3840x2160 | 实验性高端目标。如果最大边长规则严格按 < 3840 执行,请向下取整到最近的有效尺寸,如 3824x2144 |
何时选择哪个模型
- 将
gpt-image-2作为大多数生产级工作流的默认选择。它是综合实力最强的模型,也是目前使用gpt-image-1.5或gpt-image-1进行高质量输出的团队的最佳升级目标。 - 当速度和单位经济成本是首要考量时,选择
gpt-image-2并设置 quality: low。此设置在许多用例中都有不错的质量,非常适合大批量生成和实验。你也可以尝试gpt-image-1-mini处理这些用例,但我们观察到 quality: low 的效果同样出色。 - 仅在验证提示词迁移、回归测试输出或维护尚未准备好迁移的旧工作流期间,保留
gpt-image-1.5或gpt-image-1用于向后兼容。
对于当前使用 gpt-image-1.5 或 gpt-image-1 的工作流,建议如下:
- 升级到
gpt-image-2用于面向客户的素材、照片级真实感生成、重度编辑流程、品牌敏感的创意工作、图像内文字工作,以及更好的首次通过质量可以减少人工审查或重试的任何工作流。 - 仅当主要目标是为大批量探索性或低风险图像降低成本时,才考虑使用
gpt-image-1-mini替代旧版模型。 - 迁移期间,先保持提示词基本不变,然后在真实工作负载上比较输出质量、延迟和重试率之后,再进行调整。
2. 提示词基础
以下提示词基础适用于 GPT 图像生成模型。它们基于 Alpha 测试中反复出现的模式,覆盖生成、编辑、信息图、广告、人物图像、UI 界面原型和合成工作流。
- 结构 + 目标: 按一致的顺序编写提示词(背景/场景 → 主体 → 关键细节 → 约束),并包含预期用途(广告、UI 原型、信息图)以设定“模式”和精细度。对于复杂请求,使用简短的标记段落或换行,而非一整段长文本。
- 提示词格式: 使用最容易维护的格式。极简提示词、描述性段落、类 JSON 结构、指令式提示词和标签式提示词都能很好地工作,只要意图和约束清晰即可。对于生产系统,优先使用易于浏览的模板而非花哨的提示词语法。
- 具体性 + 质量提示: 对材质、形状、纹理和视觉媒介(照片、水彩画、3D 渲染)要具体,仅在需要时添加针对性的“质量杠杆”(如 胶片颗粒、纹理笔触、微距细节)。对于照片级真实感,直接在提示词中包含 “photorealistic” 一词可强烈激活模型的照片级真实感模式。类似的表达如 “real photograph”、“taken on a real camera”、“professional photography” 或 “iPhone photo” 也有帮助,但详细的相机参数可能被宽泛解读,因此主要将它们用于整体外观和构图,而非精确的物理模拟。
- 延迟与保真度: 对于延迟敏感或大批量的用例,从
quality="low"开始并评估是否满足视觉需求。在许多情况下,它在显著加快生成速度的同时提供足够的保真度。对于小号或密集文本、详细信息图、近距离肖像、对身份敏感的编辑和高分辨率输出,在发布前比较medium或high的效果。 - 构图: 指定取景和视角(特写、广角、俯视)、透视/角度(平视、低角度)和光照/氛围(柔和漫射、黄金时刻、高对比度)来控制画面。如果布局重要,明确指出位置(如“Logo 在右上角”、“主体居中,左侧留白”)。对于广角、电影感、低光照、雨天或霓虹灯场景,添加关于尺度、氛围和色彩的额外细节,以免模型为了表面真实感而牺牲氛围。
- 人物、姿势和动作: 对于场景中的人物,描述比例、身体取景、视线和物体交互。例如:“全身可见,包括脚部”、“相对于桌子是儿童比例”、“低头看打开的书,而不是看向镜头”或“双手自然握住把手”。这些细节有助于改善身体比例、动作几何和视线对齐。
- 约束(改变什么 vs 保持什么): 明确说明排除项和不变量(如“无水印”、“无多余文字”、“无 Logo/商标”、“保持身份/几何/布局/品牌元素”)。对于编辑,使用“仅更改 X”+“保持其他一切不变”,并在每次迭代中重复保持列表以减少漂移。如果编辑应是精确手术式的,还要说明不要更改饱和度、对比度、布局、箭头、标签、摄像机角度或周围物体。
- 图像中的文字: 将字面文本放在引号或全大写中,并将排版细节(字体样式、大小、颜色、位置)作为约束说明。对于复杂词汇(品牌名、不常见拼写),逐字母拼出以提高字符准确性。对于小号文本、密集信息面板和多字体布局,使用
medium或high质量。 - 多图像输入: 通过索引和描述引用每个输入(“图像 1:产品照片… 图像 2:风格参考…”),并描述它们如何交互(“将图像 2 的风格应用到图像 1”)。合成时,明确说明哪些元素移到哪里(“把图像 1 中的鸟放到图像 2 的大象上”)。
- 迭代而非堆砌: 长提示词可能效果很好,但从干净的基础提示词开始,用小幅度、单一更改的后续迭代进行调试会更容易(如“让光照更暖”、“移除多余的树”、“恢复原始背景”)。使用“与之前相同的风格”或“主体”等引用来利用上下文,但如果关键细节开始漂移,则重新指定。
3. 环境配置
运行一次即可。它会:
- 创建 API 客户端
- 在 images 文件夹中创建
output_images/目录 - 添加一个保存 base64 图像的小工具函数
将用于编辑的参考图像放入 input_images/(或更新示例中的路径)。
import os
import base64
from openai import OpenAI
client = OpenAI()
os.makedirs("../../images/input_images", exist_ok=True)
os.makedirs("../../images/output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""
将返回的第一张图像保存到 output_images 文件夹中的指定文件名。
"""
image_base64 = result.data[0].b64_json
out_path = os.path.join("../../images/output_images", filename)
with open(out_path, "wb") as f:
f.write(base64.b64decode(image_base64))
from IPython.display import HTML, Image, display
def display_image_grid(items, width=240):
cards = []
for item in items:
title = item.get("title", "")
label = f'<div style="font-weight:600;margin-bottom:8px">{title}</div>' if title else ""
cards.append(
'<div style="text-align:center">'
+ label
+ f'<img src="{item["path"]}" width="{width}" style="max-width:100%;height:auto;" />'
+ '</div>'
)
display(HTML('<div style="display:flex;flex-wrap:wrap;gap:16px;align-items:flex-start">' + ''.join(cards) + '</div>'))以下示例使用我们最强大的图像模型 gpt-image-2
4. 用例 — 生成(文本 → 图像)
4.1 信息图
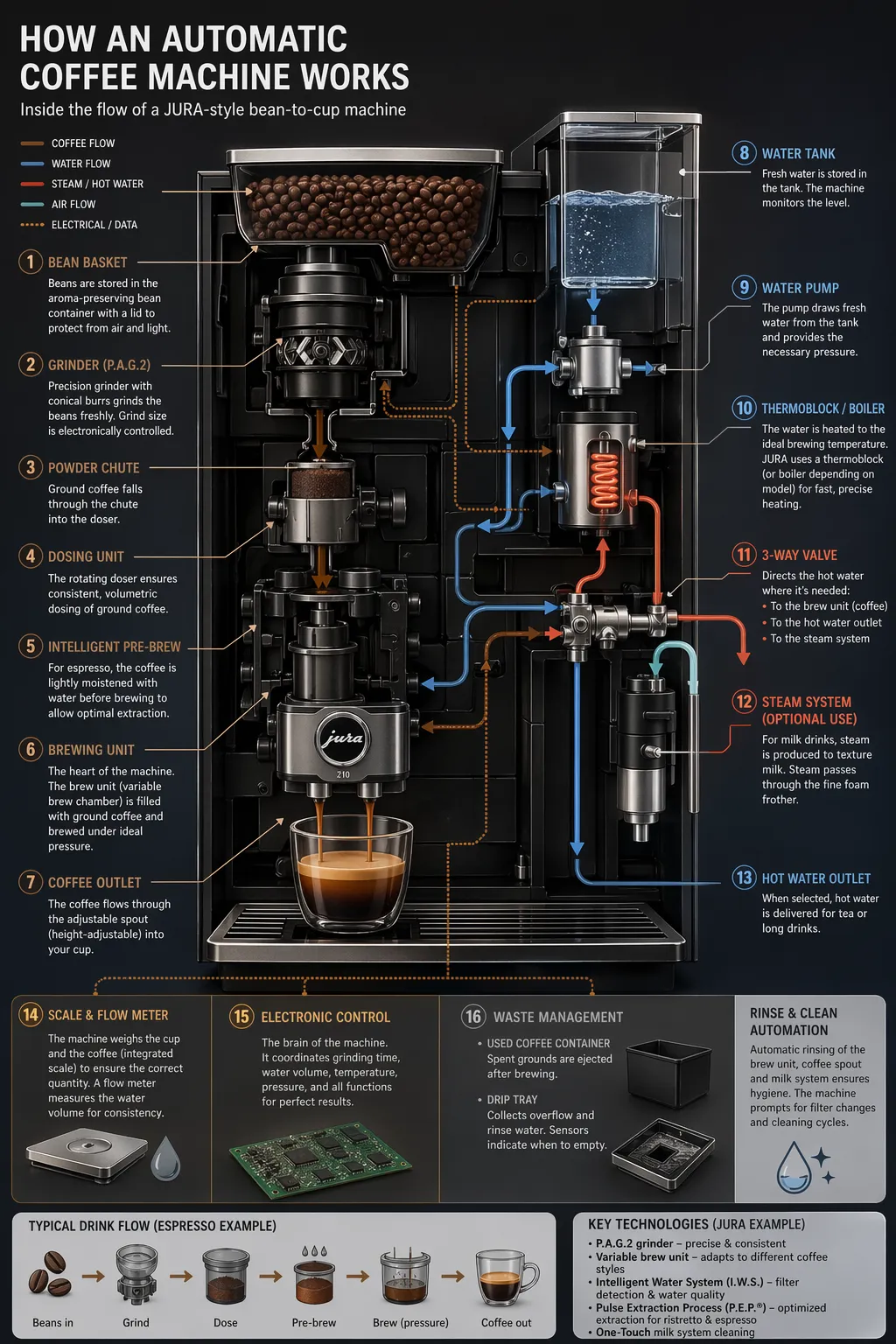
使用信息图为特定受众(学生、高管、客户或公众)解释结构化信息。示例包括解说图、海报、标注图表、时间线和“可视化百科”素材。对于密集布局或图像内含大量文字的情况,建议将输出生成质量设为 “high”。
prompt = """
创建一张详细的信息图,展示类似 Jura 的自动咖啡机的运作原理和流程。
从咖啡豆仓,到研磨,到秤重,水箱,锅炉等。
我希望从技术和视觉上理解整个流程。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "infographic_coffee_machine_gpt-image-2.png")输出图像:
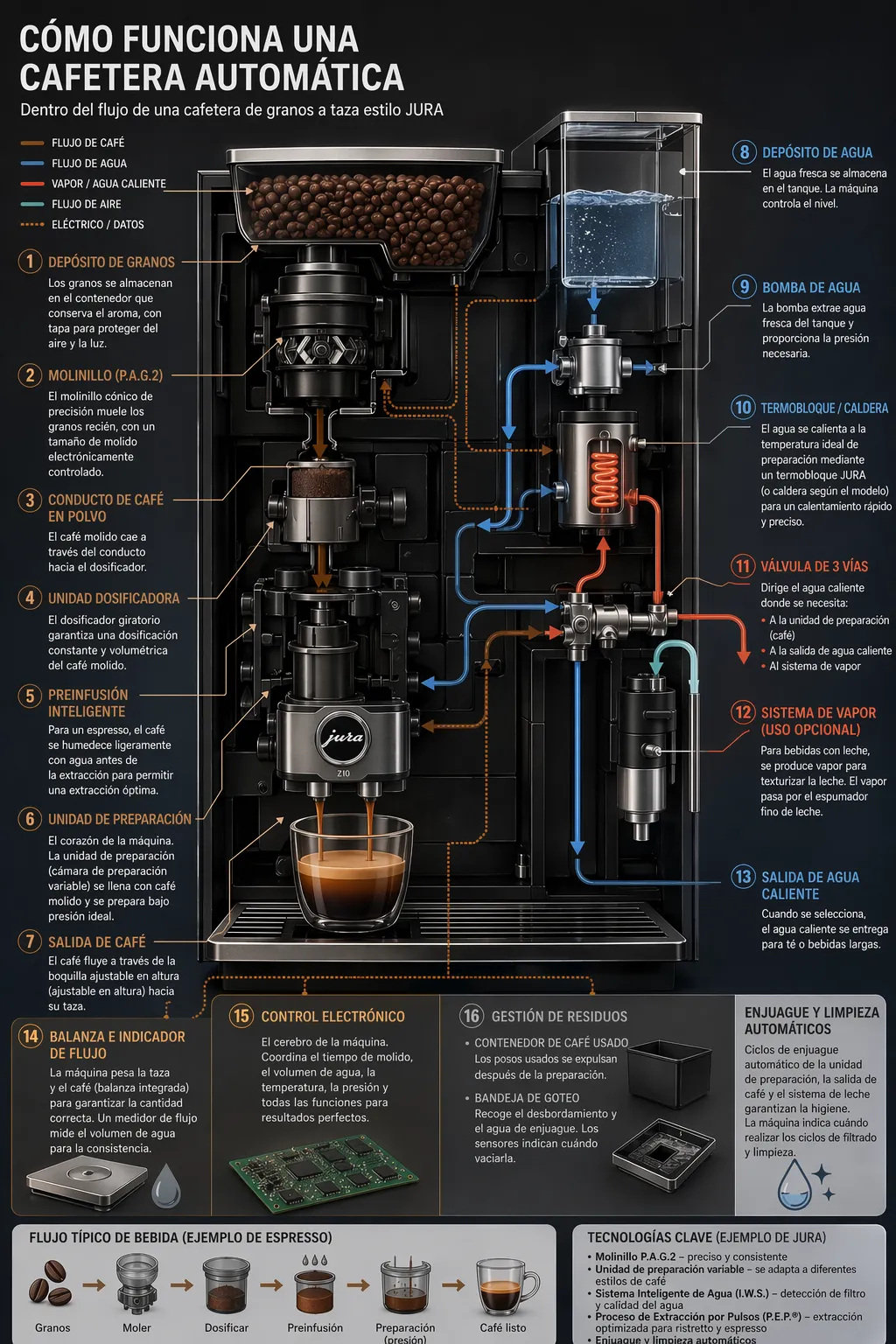
4.2 图像中的文字翻译
用于将现有设计(广告、UI 截图、包装、信息图)本地化为另一种语言,而无需从头重建布局。关键是在翻译时保持除文字之外的一切不变——保持排版样式、位置、间距和层次一致——同时逐字准确翻译,不添加多余词汇,不做不必要的重排,不意外修改 Logo、图标或图像。
prompt = """
将信息图中的文字翻译为西班牙语。不要更改图像的任何其他方面。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/output_images/infographic_coffee_machine_gpt-image-2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "infographic_coffee_machine_sp_gpt-image-2.png")输出图像:
4.3 自然的“真实感”照片
要获得可信的照片级真实感,请像拍摄真实照片一样编写提示词。使用摄影术语(镜头、光照、取景),明确要求真实纹理(毛孔、皱纹、织物磨损、瑕疵)。避免暗示影棚修饰或摆拍的措辞。当细节很重要时,设置 quality=“high”。
prompt = """
创建一张照片级真实感的抓拍照片,一位老水手站在小渔船上。
他有饱经风霜的皮肤,可见的皱纹、毛孔和日晒质感,手臂上有几处褪色的传统水手纹身。
他正在平静地整理渔网,旁边他的狗趴在甲板上。使用 35mm 胶片照片风格拍摄,中等特写,平视角度,使用 50mm 镜头。
柔和的海岸日光,浅景深,微妙的胶片颗粒,自然的色彩平衡。
图像应该感觉真实且非摆拍,具有真实的皮肤纹理、磨损的材质和日常细节。不要美化,不要重度修图。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "photorealism-gpt-image-2.png")输出图像:

4.4 世界知识
GPT 图像生成模型能够将强大的推理能力与世界知识相结合。例如,当被要求生成 1969 年 8 月纽约贝塞尔(Bethel)的一个场景时,它们可以推断出伍德斯托克音乐节(Woodstock),并在未被明确告知该事件的情况下生成准确、符合上下文的图像。
prompt = """
创建一个真实的户外人群场景,设定为 1969 年 8 月 16 日纽约贝塞尔。
照片级真实感,符合时代特征的服装、布景和环境。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "world_knowledge-gpt-image-2.png")输出图像:

4.5 Logo 生成
高质量的 Logo 生成源于清晰的品牌约束和简洁性。描述品牌的个性和使用场景,然后要求一个干净、原创的标志,具有良好的形状、平衡的负空间和跨尺寸的可扩展性。
可以通过参数 “n” 指定要生成的变体数量。
prompt = """
为一家名为 Field & Flour 的本地烘焙店创建一个原创的、不侵权的 Logo。
Logo 应给人温暖、简洁和永恒的感觉。使用干净的矢量式形状、强烈的轮廓和平衡的负空间。
优先考虑简洁而非细节,使其在大小尺寸下都清晰可读。扁平设计,最少的笔触,除非必要不使用渐变。
纯色背景。输出单个居中的 Logo,保留充足的内边距。无水印。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
n=4 # 生成 4 个版本的 Logo
)
# 将 4 张图像分别保存到不同文件
for i, item in enumerate(result.data, start=1):
image_base64 = item.b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"../../images/output_images/logo_generation_{i}_gpt-image-2.png", "wb") as f:
f.write(image_bytes)输出图像:
| 选项 1 | 选项 2 | 选项 3 | 选项 4 |
|---|---|---|---|
4.6 广告生成
广告生成的最佳效果来自于像撰写创意简报(creative brief)而非纯技术图像规格说明那样编写提示词。描述品牌、受众、文化背景、概念、构图和精确文案,然后让模型在这些边界内做出有品味的创意决策。这对于早期广告活动探索非常有用,因为模型能够解读受众线索、推断美术方向,并提出使广告看起来经过精心设计而非仅仅是渲染出来的视觉细节。
为了获得更好的效果,请在同一提示词中包含品牌定位、期望氛围、目标受众、场景和广告语。如果文字必须出现在图像中,请精确引用并要求干净、易读的排版。
prompt = """
为名为 Thread 的品牌创建一张潮酷文化广告/时尚大片。
这是一个新潮的年轻街头品牌。广告展示一群朋友一起出去玩,广告语为 "Yours to Create."
让它看起来像是为年轻街头服饰受众打造的精美广告画面:时尚、当代、充满活力、有品位。
使用干净的构图、强烈的色彩方向、自然的姿势和高级时尚摄影感。
广告语精确渲染一次,清晰易读,融入广告版面中。
不要额外的文字、水印或不相关的 Logo。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "thread_ad_gpt-image-2.png")输出图像:

4.7 故事转漫画条
对于故事转漫画生成,将叙事定义为一组清晰的视觉节拍序列,每个面板一个。保持描述具体且聚焦于动作,以便模型能将故事转化为可读的、节奏良好的面板。
prompt = """
创建一个垂直漫画风格的短篇,包含 4 个等大面板。
面板 1:主人从前门离开。宠物在身后的窗户中,小小的身体贴着玻璃,眼睛睁大,爪子高高按在窗上,房子突然安静下来。
面板 2:门咔哒关上。寂静被打破。宠物慢慢转向空荡的房子,姿态变化,眼中闪烁着可能性的光芒。
面板 3:房子变了样。宠物像主人一样四仰八叉地躺在沙发上,旁边有碎屑,阳光像聚光灯一样切过房间。
面板 4:门开了。宠物端坐在入口旁,警觉而从容,好像什么都没发生过。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "comic_reel-gpt-image-2.png")输出图像:

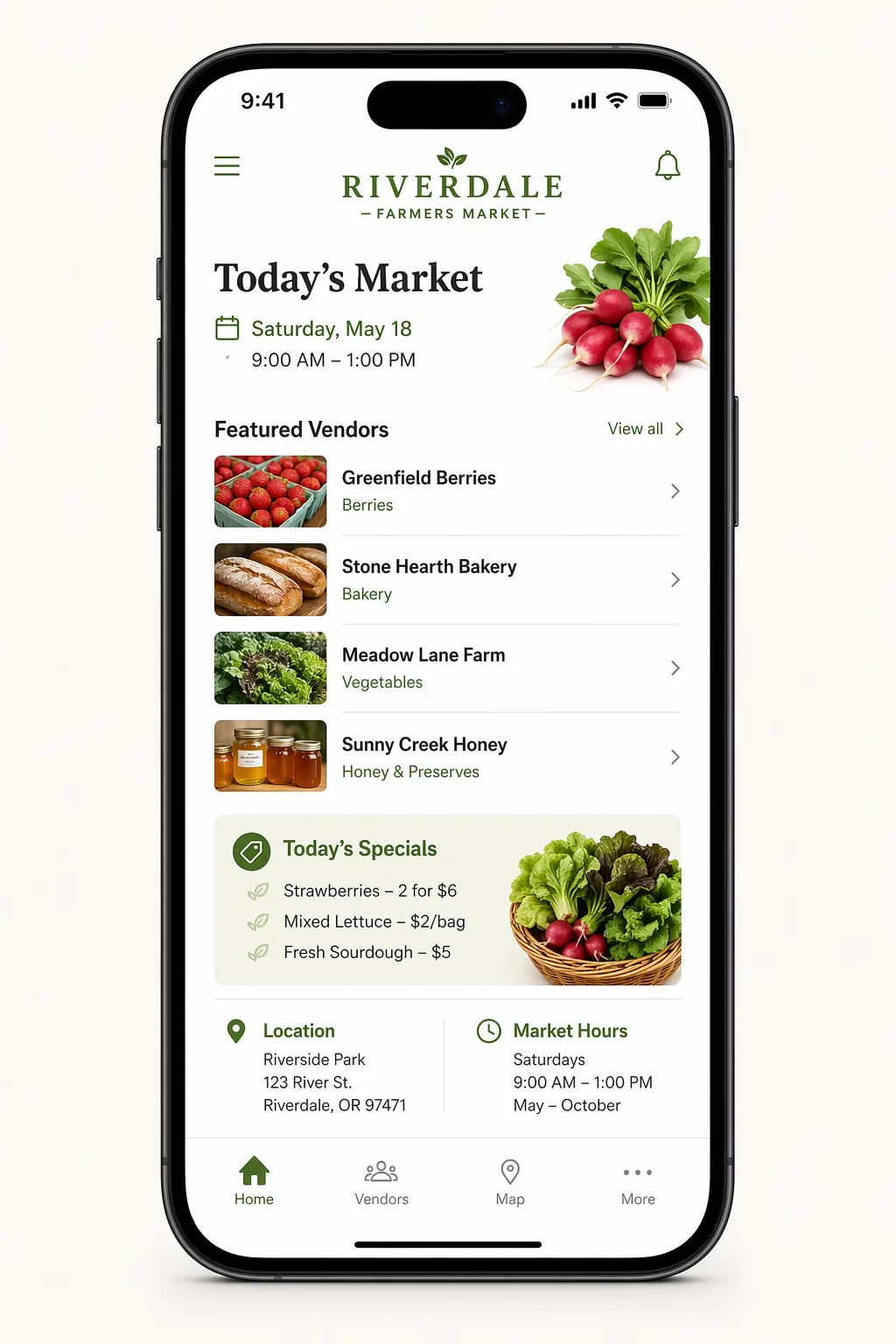
4.8 UI 界面原型
UI 界面原型的最佳效果来自于将产品描述得像已经存在一样。关注布局、层次、间距和真实的界面元素,避免使用概念图语言,这样结果看起来像是一个可用的、已交付的界面,而非设计草图。
prompt = """
为本地农贸市场创建一个逼真的移动应用 UI 界面原型。
展示今日市场,包含简单头部、带有小照片和分类的供应商简短列表、一个小型"今日特惠"区域,以及位置和营业时间的基本信息。
设计应实用且易于使用。白色背景,微妙的自然色彩点缀,清晰的排版,最少的装饰。
它应该看起来像是一个为小型本地市场设计的真实、美观的应用。
将 UI 界面原型放置在 iPhone 外框中。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "ui_farmers_market_gpt-image-2.png")输出图像:
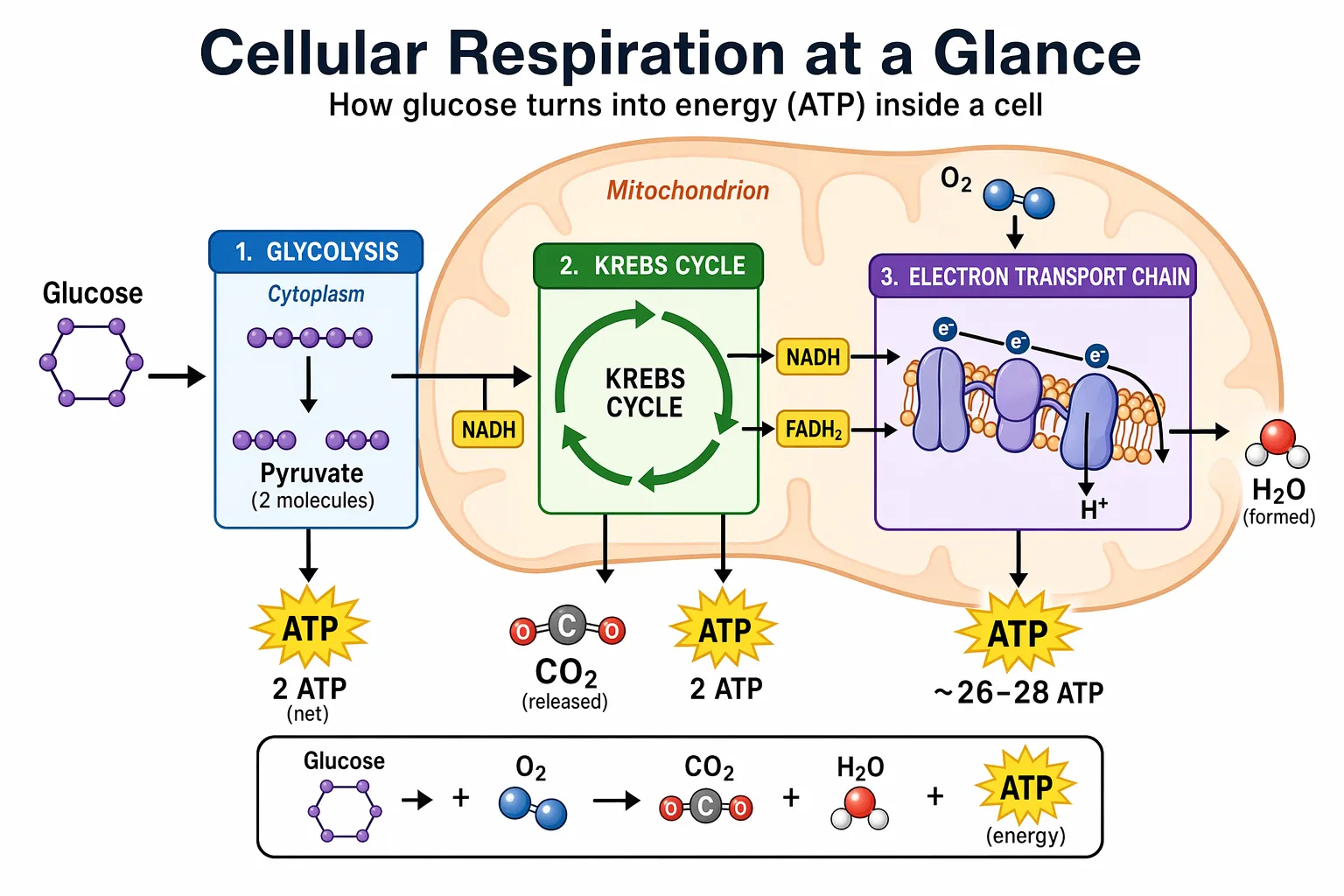
4.9 科学/教育类视觉图
科学和教育类视觉图非常适合生物学、化学、课堂解说、扁平科学图标系统、图表和学习素材。像撰写教学设计简报一样编写提示词:定义受众、教学目标、视觉格式、必要标签和科学约束。为获得最佳效果,要求一个干净的扁平视觉系统,具有一致的图标风格、清晰的箭头、易读的标签,以及足够的留白让学生能快速浏览概念。
当准确性很重要时,明确列出所需组件并说明不应包含什么。对于密集标签、图表或将用于幻灯片或课程材料的素材,使用 quality="high"。
prompt = """
为高中生创建一张简单的生物图表,标题为 "Cellular Respiration at a Glance"。
展示葡萄糖如何在细胞内转化为能量。包括糖酵解、克雷布斯循环和电子传递链。
用箭头连接各步骤,并标注主要分子:葡萄糖、丙酮酸、ATP、NADH、FADH2、CO2、O2 和 H2O。
让它看起来像一份干净的课堂讲义或幻灯片,白色背景,简单图标,清晰标签,易读的文字。
避免过小的文字、多余装饰或任何使图表难以理解的内容。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1536x1024",
quality="high",
)
save_image(result, "scientific_educational_cellular_respiration_gpt-image-2.png")输出图像:
4.10 幻灯片、图表、图表和生产力图像
生产力视觉图的最佳效果来自于像撰写交付物规格说明而非插画需求那样编写提示词。指明确切的交付物(幻灯片、工作流程图、图表、页面图像),定义画布和层次,提供真实的文字或数据,并描述视觉语言。这些提示词应包含实用性约束:易读的排版、精致的间距、无装饰性杂乱、无通用素材照片式处理。
对于幻灯片、图表和含大量图表的素材,在提示词中直接包含数字和标签。演示文稿风格的输出使用横版尺寸,当图像包含小号文字、图例、坐标轴或脚注时使用 quality="high"。
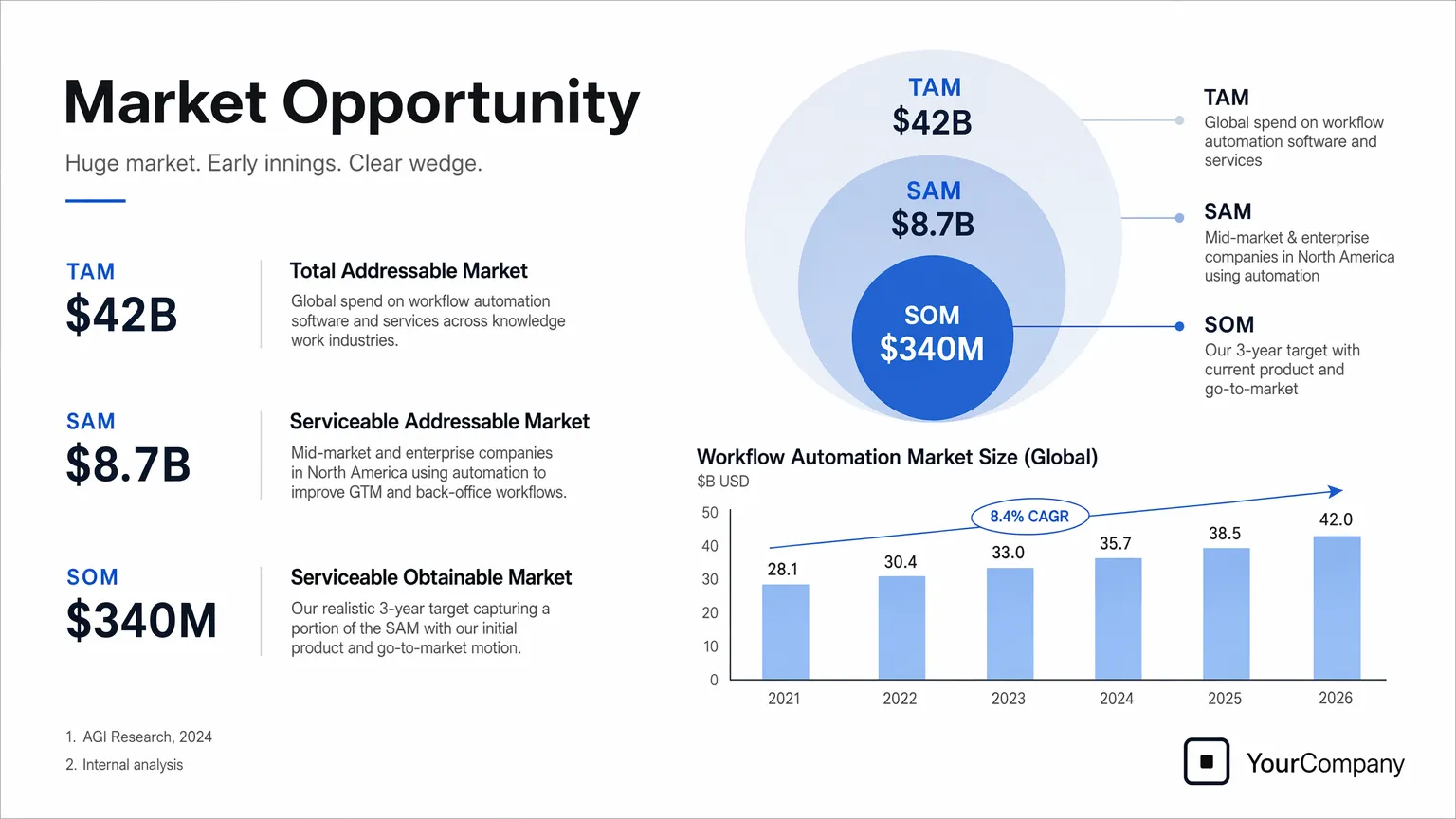
prompt = """
创建一张路演幻灯片,标题为 **"Market Opportunity"**,风格像 YC 支持的创业公司真实的 A 轮融资幻灯片。
使用干净的白色背景,类似 Inter 的现代无衬线字体,简洁极简的布局。幻灯片应包括:
* 一个 TAM/SAM/SOM 同心圆图表,使用柔和的蓝色和灰色
* 具体且可信的市场规模数据:
* **TAM:** $42B
* **SAM:** $8.7B
* **SOM:** $340M
* 下方一个干净的柱状图,展示 **2021 到 2026** 的市场增长,带有微妙的上升趋势
* 小脚注:**"AGI Research, 2024"** 和 **"Internal analysis"**
* 右下角的公司 Logo 占位符
设计应看起来属于一份真正融到资的路演幻灯片:高度易读的文字、清晰的数据层次、精致的间距和专业创业风格的视觉语言。
避免剪贴画、素材照片、渐变、阴影、装饰性元素或任何感觉通用或过度设计的内容。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1536x864",
quality="high",
)
save_image(result, "market_opportunity_slide_gpt-image-2.png")输出图像:
5. 用例 — 编辑(文本 + 图像 → 图像)
5.1 风格迁移
风格迁移(Style Transfer)在你希望保留参考图像的视觉语言(调色板、纹理、笔触、胶片颗粒等)的同时更改主体或场景时非常有用。为获得最佳效果,描述必须保持一致的部分(风格线索)和必须更改的部分(新内容),并添加硬性约束如背景、取景和“无多余元素”以防止漂移。
prompt = """
使用与输入图像相同的风格,生成一个骑着摩托车的男人,白色背景。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/pixels.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "motorcycle_gpt-image-2.png")输入图像:

输出图像:

5.2 虚拟服装试穿
虚拟试穿非常适合电商预览,此时身份保持至关重要。关键是明确锁定人物(面部、体型、姿势、发型、表情),仅允许更改服装,然后要求真实的贴合效果(悬垂、褶皱、遮挡)加上一致的光照/阴影,使服装看起来是自然穿着的——而非粘贴上去的。
prompt = """
编辑图像,使用提供的服装图片为该女士换装。不要以任何方式更改她的面部、面部特征、肤色、体型、姿势或身份。保持她完全相同的样貌、表情、发型和比例。仅替换服装,使服装自然贴合她现有的姿势和身体几何,展现真实的织物行为。匹配原图的光照、阴影和色温,使服装以照片级真实感融入,而不是看起来像粘贴上去的。不要更改背景、摄像机角度、取景或图像质量,不要添加配饰、文字、Logo 或水印。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/woman_in_museum.png", "rb"),
open("../../images/input_images/tank_top.png", "rb"),
open("../../images/input_images/jacket.png", "rb"),
open("../../images/input_images/tank_top.png", "rb"),
open("../../images/input_images/boots.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "outfit_gpt-image-2.png")输入图像:
| 全身 | 单品 1 |
|---|---|
 |  |
| 单品 2 | 单品 3 |
 |  |
输出图像:

5.3 手绘转图像(渲染)
手绘转渲染工作流非常适合将粗略草图转化为照片级真实感概念图,同时保持原始意图。将提示词当作规格说明书来编写:保持布局和透视,然后通过指定合理的材质、光照和环境来添加真实感。包含“不要添加新元素/文字”以避免创意性重新诠释。
prompt = """
将这幅绘画转换为照片级真实感图像。
保持精确的布局、比例和透视。
选择与草图意图一致的真实材质和光照。
不要添加新元素或文字。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/drawings.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "realistic_valley_gpt-image-2.png")输入图像:
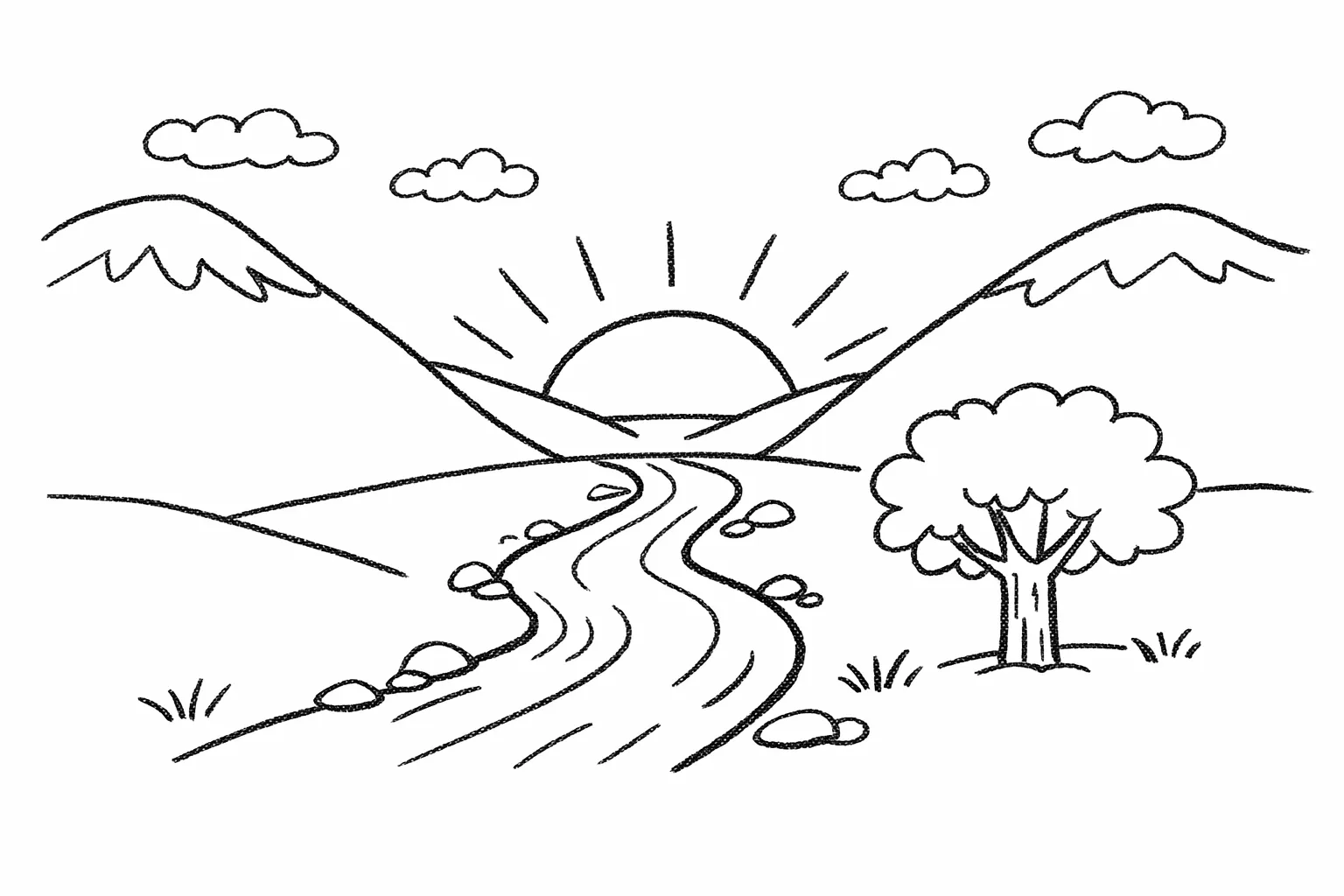
输出图像:

5.4 产品原型图(干净背景 + 标签完整性)
产品提取和原型图准备通常用于目录、商城和设计系统。成功取决于边缘质量(干净的轮廓、无光晕/边缘色散)和标签完整性(文字保持清晰不变)。对于 gpt-image-2,保持输出背景为不透明,如果需要最终透明素材,使用下游的去除背景步骤。如果你想要真实感而不重新设计风格,要求仅做轻微润色,并可选在纯色背景上添加微妙的接触阴影。
prompt = """
从输入图像中提取产品并将其放置在纯白色不透明背景上。
输出:居中的产品,清晰的轮廓,无光晕/边缘色散。
精确保持产品几何形状和标签可读性。
仅添加轻微润色和微妙的真实接触阴影。
不要重新设计产品风格;仅去除背景并轻微润色。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/shampoo.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
background="opaque",
)
save_image(result, "extract_product_gpt-image-2.png")输入图像:

输出图像:

带有真实图像内文字的营销创意素材非常适合快速广告概念设计,但排版需要明确的约束。将精确文案放在引号中,要求逐字渲染(无多余字符),并描述位置和字体样式。如果文字保真度不理想,保持提示词严格并迭代——小幅措辞/布局调整通常能改善可读性。
prompt = """
创建一个日落时分高速公路场景中洗发水的逼真广告牌原型。
广告牌文字(精确、逐字、无多余字符):
"Fresh and clean"
排版:粗体无衬线,高对比度,居中,干净的字距。
确保文字出现一次且完全可读。
无水印,无 Logo。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/shampoo.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "billboard_gpt-image-2.png")输入图像:
输出图像:

5.6 光照和天气变换
用于为照片重新设定不同的氛围、季节或时段变体(如晴天 → 阴天、白天 → 黄昏、晴天 → 雪天),同时保持场景构图不变。关键是仅更改环境条件——光照方向/质量、阴影、氛围、降水和地面湿度——同时保持身份、几何、摄像机角度和物体位置,使其仍然看起来是同一张原始照片。
prompt = """
让它看起来像是一个下雪的冬日傍晚。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/billboard_gpt-image-2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "billboard_winter_gpt-image-2.png")输出图像:

5.7 物体移除
场景中的人物合成适用于分镜、广告活动和面部/身份保持很重要的“假设”场景。通过指定扎实的摄影外观(自然光照、可信的细节、无电影级调色)来锚定真实感,并锁定关于主体的不可变内容。当可用时,更高的 input fidelity 有助于在较大的场景编辑中保持面部相似度。
prompt = """
移除男人手中的花。不要更改任何其他内容。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/man_with_blue_hat.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "man_with_no_flower_gpt-image-2.png")输入与输出图像:
| 原始输入 | 输出图像 |
|---|---|
 |  |
5.8 将人物融入场景
人物入场景合成(compositing)适用于分镜(storyboard)、广告投放以及需要保持面部/身份一致性的“假设”场景。通过指定接地气的摄影风格(自然光线、真实细节、无电影级调色)来锚定真实感,并明确锁定主体中不可改变的部分。当条件允许时,更高的 input fidelity 有助于在大幅修改场景时保持人物相似度。
prompt = """
生成一个高度逼真的动作场景:这个人正在逃离一只袭击营地的大型真实棕熊。图像应看起来像一张真实照片,而不是过度修饰或电影海报风格的画面。
她位于画面中心但背对镜头,穿着户外露营服装,脸上沾有泥土,衣服有破损。她表情明显恐惧但专注于逃跑,正逃离身后棕熊正在摧毁的营地。
营地位优胜美地国家公园,细节真实可信。时间是黄昏,自然光线,色彩真实。一切都应感觉真实、自然、不加修饰,仿佛是真实瞬间的捕捉。避免电影级灯光、戏剧化的调色或风格化构图。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/input_images/woman_in_museum.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "scene_gpt-image-2.png")输出图像:
from IPython.display import Image, display
display(Image(filename="../../images/output_images/scene_gpt-image-2.png", width=500))5.9 多图参考与合成
用于将多个输入中的元素组合成一张可信的图像——非常适合“把这个物体/人物放进那个场景”的工作流,无需重新生成所有内容。关键在于明确指定要移植什么(图2中的狗)、放到哪里(紧挨着图1中的女性)、以及什么必须保持不变(场景、背景、构图),同时匹配光线、透视、比例和阴影,使合成结果看起来像是在原始照片中自然拍摄的。
prompt = """
将第二张图中的狗放入第一张图的场景中,紧挨着那位女性,使用相同风格的光线、构图和背景。不要改变其他任何内容。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/test_woman.png", "rb"),
open("../../images/output_images/test_woman_2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "test_woman_with_dog_gpt-image-2.png")输入和输出图像:
| 原始输入 | 移除红色条纹 | 更换帽子颜色 |
|---|---|---|
 |  |  |
6. 其他高价值用例
6.1 室内设计“替换”(精确编辑)
用于在真实空间中可视化家具或装饰变更,无需重新渲染整个场景。目标是手术级真实感:替换单个物体,同时保持相机角度、光线、阴影和周围环境不变,使编辑结果看起来像一张真实照片而非重新设计。
prompt = """
在这张房间照片中,仅将白色椅子替换为木质椅子。
保持相机角度、房间照明、地面阴影和周围物品不变。
保持图像所有其他方面不变。
逼真的接触阴影(contact shadow)和织物纹理。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/kitchen.jpeg", "rb"),
],
prompt=prompt,
size="1536x1024",
quality="medium",
)
save_image(result, "kitchen-chairs_gpt-image-2.png")输入和输出图像:
| 输入图像 | 输出图像 |
|---|---|
 |  |
非常适合季节性营销概念和印刷预览。强调触觉真实感——纸张层次、纤维、折痕和柔和的影棚灯光——使结果看起来像是拍摄的真实实体产品,而非扁平的插图。
scene_description = (
"一个温馨的圣诞场景,一只旧毛绒泰迪熊坐在纪念品盒子里,"
"略显磨损的毛皮,柔软的缝补痕迹,放在一扇飘雪的窗户旁。"
"场景暗示孩子已经长大,但记忆犹存。"
)
short_copy = "圣诞快乐 — 有些记忆永不褪色。"
prompt = f"""
创建一张圣诞节日贺卡插图。
场景:
{scene_description}
氛围:
温暖、怀旧、柔和、充满情感。
风格:
高端节日贺卡摄影,柔和电影灯光,
真实纹理,浅景深,
精美散景光效,印刷级构图。
约束条件:
- 仅限原创作品
- 无商标
- 无水印
- 无 Logo
仅包含以下贺卡文字(原文照搬):
"{short_copy}"
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "christmas_holiday_card_teddy_gpt-image-2.png")输出图像:

6.3 收藏级可动人偶 / 毛绒钥匙扣(周边概念图)
用于早期周边产品构思和提案视觉化。聚焦高端产品摄影 cues(材质、包装、印刷清晰度),同时保持设计的原创性,不侵犯版权。适合快速测试多个角色或包装变体。
# ---- 输入 ----
character_description = (
"一架复古风格的玩具螺旋桨飞机,圆润的机翼,"
"前置旋转螺旋桨,略显磨损的油漆边缘,"
"经典童年比例,设计为怀旧节日收藏品"
)
short_copy = "圣诞回忆版"
# ---- 提示词 ----
prompt = f"""
创建一个收藏级可动人偶:{character_description},采用吸塑包装。
概念:
一款怀旧节日收藏品,灵感来自孩子们在冬假期间玩耍的简单玩具飞机。
唤起温暖、想象力和童年奇妙感。
风格:
高端玩具摄影,真实的塑料和金属漆面纹理,
影棚灯光,浅景深,
清晰的标签印刷,高端零售陈列。
约束条件:
- 仅限原创设计
- 无商标
- 无水印
- 无 Logo
仅包含以下包装文字(原文照搬):
"{short_copy}"
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "christmas_collectible_toy_airplane_gpt-image-2.png")输出图像:

6.4 角色一致性儿童绘本(多图工作流)
专为多页插画流水线设计,在这些场景中角色偏移是不可接受的。可复用的“角色锚定图”确保跨场景、姿势和页面的视觉连续性,同时允许环境和叙事的变化。
1️⃣ 角色锚定图 — 建立可复用的主角
目标:锁定角色的外观、比例、服装和基调。
# ---- 输入 ----
prompt = """
创建一张儿童绘本插画,介绍主角。
角色:
一个年轻的、故事书风格的小英雄,灵感来自小森林侠客,
穿着简单的绿色连帽束腰外衣,柔软的棕色靴子和一个小腰包。
角色表情善良,眼神温柔,性格勇敢而温暖。
携带一把小木弓,仅用于帮助他人,从不伤害。
主题:
角色保护和营救松鼠、小鸟和兔子等小森林动物。
风格:
儿童绘本插画,手绘水彩风格,
柔和轮廓线,温暖的大地色系,奇幻而友好。
适合图画书的比例(头部略大,表情丰富)。
约束条件:
- 原创角色(不使用受版权保护的角色)
- 无文字
- 无水印
- 简单森林背景以清晰展示角色
"""
# ---- 图像生成 ----
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "childrens_book_illustration_1_gpt-image-2.png")输出图像:

2️⃣ 故事延续 — 复用角色,推进叙事
目标:同一角色,新场景 + 新动作。角色外观必须保持不变。
# ---- 输入 ----
prompt = """
使用相同角色继续儿童绘本故事。
场景:
同一个年轻森林小英雄正在温柔地帮助一只受惊的松鼠
从冬季暴风雨后倒下的树中脱困。
角色跪在松鼠旁边,给予安抚。
角色一致性:
- 同样的绿色连帽束腰外衣
- 同样的面部特征、比例和色彩方案
- 同样温柔、英勇的性格
风格:
儿童绘本水彩插画,
柔和光线,雪地森林环境,
温暖、令人安心的氛围。
约束条件:
- 不要重新设计角色
- 无文字
- 无水印
"""
# ---- 图像生成 ----
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/output_images/childrens_book_illustration_1_gpt-image-2.png", "rb"), # 使用步骤1的图像
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "childrens_book_illustration_2_gpt-image-2.png")输出图像:

总结
本指南系统性地展示了如何使用 OpenAI gpt-image 系列模型构建生产级图像生成与编辑工作流,覆盖从模型选型到提示词工程再到实际用例的完整链路。
关键洞察
gpt-image-2 是当前最佳选择。 它在图像质量、编辑性能和分辨率灵活性上全面超越前代,input_fidelity 已被禁用(因为输出默认高保真),支持的分辨率范围远超其他模型(最大边长 < 3840px,总像素最高 830 万),且 low 质量设置在很多场景下已经够用——这意味着你可以在成本和速度上获得显著优势而不必牺牲太多质量。
提示词工程的核心不是“写得多”,而是“约束得准”。 指南反复强调一个模式:明确区分“应改变的部分”与“必须保持不变的部分”。每次编辑迭代都应重申不变量(身份、布局、光照、文字),以防止模型漂移。这比堆砌长提示词更有效。
迭代优于一次性完美。 从干净的基础提示词出发,用小幅度、单一变更的后续迭代逐步逼近目标(“让光照更暖”、“移除多余的树”),比试图一次性描述所有细节更容易调试且效果更好。
文字渲染已可用于生产。 gpt-image-2 在图像内文字渲染方面表现强劲,关键技巧是将字面文本放在引号或全大写中,逐字母拼出复杂词汇,并在小号/密集文字场景下使用 medium 或 high 质量。
多图输入开启了合成工作流。 通过索引引用多张输入图像(“图像 1:产品照片… 图像 2:风格参考…”),可以实现风格迁移、虚拟试穿、场景合成等高级工作流,配合 input_fidelity="high" 能在大幅修改场景时保持身份一致性。
世界知识是隐藏的杀手锏。 模型不仅能执行明确的指令,还能结合上下文推理。例如仅给定时间和地点(1969 年 8 月纽约贝塞尔),模型就能推断出伍德斯托克音乐节并生成符合历史的场景。这使得提示词可以更简洁,不必事无巨细。
一句话总结
把提示词当作规格说明书来写——结构清晰、约束明确、迭代逼近——gpt-image-2 就能成为你生产级图像工作流中可靠的执行引擎。

评论互动